
G検定の概要と学習方法

G検定の試験時間は120分で全て選択式の知識問題で自宅にてオンライン受験になります。受験費用は一般は12000円で学生は5000円になります。G検定はキーワードを覚えておくだけでは解けない問題も多く出題され、理解が重要視される検定です。問われていることは何か?を理解し、どう調べれば答えが見つかるかが分かるレベルに達すると、解ける問題が増えます。
ディープラーニング→数理統計や機械学習→人工知能
ディープラーニングの箇所が最も頻出で、人工知能になると頻度は少なくなります。
法律・倫理の問題は全体の約2割を占めると考えて問題集ベースの学習を行いましょう。
問題数は約220問(最近は200問以下)で120分で解くので1問あたり約30秒の計算です。調べてもわからなさそう、どう調べるか分からない問題は、後回しにしましょう。近年は出題数が減少傾向で、考えさせる問題が増えている様子です。また、法律系の出題が増えています。必要ならば下記の法律・倫理のテキストを参照しながらの学習をおすすめします。2025年3月8日の試験で無事に合格することができました。
僕は『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』などで合格を目指します。本書を選んだ理由は、教科書と問題集が一体になっていて、特に問題の解説が教科書のように詳しいという評判を知ったからです。本記事は本書などを勉強した際の学習記憶としての役割もあります。
G検定はインプットのみでは漠然とした理解になりやすいので、合格のためにはアウトプット用の教材が必須です。特に法律系の内容は出題数もそこそこある上で受験者にとって失点の原因になる範囲です。僕はこの分野を『ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト』を用いて理解確認を行います。全体のアウトプットは有名な黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』と類書『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いて得点力の底上げを行います。


これらの書籍には模試も付属しているので、本番本番前にネット上の模試も含めて十分な対策ができます。長い目で見るとG検定は複数書籍での対策が良いと考えます。
人工知能とは
人工知能の定義
人工知能の分類や代表名
人工知能やAIとは汎用型(人間のような)人工知能をイメージする人が多いが、近年では特化型人工知能の活躍が目立ちます。例えば囲碁に特化した人工知能AlphaGo(2016)などです。ある特定のタスクについて人間より秀でているものを作るのは可能だが、善悪の判断などの哲学的問題や、多角的に判断するタスクはまだ実現できていません。汎用型人工知能を強いAI、特化型人工知能を弱いAIとも言います。
Ponanzaは将棋AIで、StockfishはチェスAIです。ただし2017年以降にはelmo、Stockfishにも少しの学習で勝てるAlphaZeroというAIが開発されています。AIの強さや弱さはジョン・サールによって論文で提示されました。
人工知能の始まり
1956年のアメリカのダートマス大学にてダートマス会議という研究発表が行われた際のジョン・マッカーシーが、会議の提案書において初めて人工知能という言葉を使いました。ジョン・マッカーシーは研究分野の区分に対しても人工知能という研究分野にしようと同会議で命名しました。
ジョン・マッカーシーはダートマス会議の発起人です。アラン・チューリングは人工知能の概念の提唱者と言われています。
人工知能のレベル別の分類
人工知能の分類方法において、『エージェント アプローチ人工知能』にて示されている分類を学びます。レベル1はシンプルな制御工学で、一般的な電化製品に搭載される全ての振る舞いがあらかじめ決められているものです。レベル2は古典的な人工知能で、掃除ロボットなどの探索・推論、知識データを利用し、状況に応じて複雑な振る舞いを行います。レベル3は機械学習を取り入れた人工知能で、非常に多くのデータをもとに入力と出力の関係を学習したものです。検索エンジンや交通渋滞の予測などで用いられます。レベル4はディープラーニングを取り入れた人工知能です。レベル3で行っているものの中でもディープラーニングを用いているものです。画像認識、音声認識、機械翻訳などの従来コンピュータでは難しい分野での応用が盛んになっています。
特徴量とはデータの特徴を表す量で説明変数とも呼ばれます。プログラミングはレベル1から使われています。VBAはマイクロソフトオフィスにおけるプログラミング言語のことです。人間工学はプロダクトのUI/UX(ユーザーのサービスによる体験など)を主に考える学問です。ベイズ統計モデリングは計算量の多さから実務に応用されているとは言い難いですが、実務に応用できれば、予測の不確実性まで定量的に扱えるので盛んに研究が行われています。
AI効果
人工知能分野において、新しい技術が開発されてもその仕組みが浸透し原理がわかってしまうと、人工知能を単なる自動化であって人工知能ではないと考えてしまうことをAI効果といいます。
ELIZA効果とは、意識的にはわかっていても無意識的にコンピュータが人間と似た動機があると感じてしまう現象です。エライザはチャットボットの元祖「ELIZA」からきています。単におうむ返しの返答をしたり、関連することを投げかけたりするプログラムですが、エライザ自身が興味を持っていると感じてしまうところから命名されています。
人工知能の歴史
初期のコンピュータ
1946年ペンシルベニア大学で開発された汎用電子式コンピュータをエニアック(ENIAC)と言います。
electoronic numerical integrator and computerで電子計算機と命名されています。第二次世界大戦での暗号解読に軍資金がつぎ込まれ研究が行われました。チューリングマシンは、1930年代にアラン・チューリングが考えた自動計算機の理論のことです。自動計算機とは、機械に自動的に計算を行わせる理論です。エニグマ(ENIGMA)はナチス・ドイツが用いていた暗号機の名前です。エドサック(EDSAC)とは1949年に開発されたイギリスのコンピュータです。これは現代のコンピュータと相違ないものです。
初めての人工知能プログラム「ロジック・セオリスト」
ロジック・セオリストは初めての人工知能プログラムで、1956年のダートマス会議で、アレン・ニューウェルとハーバート・サイモンによってデモンストレーションされました。ロジック・セオリストは記号論理学において定理を証明するコンピュータプログラムです。プリンキピア・マテマティカという数学書に含まれる定理のうち73%を証明しました。ジョン・マッカーシーはダートマス会議の提案(1955年)において人工知能という言葉を生み出しました。論理表現では→やvは論理結合子と呼びます。ロジック・セオリストではこのように記号によって知識を階層的に表現します。ロジック・セオリストは証明すべき定理から逆算的に有効な推論をしていき、それを公理に到達するまで続けます。ロジック・セオリストにおいて、問題をヒューリスティックに解決します。
ヒューリスティックは、ある程度正解に近い解を見つけ出すための経験則や発見方法のことで、発見法とも呼ばれます。いつも正解するとは限らないが、概ね正解するだろいう直感的思考です。これと対極の考えがアルゴリズムです。
AIの歴史
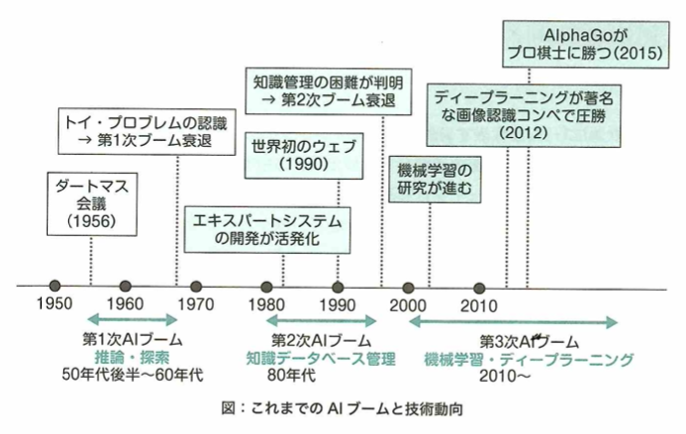
AIブームは何度も流行しては冬の時代を迎えてきました。第1次AIブームは推論と探索の時代です。1950年代末〜1960年ごろに流行し、トイプロブレムと呼ばれるような簡単な迷路の問題を解けるAIが開発され、話題になり流行しました。しかし複雑な問題には対応できず、1970年代後半から冬の時代に入りました。第2次AIブームは知識の時代で、1980年代頃から再度注目されました。当時専門家の知識を用いて質問に答えたり問題を解いたりするプログラムエキスパートシステムが話題になりましたが、データベースの管理の大変さや用途が限定的すぎることにより、また冬の時代に入りました。第3次AIブームは機械学習・特徴表現学習の時代、もしくはディープラーニングの時代と呼ばれ、再ブームになりました。2012年に物体の認識率を競うILSVRCという大会でディープラーニングを用いた技術が圧倒的な精度を出したことや、2016年に囲碁大戦用AI「AlphaGo」が人間のプロ囲碁士に勝利して注目を浴びてブームになりました。
シークレタリープロブレムは秘書問題で最適化の問題です。エキスパートシステムは2020年代の現代でもレコメンドシステムとして活用されています。
セマンティックネットワークは意味ネットワークともいい、知識をネットワーク構造で表したものです。ナレッジグラフは意味ネットワークの雑多な情報の中から半自動的に構成しているものです。少ないコストでできるメリットはあります。現在はGoogleが使用しているナレッジグラフのことを指します。エキスパートアドバイザーは自動売買取引ツールです。
Kaggleはデータサイエンティストをサポートする目的で設立した世界的なウェブプラットフォームです。SIGNATEは日本企業などが多く採用しています。AtCoderは競技プログラミングでどれだけ素早く問題をプログラミングで解けるかを競うコンテストです。
ディープラーニングを利用した成果
2012年にディープラーニングを利用したAlexNetというモデルが画像認識の大会で優勝し注目されました。以降はディープラーニングを用いた手法は様々な分野で成果を上げています。例えば次のような事例です。囲碁においてAlphaGoというモデルが人間のプロ棋士に勝利しました。1000クラスの画像分類においてPReLU-netというモデルが人間の分類精度を超えました。GPT-3という言語モデルが大学のレポート課題に合格しました。
ディープブルーはIBMが開発したチェス専用のスーパーコンピュータで1997年に人間のグランドマスターに勝利しました。ディープブルーはディープラーニングを使用してはいません。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
ルールベース機械翻訳→統計的機械翻訳→ニューラル機械翻訳の順番です。
語呂的にるとにで覚えます。
人工知能をめぐる動向と問題
探索・推論
探索木
1960年代頃の第1次AIブームの研究の1つで探索木の考えは現在も汎用的に使われています。1ステップずつ全ての場合分けを同時にメモリに保存しながら深くしていく探索方法を幅優先探索と言います。他にも行き止まりかゴールに着くまで一度探索し、行き止まりの場合は他の場合分けをまた最後まで探索する方法を深さ優先探索と言います。
幅優先探索=縦型探索、深さ優先探索=横型探索とも言います。
ハノイの塔
ハノイの塔を考えます。構造自体単純ですが、円板の枚数が増えるたびに、指数関数的に手間が増えます。これを組合せ爆発と呼びます。
バックギャモンとは世界最古のボードゲームと言われます。スライディングブロックパズルとは、ケースの中に収められたコマを動かして目的の配置にするパズルゲームです。
探索手法
ボードゲームの問題ではコストを考えます。コストはある局面の状態が自分にとってどの程度有利かを表すスコアと言い換えられます。自分のターンがスコアが最大になり、相手のターンでは自分のスコアが最小になる手を選ぶだろうと仮定し、探索する手法があります。これをMini-Max法と言います。
通常は相手は自分に意地悪な手を打ってくると考えます。Negaとつくと相手が相手自身のスコアが高くなるような手を取ると仮定します。あくまでも通常のMini-Max法では深さ優先探索で、スコアは自分のスコアという点に注意しましょう。
αβ法
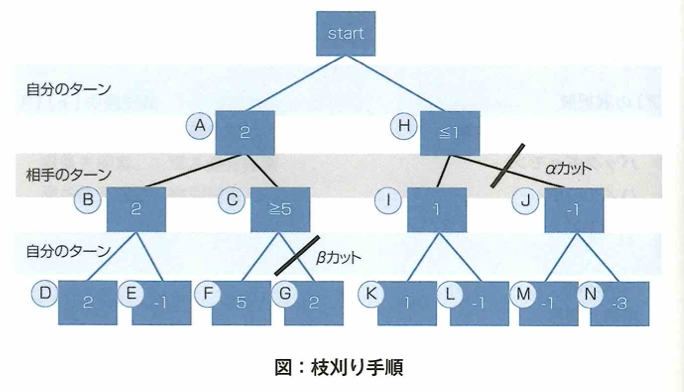
3手先読みのαβ法について深さ優先探索のMini-Max法で進めます。まず左の選択肢から探索します。DとEを探索しスコアが分かりました。この時は自分のターンなのでDを取ります。するとBは暫定2を取れるスコアだと判断します。次にFを探索し5とわかった時点で自分が5以上取れるとわかりました。それを相手も把握しているとすると、相手はスコアを低くする手を取りたいので、明らかにBとCではBを取るはずです。すると、Gは探索しても意味がないので、探索せずにすみます。このβカットにおいてβは現状2であり それにより大きい値が出ました。ここまでで、Aの手のスコアは2だとわかります。今度はH側の手を探索します。最初にKとLを探索すると、Kを選択するはずなので、Iの手は1だと判明しました。その時点で、仮に自分がHの手を選択すると、相手は相手は1以下の手を取れてしまうので、自分は確実にHでなくAの選択肢を取るべきです。よってJ以降のて探索する必要がなくなります。これをαカットと言います。αは2であり、それにより小さい値が出ました。
αβ法は条件が最も良い場合は、Mini-Max法の約2倍の速度で計算が終わるとされ、最も悪い場合でもMini-Max法と変わらないので、現在の探索アルゴリズムの中でも現役で使われているものです。
モンテカルロ法
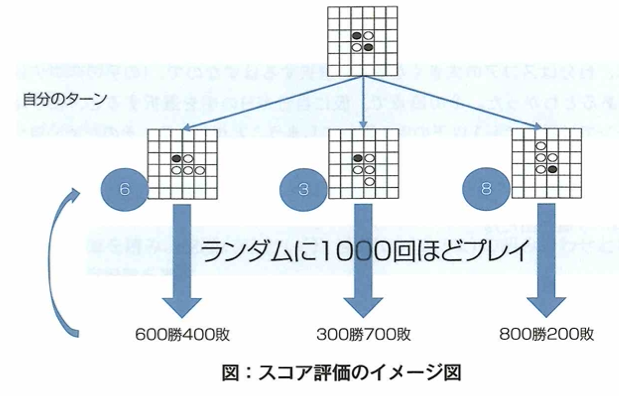
ボードゲームにおいてスコア評価では小さな囲碁でもアマチュア初段に勝てなかったので、スコア自体の評価がそもそもあまり正しくないと分かってきたので、 モンテカルロ法を導入しました。結果の正誤を許容しつつ、数多くのシミュレーションをして最良な手(最適スコア)を探索(評価)していくという手法です。それぞれの手を差した後でランダムに1000回プレイし、勝った数をそのままスコアに換算する考えです。
αβ法などはゲームの終盤で用います。モンテカルロ法では序盤中盤のスコアを暫定的に決めるようにしたら、小さい囲碁では人間のプロとほぼ同じレベルに達しました。ラスベガス法はモンテカルロ法の一種ですが結果が必ず1つに定まります。正しい結果を返せない場合は失敗を意味します。メトロポリス法はある状態から新しい状態をランダムに作った際に、それを棄却するか採択するかを考える方法です。
ロボットの自動計画
第1次AIブームの時に機械は四則演算や簡単な動作しかできなかったので、命令を簡単な処理に切り替える自動計画に焦点が置かれました。1971年にリチャード・ファイクスとニルス・ニクソンにより開発された前提条件、行動、結果の組み合わせで自動計画を記述できる言語をSTRIPSと言います。このような自動計画を端末の画面の中の小さな積み木の世界に存在する様々な物体を動かすことで完全に実現しようとする研究も行われました。実際にAIはこれらを実行して画面に反映できました。1970年にスタンフォード大学のテリー・ウィノグラードによって行われたこのプロジェクトをSHRDLUと言います。
自動計画は戦略や行動順序の具体化を言います。自動計画を行うものをプランナ(自動計画機)と呼びますが、初期状態、ゴール、アクションの集合の3つを入力して取ります。アクションの集合には、前提条件、行動、結果を与えます。
PDDL(planning domain definition language)はSTRIPSに触発されて開発された自動計画を記述する言語です。ASIMOはホンダが開発し、2000年に発表された世界初の二足歩行ロボットです。GPS(general problem solver)はハーバート・サイモンとアレン・ニューウェルが開発した汎用の問題解決のためのプログラムです。
SHRDLUは指示を実際に動作として端末の中で実行してくれるものです。第5世代コンピュータプロジェクトは経済産業省が1982年〜1992年まで行った国家プロジェクトです。シェーキーは移動能力のある世界初の汎用ロボットです。内部ではSTRIPSが使われています。Cycプロジェクトは一般常識をコンピュータに取り組もうというプロジェクトです。
知識表現
エキスパートシステム
第2次AIブームは知識表現の時代です。AIブームの火付けになった1つに1964年〜1966年にジョセフ・ワイゼンバウムによって開発されたELIZAがあります。対話ロボットの中でも決められたルールに従い会話するものを人工無脳と呼びます。ELIZAはオウム返しのような返答をしていましたが、これでも人間と対話していると感じる人は多かったです。
A.L.I.C.E.はELIZAに触発されて開発されました。その年に最も人間に近いと判定された会話ボットに授与されるローブナー賞の同省を過去三回受賞しています。AlexaはAmazonが開発したAIアシスタントの名前です。自由度が高く、新たなスキルセットを開発し公開することができるので、簡単に実務に導入できるツールとして有用です。SiriはApple社製品向けのAIアシスタントです。
昔の日本語のチャットボットは人工無脳と語られるシーンがありました。
チューリングテスト
ある対話式の機械に対して人間的か判定するテストをイギリスの数学者の名前からチューリングテストと言います。何かしらのデバイスを通してAIか人間かを判定者がどれだけ見分けられたかで定量化するテストです。合格基準の1つは判定者の30%以上が対話相手が人間かコンピュータか判断できないと判定することです。2014年にロシアのチャットボット「ユージーン・グーツマン」が13歳の少年という設定で初めて合格しました。
ローブナー賞とは毎年のチューリングテストで聴覚、視覚ともに人間と区別が付かない割合が30%以上ならば金賞で、聴覚のみ同様の評価ならば銀賞としています。2019年までに一度も金賞と銀賞を受賞したAIはおらず、最も人間らしい会話上の振る舞いを見せているコンピュータに送られる銅賞のみが毎年表彰され、賞金を出しています。
エキスパートシステム「Mycin」
1980年代にエキスパートシステムの世界的企業への導入によりAI研究が再度ブームになりました。このエキスパートプログラムの初期の例としてのプログラムはMycin(1970年代)です。これは伝染性の血液疾患を診断し、抗生物質を推奨するようにデザインされているプログラムです。
精度は65%と言われていおり、専門家の精度の80%より低いですが、専門家でない人の診断よりは使えるといったものでした。Dendralは未知の有機化合物を質量分析法で分析したデータと、有機化学の知識を用いて適合する化学構造を割り出すプログラムです。アルゴリズム取引とは価格の変動パターンなど大量の市場データの分析による短期間の市場予測に基づき、取引の執行まで自動的に行うプログラムです。2020年でもMeta Traderというソフトウェアがあり、アルゴリズム群に対してエキスパートアドバイザー(EA)という名前がついています。Macsymaは世界初の数式処理を行うプログラムです。これはMITのProjectの一環で行われたものです。
近年の対話システム
2009年4月にIBMが開発したワトソンはアメリカのクイズ番組「ジェパディ!」にチャレンジました。ワトソンは問題で問われた質問を理解し、文脈も含めて質問の趣旨を理解し、大量の情報の中から適切な解答を選択し回答します。IBMはこの技術を医療やコールセンターの顧客サービスなどに活用できるとして開発を進めています。IBMはこれを人工知能ではなく拡張機能(Augmented intelligence)という形でAIと名付けていて、人間の補佐をする形で機能するものとしています。現在は実用例がありますが、チャットボットによるフルオートな顧客サービスではなく、顧客サービスを行う人の手助けとして機能するものとして提供されています。
日本でも質問応答するAIとして東大合格を目指す東ロボくんというプロジェクトもありました。2011年頃から開発され最終的には進研模試で偏差値57.8をマークしマーチ合格レベルに達したと言われています。2016年に計画断念の報道がありましたが、2019年に研究者本人のツイートから研究は続けられ、2021年までの計画であると発言されました。
進化知能(AAdvanced intelligence)はAbeam Consultingが提供しているDX経営におけるデータ分析サービスです。絶対知能(Absolute intelligence)はDCコミックスのキャラクターです。抽象知能(Abstract intelligence)はアメリカの心理学での言葉です。質問に回答するタスクをQuestion Answering(質疑応答、Q A)と呼びます。open-domain question answeringは膨大なトピックの多数の文書(例えばウイキペディア)を用いて、解答を推定します。QAタスクでは質問に関連する適切な知識に基づいて解答を推定することは求められますが、open-domain question anseringは問題を解くために必要な知識源を規定しません。kaggleでもコンペが開催されています。
東ロボくんは単語の羅列などから確率の高いものを選んでいるだけで、質問の意図や意味は理解していませんでした。しかしマーチレベルに達したことで現代の高校生の読解力に危機感が生まれ新井先生の書籍『AI vs. 教科書が読めない子どもたち』が出版されました。

りんなは2015年に日本マイクロソフト社が開発した会話ボットです。ディープブルーはIBMが開発したチェスAI専用のスーパーコンピュータの名前です。Tayはマイクロソフトが開発した会話ボットです。2016年にツイッターbotとして公開されましたが、調整と称してTayアカウントが停止されました。理由は、複数のユーザーによってTayの会話能力が不適切に訓練され、間違った方向のコメントをするようになったからです。
機械学習
機械学習
レコメンドシステムとは、利用者にとって有用と思われる情報または商品などを選び、それらを利用者の目的に合わせた形で提示するシステムです。
スパムフィルタとは受信したメールが正規のメールかスパムメール(迷惑メール)か判断するシステムです。特定物体認識とは画像中にヨーロッパホラアナライオンのオスといった特定の物体が存在するかしないかを判断します。OCRとは活字や手書き文字の画像データから文字列に変換する文字認識機能のことですが、古典籍のくずし字は認識が難解であるため機械学習を使用した手法は研究が進みつつあります。
一般物体認識は実世界の画像に対して、計算機がその中に含まれる物体を山、ライオン、ラーメンなどの一般的な名称で認識することです。
人工知能における問題
フレーム問題
1969年にジョン・マッカーシーとペトリック・ヘイズによって提唱され、哲学者ダニエル・でネットによりその具体的な思考実験が提案された問題で、ロボットは課題解決の枠にとらわれて、その枠の外を想像するのが難しいという問題をフレーム問題と言います。
The whole puddingという問題をダニエル・デネットは思考実験で考えました。シンボルグラウンディング問題は言葉と、それが示す映像や姿、質感などを機械は結びつけて捉えることができないのではないかという問題です。
中国語の部屋
チューリングテストは機械が人間かどうかを判定するテストとして1950年にアラン・チューリングによって提案されました。1980年に哲学者ジョン・サールによって発表された論文内で、チューリングテストの結果は何の指標にもならないという批判がされました。その論文内で発表された思考実験の名を中国語の部屋と言います。
テセウスの船はパラドックスの1つです。ある物体の構成要素が全て書き換えられた時、それは同一であるといえるかという問題です。哲学的ゾンビとは物理的には人間と同じ構造だが、意識がないものを指します。メアリーの部屋は全てが白黒の部屋で過ごしてきたメアリーは知識として色のついた世界を知っているが、突如色が見える世界に行った場合、新しく学ぶことがあるかという思考実験です。
シンボルグラウンディング問題
認知科学社スティーブン・ハルナッドにより議論されたもので、記号とその対象がいかにして結びつくかの問題をシンボルグラウンディング問題と言います。
身体性の問題とは、1980年代にロボット研究者のロドニー・ブルックスが提唱した「コンピュータには身体がないので、物体の概念までは捉えられないのではないか」という問題です。彼はその後ルンバで有名にあるiRobot社の創業者です。ハルナッドはシンボルグラウンディング問題の提唱者の名前です。
自然言語処理の歴史
機械が自動的に言語を翻訳できないかという研究は第1次AIブームの時からすでに始まっていました。そういった翻訳を機械翻訳と言います。機械翻訳の手法は歴史に即して大きく3分割できます。
1つは1954年にジョージタウン大学でIBMが主体で研究を始めてから1970年ごろまで行っていたルールベース機械翻訳(PBMT)です。これは各言語の文法を人手で入力していき、変換していったが、限界があることと、言語自体が非常に柔軟であったので使いにくく上手くいきませんでした。
2つは1990年代にIBMが提唱したIBMモデルから取り入れ始めた統計的機械翻訳(SMT)です。この手法は現在の機械学習と類似しており、ある言語とその対訳を学習させてモデルとします。これにより以前の問題である人手でのルール追加による莫大なコストはかからなくなったが、それでも精度には問題がありました。
3つは2014年に発表されたニューラルネットワークを用いたニューラル機械翻訳(NMT)です。これにより精度が向上しました。データが溜まるほど精度が向上するので、現在はこの方法が主流です。しかし上の2つの手法にも利点があるので、一部の機能(構文解析など)は今も使われています。
統計的機械翻訳とニューラル機械翻訳は、コーパスベース方式などでまとめられます。形態素とは文をルールに基づいて区切った際の最小単位です。その形態素の品詞や活用形などを判別していく作業を形態素解析と言います。Mecabは形態素解析用パッケージです。構文解析やエンティティ分析という文章に既知のエンティティがあるかどうかを調べ、その単語に関する情報を分析するものなどがあります。現在は自動的に行ってくれるAPI(ある機能の転用を簡単に行えるようにしたもの)も豊富なので、APIを活用したプロダクトも続々と出てきています。
特徴量エンジニアリング
機械学習では、学習器(機械学習モデル)に与えるデータを説明変数(特徴量)と言います。特徴量について工夫する手法である特徴量エンジニアリングについて具体例をいくつか述べます。取引のログから一人当たりの平均取引時間を算出し、新たな特徴量としました。物体の画像データから輪郭情報を取り出し、新たな特徴量としました。文章データから単語の出現頻度を計算し、新たな特徴量としました。
特徴量エンジニアリングとは、取得済みデータから、データを加工し抽出することです。そのため、カメラの画質が悪いのでカメラを変えて取得したデータを特徴量としました。という主張はデータの取得前の話であり、既存のデータを加工することではないので不適切です。
特徴表現学習
予測したい数値に関わるデータを集めることや、データから特徴量を人手で加工・抽出することは機械学習で重要です。しかしディープラーニングを活用すると、後者の過程で特徴量を自動的に得る学習が可能です。こういった特徴量の加工・抽出も学習器にさせることを特徴表現学習と呼びます。
特徴量の加工・抽出まで学習器が行うことを特徴表現学習または表現学習と言います。自然言語学習において機械は単語をそのまま扱うのは難しく、単語をベクトルに変換する必要があります。このようにしてできた表現を分散表現と言います。適切な分散表現が得られれば、機械は文章の意図をつかみやすくなります。適切な分散表現とは、各単語に対して適切な意味を表現するベクトルが得られていることを意味します。この分散学習の仕方と、文章読解を同時に学習することで、適切な表現を得られます。これを表現学習と言いいます。単語の分散表現は他のタスクにも転用でき有用です。
半教師あり学習は、学習の途中までは答え付きのデータで学習させ、そこからは答えのないデータ学習を行います。強化学習は報酬を得るために最適な行動が何かを行動しながら探索する学習のことです。教師なし学習は答えのないデータに対して、データのグループ分けをする学習です。
シンギュラリティ
2005年レイ・カーツワイルが出版した書籍で2045年には人間が自分自身よりも賢い人工知能を作ることにより、技術的特異点シンギュラリティが起きると予言しました。1.0の知能が1.1の知能を生み出すことができるならば、1.1も同様のことができうるはずで、そうなると技術的な進化が爆発的に起きるということを予見したものでした。
エキスパートシステムとは専門家の知識を入れ込みその意思決定能力を誰もが使える形にするもので、知識ベースと推論エンジンにより構成されます。
意味ネットワークとは知識を線で結びその関係性を表したもので、現在でもAIプロダクトの解釈性を高めるために使われます。
オントロジーとは意味ネットワークなどで用いられる知識の結びつけ方の規則です。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
幅>深さで計算量の多さが変わります。幅優先の方は最短距離が必ず見つかりますが、深さ優先では最短距離が見つかるとは限りません。プランニングは、SHRDLU(積み木の世界)とSTRIPS(前提条件→行動→結果)が備えています。イライザはエキスパートシステムではありません。
セマンティックウェブはウェブサイトの情報リソースに意味を持たせ、コンピュータによってより高度な意味処理を行う技術です。ウェブマイニングはウェブデータを解析して知識を得ることです。LODはコンピュータ処理に適したデータを公開・共有する技術です。Cycプロジェクトは全ての一般常識をコンピュータに入れるプロジェクトです。
オントロジーは用語や概念を体系的に整理するものです。ライトウェイトオントロジー(ウェブマイニング、LOD)は正確性<実用性です。ヘビーウェイトオントロジー(Cycプロジェクト)は知識をどのように記述すべきか哲学的に考えるものです。人間が行うのでコストが高いです。
2012年に優勝したのはAlexNetで畳み込みニューラルネットワークを用いています。2014年に優勝したのはGoogLeNetでInceptionモジュールを採用しています。VGGは16層です。2015年に優勝したのはResNetでスキップ結合を用いています。2017年に優勝したのはSeNetでAttentionモデルを用います。MobileNetはDepthwise Separable Convolutionを採用し、DenseNetはResNetを改良したものでDenseブロックを採用しています。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
覚えるべき用語は、意味ネットワーク(ラベルをつけられた概念が互いの関係性を示す矢印で繋いだ記号体系)、オントロジー(知識概念の体系的な記述を目指す学術分野)
第1次AIブームは複雑な問題が解けない欠点、第2次AIブームは知識獲得のボトルネックが欠点、CASNETは緑内障の診断支援を行うエキスパートシステムです。トイ・プロブレムはルールが決まっている問題を解けても複雑な問題には対応できない問題、モラベックのパラドックスは高度な推論より感覚運動スキルの方が多くの計算資源を要する主張、Cycプロジェクトは現代版バベルの塔と言われます。身体性AIとは物理的な身体があり、環境との相互作用をおこなって初めて知能の構築が可能という考え方です。マルチモーダルAIとは人間の五感のように複数種類の情報を総合的に扱うAIです。
弱いAIは特化型AIとも言われます。ELIZAはエキスパートシステムではありません。人間と対話ができるソフトウェアです。チューリングテストは知能の存在に関する実験です。この反論として中国語の部屋を提唱しました。
意味ネットワークにおいて、下図をおさえます。
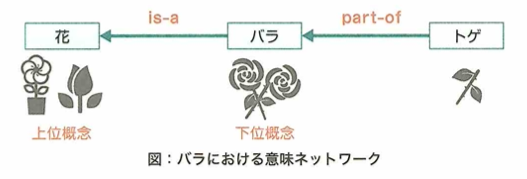
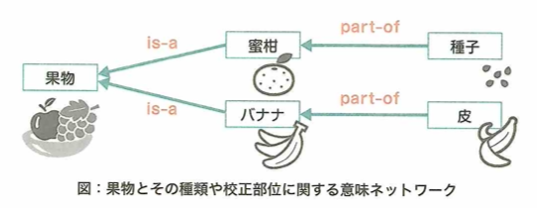
オントロジーとは、共通のルールで論理的に記述することで、知識を共有しやすくするための方法論です。
知識ベース(ナレッジベース)は第2次AIブームにおいて登場しました。知識の整備と保守には高いコストがかかりましたが、コンピュータの処理能力や知識を保存するデータベースそのものは問題ではありませんでした。第3次AIブームでディープラーニングが登場し、データから自動的に特徴を抽出し、画像認識などで高精度を出せるようになりました。
WatsonはIBMが発表したライトウェイトオントロジーを応用した質問応答ができるAIです。決定木はレベル3のAIで機械学習の1つです。顔認識はレベル4のAIでディープラーニングを活用しています。掃除ロボットはレベル2のAIで特定の分野において状況に応じた振る舞いができます。ATMには探索や推論の要素が含まれません。
フレーム問題とは、AIは有限な情報処理能力しか持たないので、現実世界に起こりうる問題の全てにはには対処しきれないという問題です。トイ・プロブレムとは、AIは明確なルールが定まっている問題が解けても、要件が曖昧で複雑な実世界の問題には対応できないという問題です。
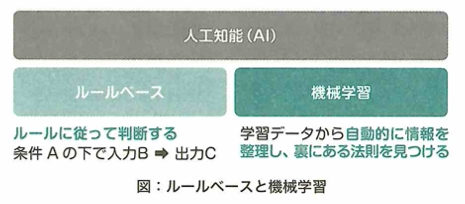
人工知能はルールベースと機械学習の2タイプがあります。
数理統計・機械学習の具体的手法
代表的な手法
学習の種類
教師あり学習の手法の例は正解データが未知であるサンプルに対しその値を予測するモデルを得ることであり、教師なし学習の例はデータに共通する特徴的な構造や法則を見つけることを目的とすることで、強化学習の手法の例はエージェントが自身の報酬を最大化するような行動指針を獲得することです。
教師あり学習について、正解データは目的変数、その他の変数は説明変数もしくは特徴量と言います。教師なし学習はクラスタリングなどで用います。強化学習は、正解を与える代わりに将来の報酬や利益を最大化するように特定の状況下における行動を学習する仕組みです。ボードゲームなどで目覚ましい活躍をしています。これらはアルゴリズムや手法ではなく、機械学習のタスクの種別の枠組みです。
教師あり学習
教師あり学習は大きく分類問題と回帰問題に分けられます。分類問題では正解データが質的変数(カテゴリ)であり、回帰問題では量的変数(連続値)となります。
分類問題は疾患の有無や性別などのカテゴリーで、回帰問題では年収や気温などの連続値です。分類問題は2値問題と、ラベルが3種類以上である多値分類に区分けできます。多値問題は、個々の観測がただ1つのクラスに属するマルチクラス分類と、同時に複数のクラスに属しうるマルチラベル分類に分けられます。画像の中で特定の物体の領域を予測するタスクや、レコメンデーションにおいて順位をつけた出力を行うタスクも、教師あり学習のアプローチになります。
教師なし学習
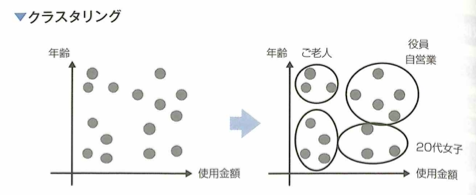
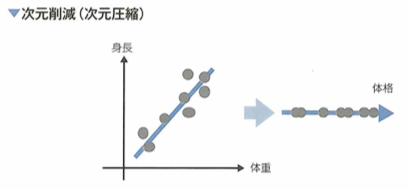
教師なし学習は、正解ラベルがないデータを学習し、データに共通する構造や法則を見つけ出すことを目的とします。その例はクラスタリングや次元削減(または次元圧縮)、確率変数の密度推定などが知られます。データを複数のグループにまとめるクラスタリングでは、グループ数の決定や、観測同士の似ている程度(類似度)の設計などが問題となる時があります。データをより少ない変数で要約しようとする次元削減では、いくつかの変数を用いれば十分か、より解釈しやすい変数の設計などが問題となる場合があります。
クラスタリングにおいて、数百のばらつき(標準偏差など)がある年収と数十程度のばらつきがある年齢が元の変数にある場合、それらをあらかじめ揃えるような前処理、または類似度の設計が重要です。
次元削減の時も、クラスタリングのときと同様に前処理が重要となる他に、重要な情報まで削ぎ落としてはいけないので、圧縮後の次元をいくつにするかが問題となります。例えば主成分分析では、スクリー基準やカイザー基準などが知られています。
異常な観測と正常な観測を分類する異常検知も教師なし学習として解かれることがあります。生存時間解析は、個体が死亡・故障するまでの時間を目的変数とした教師あり学習です。
強化学習
機械学習は、教師あり学習、教師なし学習、強化学習があります。教師あり学習は分類問題と回帰問題に分けられ、入力と出力の対応を学習するものです。教師なし学習は、入力のみのデータから、その背後にある構造を明らかにすることが目的です。代表的な教師なし学習のアルゴリズムには、k-means法や主成分分析があります。
過学習はモデルが特定のデータセットに過剰に適合してしまう状態です。深層学習は、ディープラーニングのことです。オンライン学習は新しくデータが追加されるたびに、そのデータのみを用いてモデルを逐次的に更新する仕組みです。
k-menas法はクラスタリングの代表的な手法の1つです。クラスタリングは正解がない状況下で分類問題を解くことに相当します。
機械学習の代表的な手法は教師あり学習、教師なし学習、強化学習です。しかし半教師あり学習、自己教師あり学習、距離学習などもあります。自己教師あり学習は、ラベルのないデータから機械的にラベルを作って学習する手法です。距離学習は、同じクラスのサンプル間の距離を小さくしながら、異なるクラスのサンプル間の距離を大きくするように学習する手法です。これらのような手法がどれが最適か?について研究することもディープラーニングの1つのテーマです。
教師あり学習の代表的な手法
線形回帰
線形回帰は、説明変数と目的変数の関係に直線や超平面を当てはめ、予測・説明する教師あり学習の手法です。実施は推定された回帰係数が意味のある数字かどうか、偏回帰係数が0を帰無仮説とした統計的仮説検定で判断されます。統計的仮説検定とは、観測された標本を用いて、その母集団の性質を判断する手続きです。多くの場合、ある特定の確率分布を帰無仮説として仮定し、その分布にデータが従っていないかどうか判断します。
正則化
正則化とは、学習の際にペナルティとなる項を追加することで過学習を防ぐことです。
サポートベクターマシンにおけるカーネルトリックの一部は、データを高次元に写像することで線形分離を可能にします。正規化とは平均と標準偏差をそれぞれ0と1にすることです。対数化、Box-Cox化、Yeo-Johnson変換などは、特徴量を標準正規分布に従うように変換しデータの分布を調整することです。
正則化は(最小化したい新たな目的関数)=(通常の目的関数)+(正則化項)で導入されます。Ridge回帰やLasso回帰が有名ですが、ロジスティック回帰やサポートベクターマシン、勾配ブースティング、ニューラルネットワークなど、多様なモデルに適用されることがあります。
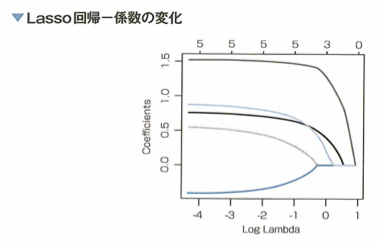
正則化を線形回帰モデルに適用した例(L1とL2正則化)
過学習を防ぐためのテクニックに正規化がありますが、線形回帰に対してL1正則化を適用した方法をLasso回帰、L2正則化を適用した方法をRidge回帰と言います。どちらも正規化パラメータを大きくするに従い、Lasso回帰では回帰係数をスパースに(ちょうど0となるものが多くなるように)推定する効果が、Ridge回帰では回帰係数を0に近づける効果が強くなります。解は解析的に書けます。
ロジスティック回帰
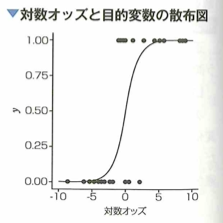
ロジスティック回帰は、分類問題を解くための手法で、一般化線形モデルの一種です。マーケティングにおける適用としては、見込み顧客が購買行動に至る確率を予測できます。一般化線形モデルの1つであり、分類問題へ適用できるのは、ある事象が起きる確率pと起きない確率1ーpの比の対数、つまり対数オッズを線形回帰するためです。数式で表すと対数オッズは、log(p/(1-p))です。
回帰と名前がありますが、分類問題に適用されるモデルです。オッズという言葉は賭け事などでの賭け金がp/(1-p)倍になるような数値というオッズと同じものです。ただし手数料などが取られない場合です。ロジスティックシグモイド関数では、閾値を定め、回帰後の予測値がその値を上回ると1に、下回ると0と予測します。
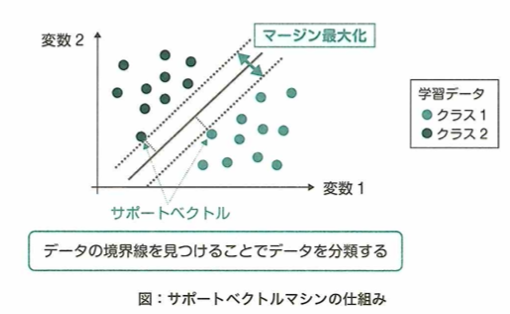
サポートベクターマシン
サポートベクターマシン(SVM)という学習アルゴリズムは、識別境界近傍に位置する学習データサポートベクトルと識別境界との距離であるマージンを最大化するように線形の識別境界を構築し、2クラス分類を行います。データが直線や平面に分類できない時は、データを高次元特徴空間へ写像し、線形分離可能にした状態で判別を行います。写像に伴う計算量の増加を低く抑えるテクニックはカーネルトリックと言われます。
サポートベクターマシン(SVM)は明らかに所属クラスが分かる観測ではなく、判別境界の付近にある判断の難しい観測に着目する分類モデルです。このとき、判別境界に最も近い観測はサポートベクトルと呼ばれます。SVMでは高次元空間に写像することで線形判別を可能にする工夫が行われます。
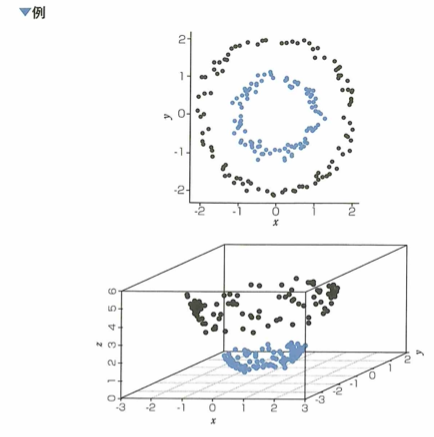
線形分離可能にする高次元への写像を探すことは難しいですが、カーネル関数という関数を使うことで写像を具体的に探すことなく、高次元空間で学習を行うことができます。その際に計算量の少ない都合の良いカーネル関数を用いることをカーネルトリックと言います。SVMやガウス過程などで用いるカーネル関数には様々なものが存在します。線形カーネル、RBFカーネル、多項式カーネル、周期的カーネルなどです。多層のニューラルネットワークに対応するカーネル関数も存在します。サポートベクトルを用いる回帰モデルに、サポートベクトル回帰(SVR)があります。
カーネルトリックとは、カーネル関数を使うことで、高次元の特徴空間における内積を行わず、入力空間でのカーネルの計算に落とし込むアプローチです。行っていることに対して計算量が大幅に少なくて済みます。
決定木
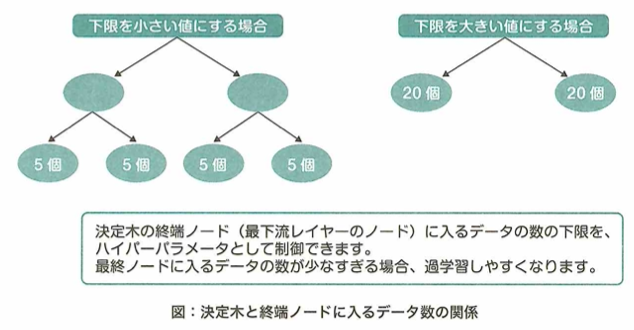
決定木は、木構造を用いて分類や回帰を行う学習アルゴリズムです。木構造の2つに枝分かれする節では、条件分岐が行われ、先端の葉にたどり着くと、その葉に対応する値が出力・予測値となります。木を成長させていくと最終的には1つの葉に1つのデータが対応してしまうので、過学習が起きます。過学習を避けるために木の深さなどに注意する必要があります。
根ノードから葉ノードへ辿り着くと、数値やクラスなどの値が出力されます。それぞれの分岐は1つの特徴量に関するif文で表されるため、得られたモデルが解釈しやすいのがポイントです。木の幅や深さを増やすと(条件分岐を多くすれば)学習データに対して過剰に学習してしまうので、それらを制御する工夫が必要です。
時系列モデル
時系列モデルとは、時刻が進むにつれ、値が刻々と変化していくデータです。時系列データおよび時系列モデルに関しては、次の内容が大事です。時系列分析で重要な概念は、定常性という概念です。定常性とは、確率的な変動があるものの、時点に依存せず平均と自己共分散が一定である性質で、時系列分析する上で扱いやすいです。時系列データは、トレンド、季節成分(周期性)、ホワイトノイズという基本構造からなるものが多いです。ホワイトノイズとは、平均0、分散一定、かつ自己相関が0であって、何の情報も含まないノイズのことです。ARモデルとは、自己回帰モデルです。ある時刻データが1つ前の値を用いて予測式を作る場合、y_t=ay_(t-1)+e_tなどとできます。自己回帰という名の通り、自分自身の過去の値を用いて予測します。VARモデル(多変量自己回帰モデル)とは、ARモデルを多変量に拡張したモデルです。VARモデルの係数推定には何期分までのラグを取るのかを決定する必要があります。
定常性が満たされている時系列モデルでは分散も一定となります。分散は自己共分散のラグを0としたものであり、自己共分散一定の条件に含まれます。定常性を満たす代表例がホワイトノイズで期待値と分散がそれぞれ、0とσの2乗で、任意のj次の自己共分散が0となります。定常ではない時系列データのうち代表的なものにランダムウォークがあります。分散が時間と共に拡大していくという特徴を持ちます。
VARモデルを構成する各方程式は、自分自身のラグとモデルに含まれる全ての方程式のラグを説明変数とします。定数項を除く場合、4変数でラグが2であれば8個の変数でラグが4であれば32の説明変数が必要となり、自由度が著しく低下します。長いラグを取ると説明変数が増えるので、予測の信頼度が低下します。
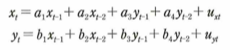
擬似相関
仮に相関係数の値が高く出た場合、相関関係が実際にある可能性が高いものは、降水量と傘の売上です。
アイスの消費量と熱中症患者の数は、気温という第3の要素により変化します。年収と血圧、および算数の成績と身長は、年齢という第3の要素によって擬似相関の関係があります。
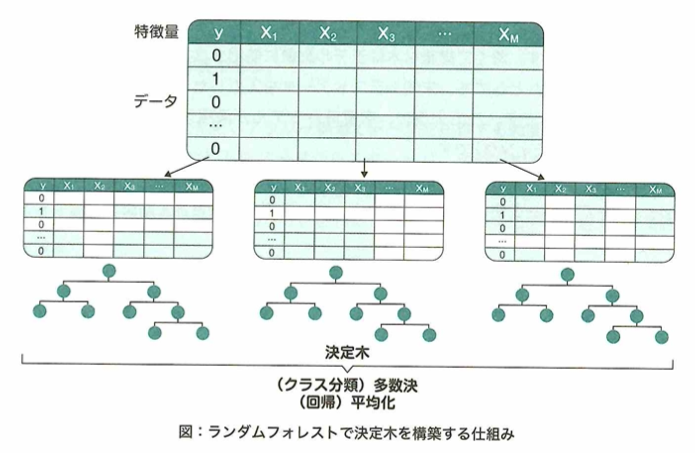
ランダムフォレスト
ランダムフォレストは、複数の決定木による出力の多数決・平均を行うことで分離・回帰を行います。弱学習器を複数合わせて汎化性能を高めることをアンサンブル学習と言います。ランダムフォレストには、木の数を多くしても過学習しにくいメリットがあります。
バギングと呼ばれるアンサンブルの方法が使われ、並列にそれぞれの決定木が学習されます。そのため計算機の環境によっては簡単に高速化できるメリットがあります。決定木をそれぞれ並列に学習することにより、決定木の数が増えても精度が悪くなることはありません。そのため木の本数ではなく、それぞれの決定木のパラメータ(木の深さや葉に入る最小のサンプル数など)を制御することで汎化性能を高めます。このメリットはランダムフォレストの大きな特徴で、ビジネスにおいてもベンチマークとなるモデルとして利用されます。
アンサンブル学習は、バギング、ブースティング、スタッキングの3種類があります。
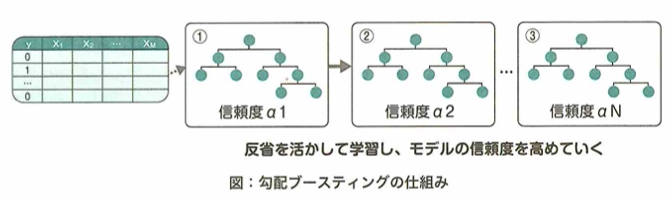
勾配ブースティング
勾配ブースティングとは、特にテーブルデータの教師あり学習において、幅広いデータセットで高い精度を出すモデルです。アンサンブル学習であるブースティングの1つであり、弱い学習器を次々と逐次的に学習するモデルです。2つ目以降の弱学習器は、それまでに学習したモデルによる予測とデータセットの違いを考慮して学習が行われます。弱学習器としては、さまざまなモデルを使用できます。
ランダムフォレストが、弱学習器に決定木を使用する具体的なモデルであることに対し、勾配ブースティングはあくまでもブースティングを実行するための1つの手法です。そのため、弱学習器には具体的なモデルを仮定せず、決定木の他に、線形回帰モデルなどが利用されることもあります。勾配ブースティングの弱学習器に決定木を使用したものは勾配ブースティング木と呼ばれ、特にテーブルデータの教師あり学習で人気のあるモデルです。
GBDTライブラリ
勾配ブースティングの弱学習器に決定木を利用した勾配ブースティング木(GBDT)は、その高い精度と使いやすさから、さまざまなライブラリが開発されてきました。代表的なGBDTのライブラリとして、catboost、lightgbm、xgboostがあります。
adaboostは勾配ブースティングと同様のブースティングの1手法で、GBDTを実装したライブラリではありません。xgboostはDMLC社により開発されたオープンソースのGBDTライブラリです。既存のPythonライブラリに比べて計算が速く、コンペティションで高い精度を誇ったことにより人気が出ています。lightbmはマイクロソフトにより開発されたライブラリで、xgboostよりさらに速い計算速度と、モデルの軽さから人気があります。catboostはロシアの検索エンジンを運営するYandex社により開発されたライブラリで、カテゴリ(質的変数)の扱いなどに工夫があります。適切に学習されたパラメータが設置されていれば、これらのライブラリで精度に大きく差が出ることは稀です。
バギング
アンサンブル学習の1手法であるバギング(bagging)はboostrap aggregatingの訳語です。バギングでは、データセットに多様性を持たせ、それぞれの学習した弱学習器をまとめることで汎化性能を高めます。個々のデータセットは、もとの学習データから同じ大きさのデータを重複ありサンプリングすることにより作られます。この作業はbootstrapやbootstrap samplingと呼ばれ、バギングの名称の由来となっています。
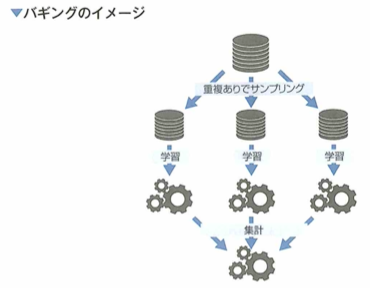
重複ありで同じ大きさのサンプルを得る作業はブートストラップやブートストラップサンプリングと呼ばれ、サンプルを擬似的な母集団とみなす統計的手法です。
ブースティング
アンサンブル学習の1手法であるブースティングは、同じ種類の弱学習器を逐次的に(直列的に)作成する方法です。それまでの学習によるモデルを修正する形で、1つずつモデルを学習させます。そのため弱学習器の数が増えすぎると過学習してしまうという特徴があります。ブースティングを使用したモデルとしては、adaboostや勾配ブースティング木があります。
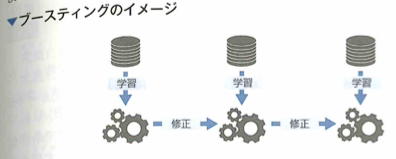
モデルをよくモニタリングし、適切な弱学習器の数を決定しないといけないことに注意が必要です。
スタッキング
アンサンブル学習の1手法であるスタッキングは、あるモデルによる予測値を新たなモデルの特徴量(メタ特徴量)とする手法です。このとき、もとの特徴量で学習したモデルを1層目のモデル、メタ特徴量で学習したモデルを2層目のモデル、とすると、その階層は3階層になることがあります。foldに分割せずに学習データ全体を用いて学習したモデルで、そのデータに対して予測してしまうと、あらかじめ正解を知ってしまうため過学習が起きてしまいます。よって実際にはデータを分割して使うことが多いです。
データセット1で学習したモデルで、データセット2を予測し、新たなメタ特徴量としますが、学習に使用したデータに対してそのままメタ特徴量を使ってはいけないことに注意が必要です。勾配ブースティング木や線形回帰などを始めとし、多様性の観点から各層でさまざまなモデルが使用されることが普通なので、最終的な解釈性が非常に低くなるという特徴があります。
ベイズの定理
ベイズの定理であるP(A|B)={P(B|A)P(A)}/P(B)において事象A、Bをそれぞれ原因、結果とします。左辺は結果が分かっているもとでの原因の確率なので事後確率で、右辺のP(A)は結果が分かる前のAの確率なので事前確率で、P(B|A)は結果に対する原因のもっともらしさを表すので尤度と呼ばれます。
尤度について、これは原因やパラメータを仮定した(具体的なパラメータで条件付けした)ときのもっともらしさとして解釈できます。
尤度
確率モデルにおいて、想定するパラメータが具体的な値をとる場合に、観測されたデータが起こり得る確率のことを尤度と言います。例えばコインを3回投げて3回とも表のとき、表が出る確率をp=0.4とすると、尤度は0.064となります。
尤度をもとにすることで、パラメータのもっともらしさをモデルで比較することができます。尤度が最も大きくなるようにパラメータを推定する方法を最尤推定と言います。上記の問題文の事象を最尤推定するとp=1と推定されることからも分かるように、データが少ない場合やモデルが複雑な場合の最尤推定では過学習に注意する必要があります。
最尤推定値
最尤推定もしくは最尤法とは、データからモデルのパラメータを推定する方法の1つです。表の出る確率がpのコインがあり、コインを4回投げたところ、出た面は順に、(表、表、裏、表)であったとき、pの最尤推定値は0.75です。
本問では尤度はp^3-p^4になります。これを最大にするpを求めると答えが求まります。
教師なし学習の代表的な手法
k-means法
クラスタリングの1手法としてk-means法が知られています。これは非階層的なクラスタリングであり、あらかじめクラスタ数kを指定する必要があります。各観測が所属するクラスタは1つであり、複数のクラスタを跨ぐことのないハードなクラスタリングです。
次の問題のようなものを階層的クラスタリングと言います。観測が各クラスタに属する割合や確率を出力し、どのクラスタに属するかを決めてしまわない方法をソフトクラスタリングと言います。所属クラスタが複数考えられる状況など、曖昧さを維持したい場合に有用です。
階層的クラスタリング
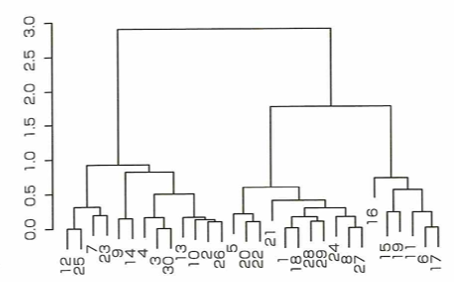
縦軸はクラスタがまとめられる距離、横軸は各観測のラベルとします。縦軸に対し閾値を定めることで、実際に複数のクラスタに分けられます。閾値を2.5とすると、クラスタ数は2となり、閾値を1.5とすると、クラスタ数は3となります。
レコメンデーションアルゴリズム
ウェブサイト上のコンテンツレコメンデーションの手法には、新着順や人気順にランキングを表示するものをはじめとし、様々なものがあります。これらに付随するコールドスタート問題に対する説明は次が大事です。
コールドスタート問題とは、レコメンデーションに必要なデータが十分に集まっていない段階では、望まれる成果が上がらないような問題のことです。コールドスタート問題の解決策として、売れ筋の商品を提示するなどの、個別のユーザーやアイテムに依存しない方法でレコメンドするといった対策や、ユーザーの行動をできるだけ早くレコメンドに反映できるシステムを強化することなどが考えられます。ビッグデータの活用による解決も考えられます。たとえばあるユーザーが「九州 お寺」「九州 天気 週末」と検索をしているデータから、ユーザーが週末に九州の寺へ参拝に行こうとしているかもしれないという仮説が立てられます。一方で、過去に同じような検索をしたユーザーの予約情報や検索履歴等のビッグデータから作成したレコメンドモデルを用いることで、「九州の寺院巡りツアー」のように、ニーズにある程度合致したプランを提供できると考えられます。
レコメンデーションとして何を推薦するかを決定する仕組みをフィルタリングと言います。
コンテンツベースフィルタリングでは対象アイテムの特徴から、ユーザーの嗜好の傾向にあった特徴を持つアイテムをレコメンドします。この方法では、推薦対象の属性が分かれば推薦が可能という点で、コールドスタート問題には対応しやすいです。協調ベースフィルタリングではユーザーの過去の行動履歴(購入・チェック履歴)からアイテムや利用者間の類似度を計算し、類似したアイテムをレコメンドする方法です。この方法では、レコメンドにおいて他顧客のデータを利用することから、コンテンツベースフィルタリングよりも、意外性のある推薦が行われるのがメリットの1つです。課題としては、新規のアイテムに対してレコメンドができないことです。サービスの利用がほとんどない利用者に対して、嗜好にあったレコメンドを出すことが難しいことが挙げられます。
コールドスタートの具体的な解決策の1つとしてハイブリッドモデル(協調ベースとコンテンツベースのフィルタリングを組み合わせたモデル)を利用します。例えばイギリスのLyst社が開発したLight FMがあります。ユーザーとアイテムのメタ情報(ユーザーの属性、取り扱う商品のジャンル、キーワードなど)を活用し、コールドスタート問題を解決することができます。高精度で動作が軽くPythonのコードセットが準備されていることなどが評価されています。
主成分分析
主成分分析とは、相関を持つたくさんの変数から、全体のばらつき(分散)を最も良く表す変数を合成する手法です。主成分は元の変数の数だけ合成されますが、上位の主成分のみ取り出すことで次元削減を行うことができます。また、主成分同士の相関は0となります。
第2主成分は第1主成分の方向と直交するように与えられます。以降も同様です。
主成分の概念
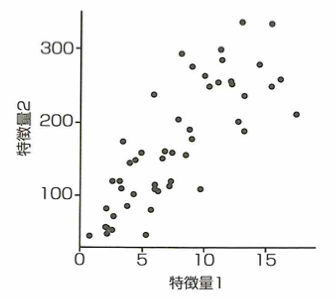
この図のデータに対して主成分分析を行った結果、第1主成分と第2主成分の軸を描いた図として適切な選択肢を選ぶと、以下になります。
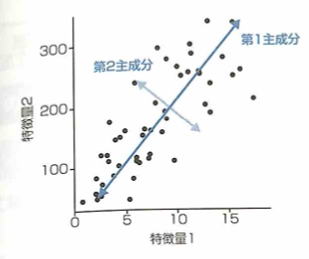
寄与率(主成分がばらつきを説明する大きさ、主成分に対応する固有値の大きさ)の大きい順に第1主成分、第2主成分・・・とします。
特異値分解
特異値分解(singular value decomposition)SVDは行列を分解する方法の1つで、ある行列を特異ベクトルと特異値に分解します。特異値分解ではある行列AをA=UDVT(Tは転置)と表します。これについて以下の内容が大事です。
行列を分解することで、成分の配列という表現からは明らかではない行列の機能的性質について情報を得ることができます。実行列はすべて特異値分解可能です。また特異値分解の方が、固有値分解よりも多くの行列に対して適用できます。
行列Dは正方行列でなくても特異値分解を適用できます。Dが正方行列である必要があるのは、固有値分解です。特異値分解を用いることで、Dが正方行列でない場合にも、固有値分解と同じようなメリットを享受できます。Dの対角成分は行列Aの特異値と呼ばれ、Uの列は左特異ベクトル、Vの列は右特異ベクトルと呼ばれます。
データの視覚化
多次元尺度構成法(multi-dimentional svaling)MDSについて述べると、多次元尺度構成法は、計量的多次元尺度構成法と非計量的多次元尺度構成法に大別でき、前者は量的データを、後者は質的データを扱います。
多次元尺度構成法は、対象間の類似度をできるだけ保つように低次元空間で表す手法です。主に心理学の分野で発展してきた手法です。心理学では、さまざまな要因が絡み合った現象を取り扱うことが多いので、錯綜したデータの処理に利用されてきました。
手法の評価
データの扱い
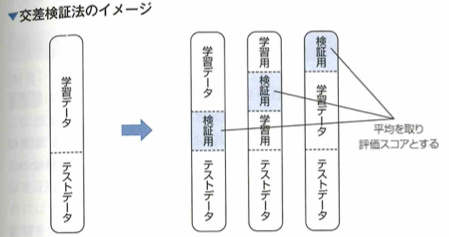
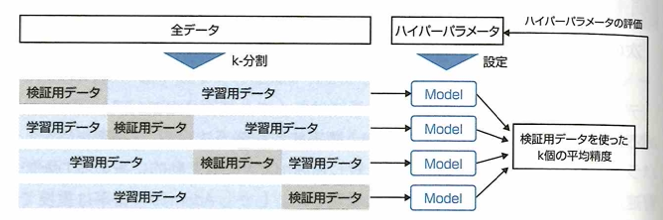
学習データだけでなく、未知のデータに対しても正しく予測できる能力のことを汎化性能と言います。モデルの汎化性能を測るために、交差検証法が利用されることがあります。
再代入では精度が高く出ても過学習している恐れがあります。モデルの汎化性能を測るための解決策としては、学習データとは別の評価用データを用いることがあります。評価用データの用意の仕方としては、ホールドアウト法や、交差検証法があります。
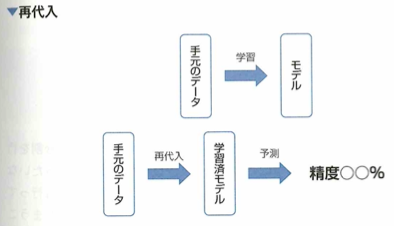
ホールドアウト法
モデルの性能を測る検証用データの用意の仕方として、ホールドアウト法が知られています。これは学習データを2分割し、一方を学習に、もう片方を評価に用いる手法で、次の内容が欠点となります。学習用データが減ります。パラメータの変更などを何度も行うことにより、評価用データに過学習する恐れがあります。データの分割の仕方によって結果が変わります。
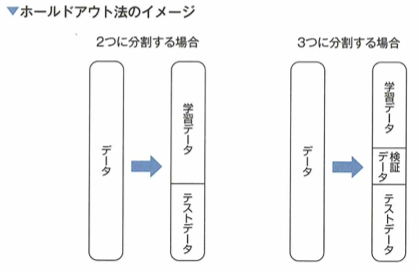
交差検証法
モデルの未知のデータに対する当てはまりを測る方法に、交差検証法(cross validation)があります。これは手元のデータを複数のブロック(fold)に分割し、そのうちの1つをテスト用に使い、残りを学習データとすることを、テスト用データを入れ替えて全てに対して行う方法です。ブロックの数をサンプルの大きさとしたものは1つ抜き(Leave one out)法と呼ばれます。
交差検証法でもホールドアウト法と同様に、分割の仕方で結果が変わるなど、何度もパラメータチューニングや特徴量の推敲を行うと過学習してしまう恐れがあります。
評価指標
回帰
モデルの精度を測る評価指標はさまざまなものが存在します。回帰問題で代表的な評価指標としてRMSEが知られています。これはMSEの平方根を取ったものです。
分類
2クラスの分類問題として、モデルによる予測クラスと真のクラスを分割表としてまとめられます。

この表は混同行列と呼ばれ、( )内を埋めると次のようになります。
真陽性(TP) 偽陽性(FP)=α過誤(第一種過誤)
偽陰性(FN)=β過誤(第二種過誤) 真陰性(TN)
真偽については、予想が当たっていれば真、外れていれば偽
陽陰については、予測が正であれば陽性、負であれば陰性です。
データリンケージとはデータ漏洩と言われます。予測の時点では利用することができない情報を含むデータを用いて、モデルを構築した際に発生する問題です。例えば2000~2019年のデータがあり2018年の売上を予想したいとき、2018年以外のデータを用いることができますが、未来を予想したいとき、そのさらに先の未来のデータを活用することは不可能のため、利用できないモデルが出来上がってしまいます。
二値分類の評価指標
二値分類を行ったところ、混同行列が得られました。このモデルを評価するために、ある指標を用いて精度を測りました。結果(30+45)/100=0.75が評価値として得られました。この評価指標は正確率(accuracy)です。

正例。負例の数によらず正しく当てられた割合を正確率と言います。大半を占めるクラスに対する予測精度の影響を受けるため、少数クラスを正しく予測する場合や、一部のクラスにサンプルの大半が集中ている場合には注意が必要です。
二値分類の評価指標(適合率と再現率)
二値分類における混同行列において、評価指標として適合率や再現率などが知られています。適合率はTP/(TP+FP)、再現率はTP/(TP+FN)です。ある疾患(正例)を検出する問題を考えたとき、適合率は陽性判定のうち実際に疾患を有する人の割合で、再現率は疾患を有する人のうち正しく陽性判定できた割合を示す指標です。

正例(疾患を有する)と予測することを陽性判定と言います。適合率と再現率の間には、一方を高めればもう一方が下がってしまうトレードオフの関係があります。その中庸を取るために、両者の調和平均F値が評価指標として用いられることがあります。
F値
2クラスの分離問題における、モデルの予測精度を測る指標にはさまざまなものが存在します。代表的なものには正解率や適合率、再現率、F値などがあります。正解率は実際に予測が当たっているデータの割合で、適合率は、真と予測したデータのうち実際に真であるものの割合です。F値は、トレードオフの関係にある適合率と再現率の調和平均として定義されます。
陽性を多く出す検査では、FNが減るため再現率が高くなります。しかしFPが増えるため適合率が低くなります。
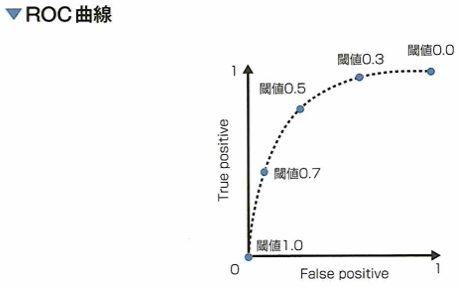
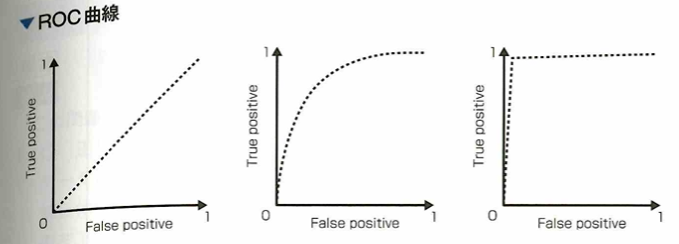
ROC曲線とAUC
二値分類において、モデルの性能を評価するためにROC(receiver operating characteristic)曲線を描くことがあります。この曲線は判別の閾値を動かした時の真陽性率と偽陽性率の関係をプロットしたものです。ここでは横軸に偽陽性率、縦軸に真陽性率をとるものとします。ROC曲線を書いたあとは、曲線の下側の面積であるAUC(area under the curve)でモデルの評価を行うことができます。モデルがランダムな予測をする場合、ROC曲線は直線になり、AUCは0.5となります。モデルの性能が上がるほど曲線は左上に張り出し、AUCは1に近づきます。
各クラスに属する予測確率が与えられたとき、予測確率が1なら正例と判断すれば良いですが。0.9、0.8、0.7となっていったときに、どこからを正例として分類するかは問題によって異なります。予測確率のどこからを正例に分類するか、の閾値をさまざまに変化させたとき、偽陽性率と真陽性率の推移をプロットしたものをROC曲線と言います。
解釈性をもたらす研究
ブラックボックスな(解釈性の低い)モデルを解釈する手法の1つとして、2016年にLundberc ahd Leeにより発表された、強力ゲーム理論を応用しているSHAPが近年注目されています。SHAPは1つのデータにおける予測値の解釈について使えるだけでなく、予測値と変数の関係を見ることができるなど、ミクロな解釈からマクロな解釈まで網羅的に行える有用な解釈手法です。この方法はすでにPythonによるパッケージが開発されており、実務でも多く活用されています。
SHAPは決定木系のアルゴリズムや、ニューラルネットワークの派生アルゴリズムでも多様に活用できます。LIMEは同様の技術でSHAPの前によく使われていました。Anchors、influenceも解釈に関する1つのアプローチです。LIME(local interpretable model-agnostic explanations)はニューラルネットワークやランダムフォレストなどの複雑なモデルを、より平易で解釈しやすい線形モデルやルールモデルに近似し、居所的説明を生成する方法です。ただし、モデル全体を線形回帰モデルで近似することはできないので、居所的なサンプリングにより線形回帰モデルを生成します。
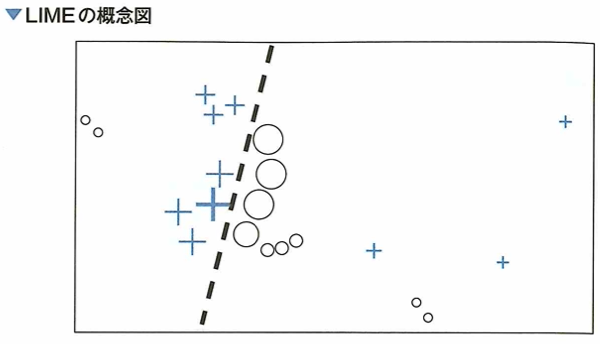
青で塗られる部分は、分類モデルが正(+)と分類する範囲で、白い部分はモデルが負(○)と分類する範囲です。記号の大きさはサンプリングされたインスタンスと興味のあるインスタンス間の近接度による重みづけの効果です。太い線だけでは完全に分類できないことがわかります。LIMEでは太字の+の周辺のデータに対してサンプリングを行い、解釈可能なモデルを学習させ、元の分類モデルを近似します。
モデル自体の評価
一般に、AIモデルの変数・パラメータが増え、複雑になるにつれて、与えられたデータをうまく説明できるようになります(ある入力データから、予測対象である値やクラスを高精度に推定できることです)しかし、そのようなモデルは不必要に複雑である場合があり、その結果過学習に陥ることもあります。モデルの汎化誤差の構成要素は、バイアスとバリアンス、データに含まれる本質的なノイズです。機械学習モデルの学習の目標は、バイアスの2乗、バリアンス、データに含まれる本質的なノイズの3種類の誤差の和である汎化誤差を最小化することです。オッカムの剃刀とは、ある事柄を説明するには、必要以上に多くを仮定すべきではないという考えです。統計学や機械学習の分野では、モデルの複雑さ、変数の多さとデータへの適合度とのバランスを取るために、オッカムの剃刀的な発想を利用します。AIC(akaike information criterion)赤池情報量基準は、AIC=ー2×(最大対数尤度)+2×(パラメータ数)です。パラメータが増えること自体がペナルティとなります。
バイアスとは予測値の平均と正解値とのずれで、学習データとモデルとの予測の誤差を表現します。バリアンスは、予測値相対のばらつき具合です。モデルを複雑にするとバイアスは減少しますが、バリアンスは増加します。これを過学習と言います。AICを用いることは、誤差が同じ程度ならパラメータ数の少ないモデルを選ぶべきというオッカムの剃刀の考えが強調されます。
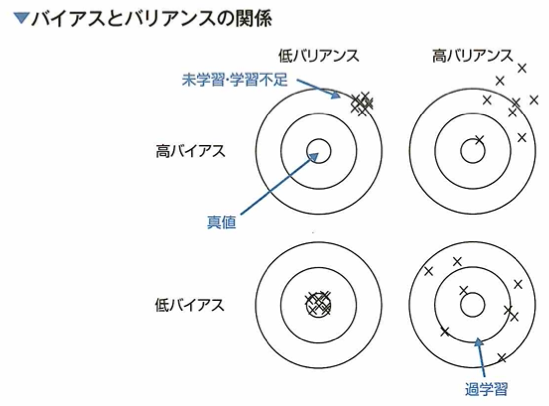
この説明はとてもわかりやすいです。本書『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』はこのような気付きが多く、素晴らしい1冊です。

以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
統計学での説明変数は機械学習では特徴量(教師データを説明できる変数群)と呼ばれ、統計学での目的変数を機械学習では教師やラベルと言います。データから特徴量を作るプロセスを特徴抽出と言います。作成した特徴量からその一部を抽出することを特徴量選択と言います。ロジスティック関数の損失関数を交差エントロピーと言います。
弱学習器とは決定木のような個々のモデルです。パディングとは畳み込みニューラルネットワークで使用します。画像の周囲に0などの定数を埋めて補完する方法です。ブートストラップサンプリングとは全体の一部データを使用します。バギングとはアンサンブル学習で用います。弱学習器で並列で学習を行い、多数決(分類タスク)か平均(回帰タスク)で出力を決定します。対してブースティングは弱学習器を逐次的に学習し予測値を修正していきます。AdaboostやXGBoostがあります。後者は勾配ブースティングを使用します。
白色化は特徴量の相関を除いてから標準化することです。教師あり学習はランダムフォレストやSVMで、教師なし学習はk -means法(非階層)やPCAです。
クラスタリングは教師なし学習です。階層型はウォード法(事前にクラスター数が不要)で非階層型はk-means法(事前にクラスター数が必要)です。
協調フィルタリングは複数のユーザーの過去の情報などから推薦しますが、コールドスタート問題があります。コンテンツベースフィルタリングは商品の特徴を利用します。
強化学習ではエージェントが環境と相互作用しながら最適な環境を学習します。エージェントは報酬を最大化するように学習します。これを方策と言います。その際に割引率を時刻に応じて考えます。そのため後になるほど価値が低くなります。報酬とは将来にわたる累積報酬のことで、これを価値と言います。価値には状態価値関数と行動価値関数があります。行動価値関数のことを価値関数ということもあります。これをQ値として最大化することを考えます。その手法としてQ学習やSARSAがあります。
多腕バンディット問題は複数のスロットマシンから決められた回数内で当たりを多く引くことを目指します。提案と活用で解くアルゴリズムにはε-greedy方策(確率εで提案し、残りの確率で活用)とUCB方策があります。提案とは、未知の情報以外の情報を獲得するために行う行動で、活用とは、既知の情報を利用して最大の報酬を得る行動です。
方策勾配法は、方策をあるパラメータを使用した関数で表し、累積報酬を最大化するようパラメータを学習することで、方策を学習するということです。これはロボット制御などに向いています。REINFORCEは方策勾配法の計算を行うアルゴリズムでAlphaGoにも採用されています。他にはActor-Criticがあります。これは方策勾配法と価値関数のアプローチの組み合わせです。つまりActor(行動器)とCritic(評価器)から構成されます。またこの応用がA3Cです。
性能評価は教師あり学習です。検証データとはハイパーパラメータを評価前に最適化するため訓練データを分割したものです。例えばホールドアウト法は訓練データとテストデータを用います。k -分割交差検証法は、データをk個に分けて1個をテストデータで残りのk -1個を訓練データとすることをk回繰り返した結果の平均を考える方法です。データリーケージとは訓練データにテストデータの一部が混入することです。未学習とは訓練誤差と汎化誤差が共に大きい状態で、バイアスが高いつまりモデルの表現力が小さい回帰のような時におきます。過学習とは訓練誤差が小さく汎化誤差が大きい状態で、バリアンスが高いつまりモデルの表現力が高くディープニューラルネットワークのような時におきます。
回帰タスクではMSE(平均二乗誤差)のルートをとったRMSE(平均平方二乗誤差)、そして外れ値の影響を受けにくいMAE(平均絶対誤差)などがあります。
混同行列では、縦軸が正解(陽性・陰性)で横軸が予測(陽性・陰性)で、(1、1)(1、2)(2、1)(2、2)成分は順に、TP(真陽性)、FN(偽り陰性)、FP(偽陽性)、TN(真陰性)です。適合率は確信性(precision)の高い予測のみを陽性としたいので、TP/(TP+FP)となります。再現率は実際の陽性のデータの見逃しを防ぎたい(recall)のでTP/(TP+FN)となります。F値はPとRの調和平均です。またAUCでは横軸にFPR(FP/(FP+FN))、縦軸にTPR=再現率をとって考えます。
適合率はPの形、再現率はRの形で覚えます。
オッカムの剃刀はある事柄の説明をするために必要以上に多くを仮定すべきでないことです。ノーフリーランチ定理はあるゆる問題において優れた汎化性能を持つモデルは存在しない定理です。AICはモデルの煩雑さと予測性能のバランスを考えたもので、-2logL+2k(Lはモデル尤度、kはパラメータ数)です。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
教師なし学習にはクラスタリングと次元削減があります。
過学習は、特徴量の数が多すぎる場合、学習データが不足している場合、モデルが複雑な場合、特徴量間の相関が強い場合に起こりやすいです。データリーケージは精度検証に使用するテストデータの一部が訓練データに混じってしまい汎化性能を正しく評価できなくなることです。機械学習は、損失関数(モデルの予測出力と正解の誤差を表す関数)を最小化するように学習します。Elastic Netはラッソ回帰とリッジ回帰を組み合わせた手法です。
線形回帰は説明変数と定数項の線型結合で表します。カーネル法とはSVMで線形分離不可能なデータを非線形な関数(カーネル関数)で高次元空間に写像し、線形な決定境界(超平面)を求めることです。カーネルトリックはSVMで高速に計算できるように計算量を削減する技術です。ソフトマージンはSVMで新しいデータに対する汎用性を高めるために、誤分類をある程度許容する工夫です。非階層クラスタリングはデータ量が多い場合にも対応しやすいです。K近傍法(KNN)は学習データを特徴量で張られたベクトル空間上にプロットしておき、未知のデータから距離が近い順に任意のデータをK個取得し、多数決でデータが属するクラスを推定する距離ベースのアルゴリズムです。Kの値はユーザが決め、予測結果に影響されます。特徴量の数が多い場合は、次元の呪いが起きやすいので、高次元データには不向きです。ナイーブベイズ手法は確率論のベイズの定理をもとにした分類モデルで、文章の分類問題に利用されます。特徴量同士が無相関という単純化仮定を置くため、単語の出現頻度にのみ注目し、単語同士の関連性は考えません。t -SNEは高次元データを2次元または3次元に変換して可視化する次元削減のアルゴリズムです。
混同行列はクラス分類の精度評価の基準となる行列表現です。縦軸と横軸はそれぞれ正解クラスと予測クラスです。

適合率はPで始まる単語なので、式の分母はどちらもPが入ると覚えましょう。
回帰問題の精度検証では、MSE、RMSE、MAEなどが用いられます。ハイパーパラメータはユーザが指定するパラメータで、モデルの複雑さや学習の進行を制御することで、過学習を防ぎます。訓練データから一定量のバリデーションデータを取り出し、それを用いてハイパーパラメータの調整を行います。グリッドサーチとはユーザが複数種類のハイパーパラメータの値の候補を指定し、その中からベスト精度となる組み合わせを総当たりで探す方法です。ランダムサーチとは、あらかじめユーザが指定した範囲の中で、ランダムにハイパーパラメータを組み合わせて学習させ、最善の組み合わせを探す方法です。
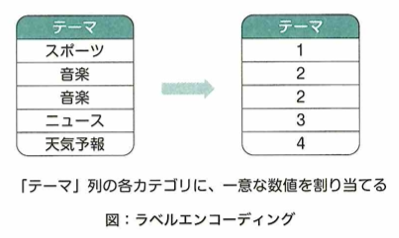
ラベルエンコーディングは1つのカテゴリが1つの数値に対応するようにマッピングを行うことで文字列をダミー数値に変更することです。One -Hotエンコーディングはカテゴリ毎に列を作り、各行について、1つの列項目だけを1、それ以外を0とします。不均衡データについて、特定のクラスに対し、他のクラスのデータ数が、極端に多い、または少ないデータです。そのまま機械学習のモデルの学習に使うと汎化性能が低下するので、事前に適切な処理が必要です。アンダーサンプリングはデータ数の多いクラスに属するデータを少なめにサンプリングします。オーバーサンプリングはデータ数の少ないクラスに属するデータを多めにサンプリングします。SMOTE(Synthetic Minority Oversampling Technique)はオーバーサンプリングの代表的な手法の1つで、少ない方のクラスのデータを、値が近いデータから予測してデータ量を増やします。
多クラス分類(マルチクラス分類)はクラスが3つ以上の分類問題です。マーケティングでの顧客セグメンテーションは教師なし学習のクラスタリングです。最初から来店客の種類や属性は知られていないので、教師ラベルを作ることが困難です。二値分類の例は、「洋服の種類を正解ラベルとする画像データ」、「診断結果を正解ラベルとするカルテのデータ」「赤字か赤字でないか」「来月退会するか、来月退会しないか」とします。回帰の例は、感情スコアなどです。半教師あり学習は、汎化性能が低くなります。また、精度も低くなります。教師あり学習と比べて特に計算コストが低いわけではありません。むしろ2段階で考えるのでコストは高くなります。
次文予測は自然言語処理の技術を用います。PCAでは相関が少ない合成変数に変換をすることでデータの次元圧縮を行います。異常検知は教師なし学習(教師あり学習より学習データの準備コストは低いです)の1例です。なぜなら異常の過去事例が少ないので、学習のための教師データを用意することが難しいからです。
クラスタリングは、マーケティング分野における顧客の分類、広告ターゲティング、レコメンド機能の最適化などを行います。
過学習は、モデルを訓練データに過剰に合わせ混みすぎてしまうことにより生じます。
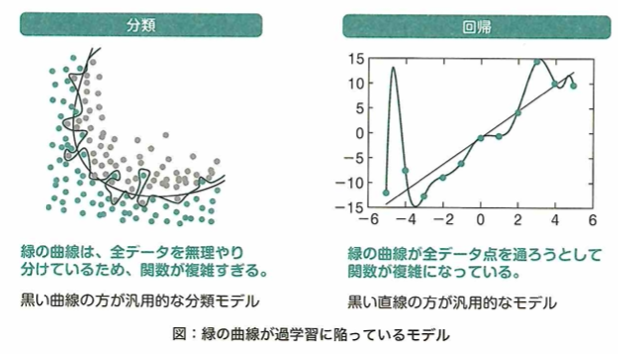
特徴量の数が多すぎると同時に学習データが不足している場合、過学習が起きやすいです。
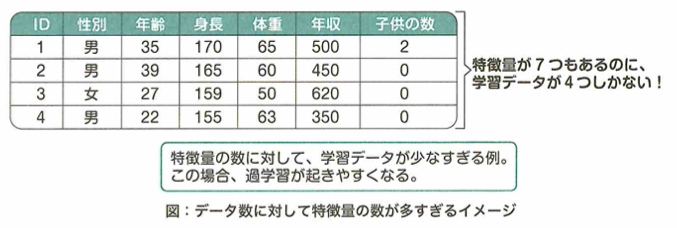
ハイパーパラメータを調整することで、モデルの複雑さを抑えることができます。また正則化を実施することで、モデルの動きに制限を課し、モデルが複雑になるのを防止します。バイアスとバリアンスはトレードオフの関係にあります。ばらつきの多いデータに複雑で高次元のモデルを当てはめるとバイアスは減るものの、バリアンスが高くなります。推定値もばらつきが大きく、未知データについて汎用性が低いです。一方で、全体としてばらつきが抑えられているモデルではバイアスは高くなりますが、バリアンスは小さくなります。このモデルは未知データに対してもそこそこ正確な推定値を出力できるので汎用性が高まります。バギングはバリアンスを小さくする効果があります。
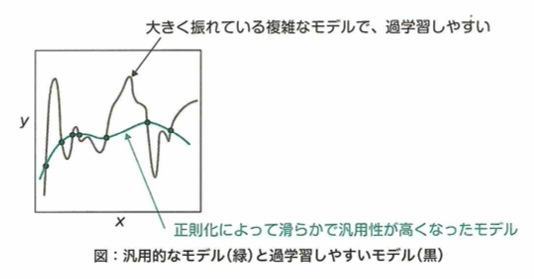
ニューラルネットワークの訓練において、ミニバッチ毎にデータの正規化を行う操作は、バッチ正規化といい、過学習を抑える効果があります。
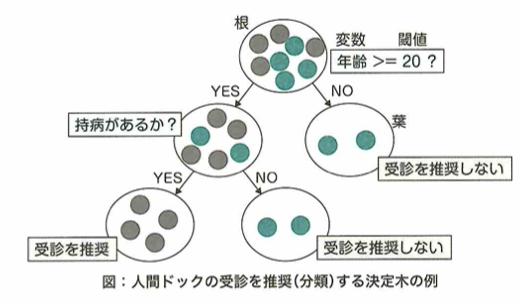
決定木がデータを分割する上で、情報の利得(分割によって得られるデータの明確さを表す指標)が最大になるように特徴量と閾値の組み合わせを最適化します。データ分割の際に1つのノードの中からデータクラスの不純度(誤って分類される割合)が低くなれば利得の値が大きくなります。エントロピーは情報の乱雑さ(正しく分類されていない程度)を表し、決定木の学習において最小化する指標の1つです。決定木の終端ノード(葉)に割り当てるデータの数(の下限)は手動で設定します。これはハイパーパラメータの1つです。デフォルトの値は1です。
アンダーフィッティングは過学習(オーバーフィッティング)の逆でモデルの学習不足を表します。誤差逆伝播はニューラルネットワークの学習の特徴の1つで損失関数の情報を出力層から入力層に向かって逆方向に伝播しながらパラメータの更新を行います。
各々の決定木を構築するとき、データと特徴量の両方をランダムにサンプリングします。データ(行方向)のサンプリングには重複を許す抽出を行うブートストラップ法を用います。特徴量(列方向)については全特徴量がM個とすると、通常は1本の木に√M個程度を抽出して使用します。ランダムフォレストでは訓練データから一部分を抽出し、少しずつ異なる決定木を多数構築し、それぞれの結果の多数決を採用します。
勾配ブースティングでは各弱学習器の予測誤差に関する情報を、後続で訓練する弱学習器が引き継ぎながら、それを参考に誤差を小さくしていくアンサンブル学習です。
SVMのソフトーマージンにおいて、スラック変数をパラメータとして導入します。
ディープラーニングは他の機械学習の手法と比べて非構造化データを解析することが得意ですが、構造化データを扱えないわけではありません。構造化データを用いた予測問題では、特徴量作りを人間が行えるのでディープラーニングではなく決定木などの、よりシンプルかつ解釈しやすい手法を使うことが多いです。ディープラーニングはブラックボックスです。
K -meansではKというパラメータはユーザが決めます。K近傍法は以下のようなイメージです。
偽陽性を減らそうとすると、陽性か陰性か判断しづらいときに陰性と判断する傾向があります。そうすると偽陰性が増えます。再現率を高くしようとすると、正確度でなく、適合率が低くなります。つまり再現率と適合率はトレードオフの関係です。カテゴリ毎の出現割合が極端に異なる場合、適合率と再現率を同時に見ることが望ましいです。適合率は、陽性判断の正確性を示す指標です。適合率を重視すると不確実性のあるデータは陰性と判断されがちなので、偽陰性が発生しやすくなり、陽性の見逃しが増えるので再現率が下がります。再現率とは陽性判断の網羅性を示す指標です。つまり実際に陽性だったデータのうち陽性として検出できた割合です。再現率を重視すると、不確実性のあるデータは陽性と判断されがちのため、偽陽性が増えるので適合率が下がります。
機械学習のパラメータとは、モデルの挙動に関する設定値や制限値です。その一部は学習のプロセスの中で自動的に最適化されます。例えばニューラルネットワークの重みや決定木の条件分岐の閾値などです。ハイパーパラメータは、例えばニューラルネットワークの学習率や隠れ層の数です。モデルの複雑さや進行を制御する役割を持っています。
カーネル関数は、ガウス関数、線形カーネル、多項式カーネル、シグモイドカーネルなどがあります。これはハイパーパラメータです。学習データは訓練データとテストデータに分かれます。ハイパーパラメータのチューニングは、訓練データから取り出した検証データで行います。
欠損値はデータの一部が空白(歯抜け)になっている状態で、放っておくと機械学習の精度を悪化させます。そのため分析前に欠損値が存在するデータを適切に処理します。該当列を削除しても他の列と予測モデルへの影響がほぼないと判断できれば、その時点で削除して良い場合もあります。
データクレンジングとは学習データからノイズなどの予測の妨げになるものや不要なものを取り除く操作です。白色化は相関をなくしてから正規化をすることです。正規化や標準化の目的は、学習が進みやすいようにデータを値が一定範囲内に収まるように変換することです。平滑化はノイズを除去するデータの前処理です。曲線をなめらかにするイメージです。
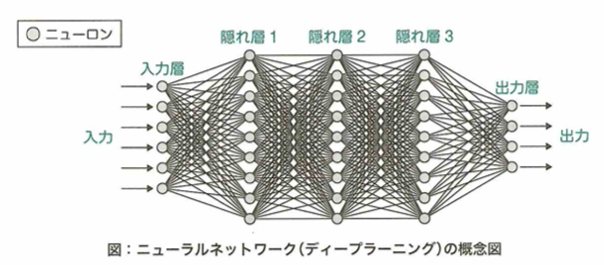
ディープラーニングの概要
G検定では、ニューラルネットワークが長年解決できずにいた問題の説明や、改善した手法についても理解しておく必要があります。
ニューラルネットワークとディープラーニング
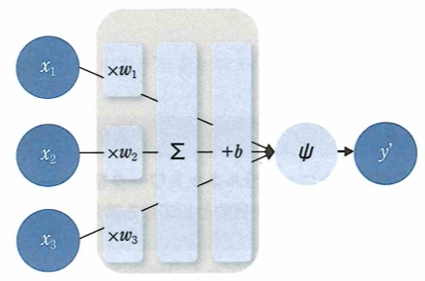
ニューラルネットワークにおける順伝播について重みはwです。
xは入力、bはバイアス、ψは活性化関数、y’は出力です。xを各ノードにし、y’を求めます。重みwとバイアスbを合わせてパラメータと呼びます。例えばアイスの売上を推定したいときに、x1が気温とすると、気温が最も売上に影響を与えるため、それに対する重みw1が大きくなるように学習します。
ニューラルネットワークモデルの構造
ニューラルネットワークは複数のニューロンが集まった層構造を内部に持ちますが、隠れ層に関して、中間層とも呼ばれます。入力と出力を対応づける関数に相当します。複数の層を持つことができます。
隠れ層のデザインの自由度は高く、その自由度の高さがニューラルネットワークの優れた表現能力の要因となっています。回帰問題では恒等関数が、分類問題ではソフトマックス関数が使われます。隠れ層の活性化関数にはシグモイド関数やReLU関数が使われます。
単純パーセプトロンと多層パーセプトロン
ニューラルネットワークの原点として単純パーセプトロンの特徴として適切なものは、隠れ層を持たないことです。
単純パーセプトロンは線形分類しか行えません。多層パーセプトロン(MLP)は1層以上の隠れ層が存在し、入力層と出力層を合わせて3つ以上の層が存在します。これにより非線形分類も可能です。
ニューラルネットワークの層の数と表現力
一般に隠れ層を増やしたニューロンネットワークをディープニューラルネットワークと呼びますが、隠れ層を増やす目的は、モデルの表現力を高めるためです。
層の数に対して表現力は指数関数的に上がっていきます。しかし層を増やせば学習時間も増えるので、他の事前学習済みモデルを目的のモデルの初期値に利用する、転移学習などの効率的な学習のための工夫が求められます。また、モデルの表現力が上がるほど、過学習の可能性が上がります。モデルの表現力が高いと、さまざまな関数を表現することがあるので、複雑な関数であっても過剰適合できてしまうためです。また、層を増やすことで重みが大きくならないようにできる効果はありません。
ニューラルネットワークの原点
ニューラルネットワークはもともと人間の脳の構造を真似しようと考えらえれた手法ですが、そこから解きたい課題の主題に応じて工学的にさまざまなアプローチが考えられ、さまざまなモデルが考案されました。
この原点である形式ニューロンは神経科学社・外科医のマカロックと、論理学者・数学者のピッツにより1943年に発表され、人工知能分野の研究に大きな影響を与えました。心理学者・計算機科学社のローゼンブラットは1958年に形式ニューロンを基にしてパーセプトロンを開発しました。1969年にミンスキーがニューラルネットワークの限界を指摘し、しばらくは人気の手法ではありませんでしたが、バックプロパゲーションの出現や活性化関数の工夫などを経て、今ではニューラルネットワークの層を深くしたディープニューラルネットワークを始めとし、さまざまなディープラーニングのモデルが登場して使わています。
ディープラーニングはニューラルネットワークを応用した手法
ディープラーニング(深層学習)では、大規模なラベル付けされたデータとニューラルネットワークの構造を利用して学習を行います。
ディープラーニングのモデルはディープニューラルネットワークとも呼ばれます。データから直接特徴量を学習できるので、これまでのような手作業の特徴抽出は必要がなくなりました。GAN(敵対的生成ネットワーク)はGenerator(生成者)とDiscriminator(判定者)の2つのネットワークが競合することで学習されます。Gneratorが入力データに似たデータを生成し、Discriminatorがそれが「学習データ」か「Generatorが生成したデータか」を判定します。それらのネットワークを互いに競わせて入力データの学習を進めることで、徐々に生成データが本物に近づき、クオリティの高いデータを生成できます。強化学習では、将棋や囲碁などのゲームAIが打ち手を学習する際や、自動運転における状況判断の学習に活用されます。
信用割り当て問題と誤差逆伝播法
信用割当問題とは、一連の行動によってある結果が得られたとき、その結果に対して各行動の貢献度がどれくらいであるのかを求める問題です。この問題はニューラルネットワークにおいて、モデル出力に貢献しているパラメータが一体どれなのかを見つける問題として知られています。もし、この問題が解決できないと、どのパラメータを最適化すれば良いかわからないので、モデルの最適化が困難になります。ここで、ニューラルネットワークにおいて、この問題を解決した手法は誤差逆伝播法です。
勾配降下法は、あるパラメータの誤差に対する勾配が分かったときに、その勾配を用いて最適化するものです。グリッドサーチとはニューラルネットワークにおいて学習率などのハイパーパラメータの最適な組み合わせを探索するものです。主成分分析とは。多くの特徴量を少ない特徴量に縮約するために用いられる手法です。
勾配消失問題
ニューラルネットワークを多層化することで生じる問題は勾配が消失し、学習が進みづらくなることです。
ニューラルネットワークを多層化すると、誤差逆伝播法においてそれぞれの層で活性化関数の微分がかかるので、勾配が消失しやすくなり、学習が進まなくなることを勾配消失問題と言います。活性化関数をシグモイド関数からReLU関数に変更したり、事前学習を行なったりすることでこの問題を回避しますが、複雑なモデルでは勾配消失問題は依然として課題となっています。
次元の呪いとは、扱いデータの次元が高くなるほど、計算量が指数関数的に増える現象です。トロッコ問題は、倫理学における思考実験の1つで、ある人を助けるために別の人を犠牲にして良いのか?を問うものです。状態行動空間の爆発は、強化学習における課題で、状態と行動の組みに対して定義される値を保存するための領域が極端に必要になってしまうものです。
ブラックボックス問題とは、AIの自ら膨大なデータを学習し、自律的に答えを導き出す特性上、その思考のプロセスが人間にはわからないということです。
シグモイド関数の微分と誤差逆伝搬法の勾配消失
ニューラルネットワークにおいて、隠れ層を増やすと誤差のフィードバックがうまくいかなくなることがあります。大きな原因の1つにシグモイド関数の特性があります。これは微分すると値が小さくなることです。
以前にニューラルネットワークの活性化関数として用いられたシグモイド関数についてのグラフは以下です。
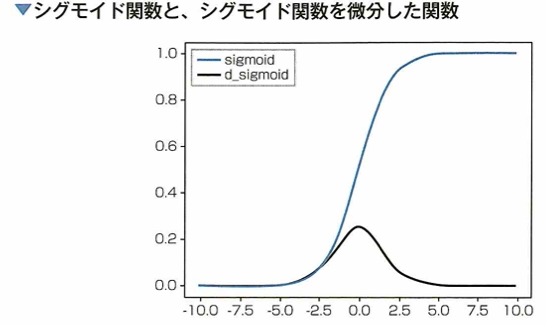
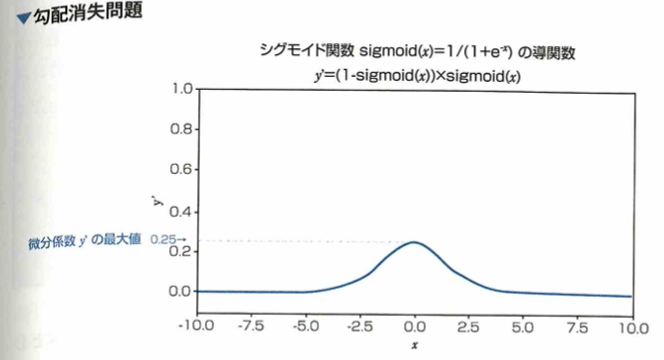
シグモイド関数の微分の最大値は0.25です。これは1よりだいぶ小さいので、隠れ層を遡る(活性化関数の微分が掛け合わされる)度に伝播する誤差がどんどん小さくなります。その結果、入力層付近の隠れ層付近に到達するまでに誤差がなくなってしまうという問題です。これを勾配消失問題と言い、ニューラルネットワークを深くする大きな妨げになりました。現在では代わりにReLU関数を用いることで勾配消失が起こりにくくなりました。勾配が消失しやすいと、学習が進まなくなります。
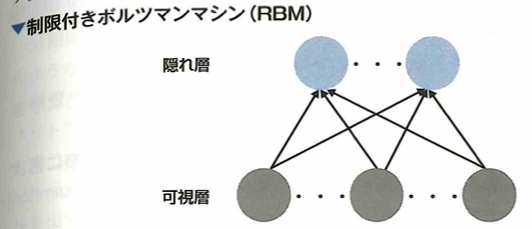
制限付きボルツマンマシン(RBM:resgtricted boltzmann machine)
ディープラーニングにおける事前学習(pre-training)は次元削減に役立つと言われます。その中でも制限付きボルツマンマシン(RBM)とは 2層のニューラルネットワークであり、深層信念ネットワーク(deep belief networks)の構成要素です。
ヒントンにより開発されたRBMは次元削減、分類、回帰などが可能です。
オートエンコーダは出力ユニットが直接入力ユニットに接続される単純な3層ニューラルネットワークです。情報量を小さくした特徴表現を獲得するので、出力を入力に近づけるように学習するニューラルネットワークです。ディープラーニング用に改良したものを積層オートエンコーダ(stacked autoencoder)です。
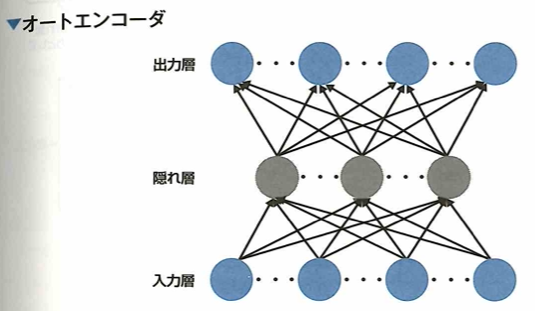
オートエンコーダも事前学習の1種であり、入力データの最も効率的でコンパクトな表現(エンコード)を見つけます。
事前学習によるアプローチ
オートエンコーダの構造
積層オートエンコーダー(stacked autoencoder)について、これは複数のオートエンコーダの隠れ層(中間層)を積み重ねたもので、次の構造をしています。
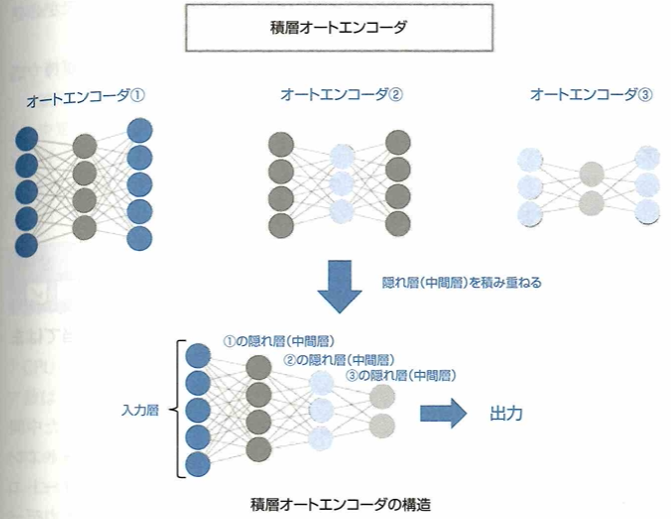
ここで積層オートエンコーダでは、勾配消失の問題を回避してニューラルネットワークの積み重ねを学習するために入力層に近い層から順に逐次的に学習を行うという方法で学習を行いました。
これによりそれぞれの層で重ねが調整済みとなっています。このようにオートエンコーダを順番に学習させていく手法を事前学習と言います。
積層オートエンコーダにラベルを出力
積層オートエンコーダにおける事前学習は、入力と出力を同じものになるように学習を進めていきますが、これは教師なし学習です。事前学習によってデータに含まれる重要な特徴を取り出すことができます。一方で、分類問題や回帰問題といった教師あり学習を行うには、事前学習済みの積層オートエンコーダに出力層を追加し、調整を行うといった工夫が必要です。ここで、積層オートエンコーダで分類問題を解く際に追加する出力層が持つ活性化関数はsigmoide関数またはsoftmax関数です。
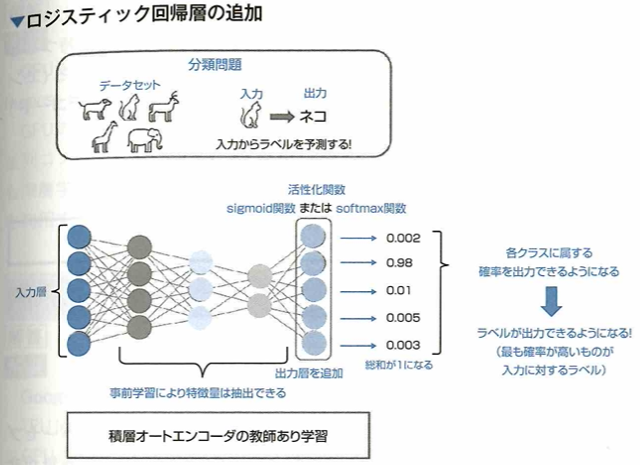
最後に追加する層は出力層です。二項分類の場合はsigmoid関数、多項分類の場合はsoftmax関数を出力層に考えます。回帰問題の場合は、出力層に線形回帰層を用います。このように新たな出力層を追加した場合は、出力層の重みを調整するためにネットワーク全体を学習して調整するファインチューニングが必要となります。積層オートエンコーダを用いるモデルでは、初めに事前学習によってデータの特徴量を学習し、その後出力層を追加してファインチューニングを行う2つの工程で構成されます。
オートエンコーダの入力データの特徴
オートエンコーダ(自己符号化器)について考えます。基本的にオートエンコーダとは、入力と出力の形が同じになるようにした中間層を1つ持つニューラルネットワークです。ここで、オートエンコーダでは、入力と出力が同じものになるように学習を行います。このときオートエンコーダでは、中間層の次元数を入力層の次元より小さくするような構造にすることで、入力データに含まれる重要な特徴を抽出できます。
一般的にオートエンコーダは入力層の次元数と比べて中間層の次元数が小さくなるような構造をしています。このような構造により、オートエンコーダでは入力されるデータの情報を圧縮している(エンコード)と共に、圧縮されたデータから元のデータを復元している(デコード)と考えることができます。
ハードウェア
ディープラーニングとGPUの相性の良さ
ディープラーニングの根幹のパーセプトロンのアルゴリズム自体は1950年代に提案されましたが、莫大な計算量が必要なものや、SVMなどが人気であったので、長き日に渡り日の目を見ませんでした。近年では、その学習が並列計算と相性が良いことから、GPUを利用して短時間での学習が行われています。
ディープラーニングのアイデアや技術自体は多層パーセプトロンの形で昔からありましたが、層を深くした時の計算量が非現実的でした。計算は行列の積和演算で、これは画像やCGの分野でポリゴンの処理が得意なGPUに向いている計算です。近年はこの相性の良さが注目され、畳み込みニューラルネットワーク(CNN)などのアイデアが次々と実現可能となりました。
CPU
CPUの主な役割はコンピュータ全体の計算であり、複雑な命令の逐次計算な計算を得意とします。CPUのコア数は通常数個であるのに対し、GPUのコア数は数千個です。
CPU(central processing unit)はコンピュータ全体の処理を担います。メモリやハードティスクなどの周辺機器とデータをやり取り・制御しています。そのコアは少数で高性能で、多様なタスクを順番に処理していくことに特化しています。
GPGPU
GPUは画像処理に特化したプロセッサで、GPUを用いて汎用的な演算を行わせるための技術であるGPGPUを適用することで、ディープラーニングに応用できます。NVIDIA社が提供する汎用並列コンピューティングプラットフォームにCUDAがあります。
GPGPU(general-purpose computing on GPU)の主要メーカーのNVIDIA社が開発したCUDAはGPU向けの汎用並列コンピューティングプラットフォームです。深層学習のフレームワークは、Keras、PyTorch、Tensorflowなどです。
TPU
Googleが開発する、ディープラーニングの学習・推論に最適化された計算ユニットにTPUがあります。ディープラーニングでは演算の精度(倍精度演算など)がそこまで求められていないので、精度を犠牲にすることで高速化を行なっています。GPUなどは演算中の途中結果をメモリに読み書きしますが、TPUでは回路内で結果を渡すことでメモリへの読み書きを減らし、高速化を図っています。
TPU(tensor processing unit)はディープラーニングの学習・推論に最適化されており、タスクによってGPUの数十倍のパフォーマスを発揮します。Googleの提供するクラウドサービスGCP(google cloud platform)上で使用でき、誰でも簡単に試せます。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
能動学習はアノテーション対象のデータの中から学習することで性能向上が見込めるものを戦略に従って選び抜き、限られたコストで精度の高いモデルを開発することを狙う手法です。データが少ない場合は過学習が起きやすくなります。ディープラーニングはブラックボックスです。単純パーセプトロンは線形分離不可能な問題を扱えませんが線形分離可能な2クラス分類問題を解くことはできます。
GPUは並列処理を得意とする演算処理装置です。ただし条件分岐を含むなどして処理方法が異なるような演算を同時に処理することは不得意です。画像処理以外に開発されたGPUであるGPGPU(General-purpose computing on GPU)はディープラーニングの学習を効率的に行うことができます。Googleはテンソルの計算処理に最適なTPUという装置を開発しました。
Leaky ReLUはReLU(これらの関数は隠れ層で使用します。線形関数(恒等写像関数)は主に回帰タスクの出力層の活性化関数として使用します)に改良を加え、入力が負の場合は入力に0.01などの小さな値を乗じて出力します。それ以外はReLUと同じです。そのため傾きが一定の線形関数ではありません。また、入力が0以上の場合は非線形な出力はしません。そのため勾配消失問題が発生しにくくなっています。
ニューラルネットワークの隠れ層における活性化関数は非線形な関数を使用します。これにより隠れ層で非線形変換を繰り返すことで、線形分離不可能な複雑な問題を解くことができます。隠れ層における活性化関数では、入力や出力に関する制約はありません。
損失関数(誤差関数)において回帰タスクではMSEが使用されます。分類タスクでは交差エントロピーを使用します。KL情報量は2つの確率分布の異なり具合を測る指標です。機械学習で交差エントロピーを最小化することとKL情報量の最小化は同義です。 MAE(平均絶対誤差)は回帰タスクで使用されます。
深層距離学習とはデータのペアに対して対してニューラルネットワークを用いてその類似度を学習する手法です。ここでは2つ以上のデータの組に対して距離の情報を考慮した損失を計算します。代表的な損失として、Contrastive Loss、Triplet Lossがあります。前者は画像データをベクトルに変えたものの画像データの距離です。後者は3つのデータの組みを使用して計算する損失です。
L0正規化は0でない大きさを持つパラメータの総数を損失関数に加える手法です。L1正規化はパラメータの大きさの絶対値の総和を損失関数に加える手法で、L2正規化はパラメータの大きさの2乗和を損失関数に加える手法です。
ドロップアウトは過学習を防ぐ手法です。ランダムにニューロンを除外する手法です。訓練時にランダムに選ばれたいくつかのニューロンの重みを0として計算します。学習のたびに除外されるニューロンがランダムに決まるので、毎回異なる構造のネットワークを学習することになるので、アンサンブル学習とみなせます。
信用割り当て問題とは、ニューラルネットワークにおいて、各ニューロンが出力を改善するために、予測結果からどのようにフィードバックを受ければよいかに答えることが簡単ではないことです。
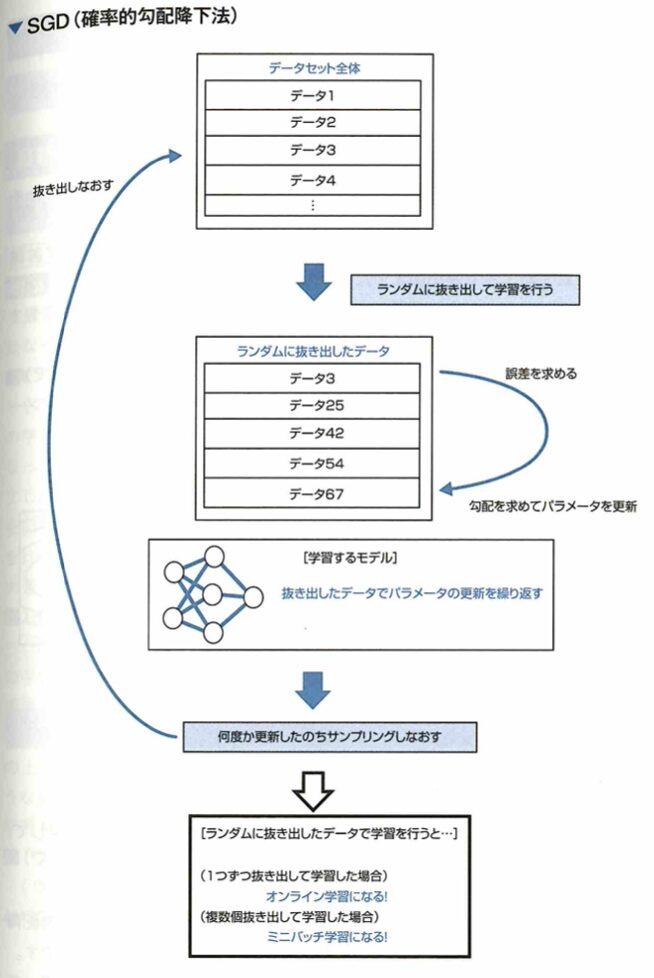
確率的勾配降下法について、勾配降下法が勾配の計算に全ての訓練データを用いることで計算量が増大する問題を解消することに対し、確率的勾配降下法は、訓練データからランダムに抽出した一部のデータを使用して勾配を推定することで学習を高速化します。これを一般化して訓練データから一部のデータをランダムに取り出して学習する手法をミニバッチ学習と言います。訓練データから一度に1つのデータのみを取り出して学習する手法をオンライン学習と言います。
モーメンタムは勾配降下法における学習率を学習中に適度に調整することで鞍点などの学習の停滞を防ぐ手法です。学習率とは勾配降下法において求めた勾配に従ってどの程度パラメータを更新するかを決定する定数(ハイパーパラメータ)のことです。勾配降下法の発表が古い順に、モーメンタム、NAG、AdaGrad、AdaDelta、RMSprop、Adam、AdaBound、AMSBoundなどがあります。最後の2つは同じ論文で提案されたものです。
エポックとは訓練データ全体に対する学習の反復回数を表す概念です。1エポックは、全ての訓練データを1度ずつ用いてパラメータを更新した時で定義します。パラメータの更新は主に確率勾配降下法で行われるので、実際のパラメータの更新は訓練データからサンプリングした一部のデータによって行われます。このパラメータ更新の単位がインテレーションです。複数回のインテレーションによってパラメータの更新を繰り返し、全ての訓練データを一巡した段階が1エポックとなります。早期終了とは学習時のエポックとともに検証データにおける誤差を評価し、この誤差がエポックを進めても改善しなくなった時点で学習を打ち切ります。二重降下現象は、横軸をインテレーションやエポック、縦軸に汎化誤差をとった時のグラフで表現できます。二重降下現象は学習中に減少していたテストデータに関する誤差が一度増えた後で再び減少する現象です。
ハイパーパラメータは学習可能なものではありません。このため学習と汎化誤差の評価を繰り返して最適な組み合わせを行います。これをチューニングと言います。代表的な手法としてグリッドサーチとランダムサーチがあります。前者は全ての組み合わせを網羅的に探索し、後者はランダムに選択して探索しますが、最適な組み合わせが見つかるとは限りません。
ディープラーニングの手法(1)
理論的な側面に加えて、多くの用語の違いまで出題されます。それぞれの内容の流れと用語を理解して、区別できるようにしておきましょう。
活性化関数
シグモイド関数
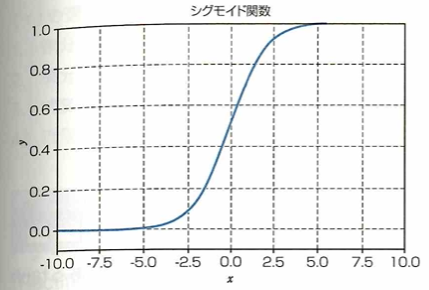
シグモイド関数y=1/(1+e^(-x))は入力x(全ての実数)に対して、出力yの範囲は0≦y≦1となります。近年では、この関数はニューラルネットワークの隠れ層の活性化に用いられることは減っていますが、その理由は勾配消失が起きやすい特徴からです。
ニューラルネットワークでは最適なパラメータを見つけるため誤差を逆向きに掛け合わせて伝播させていく誤差逆伝播法が用いられます。この伝播中に活性化関数の微分を掛け合わせる項がありますが、シグモイド関数では最大で0.25であり、この項を掛けるごとに誤差の値は小さくなり、入力付近に近い層ほど伝播すべき誤差がなくなってしまう勾配消失問題が起きやすくなります。
出力層での活性化関数の特徴
出力層で用いられる活性化関数は出力を確率で表現するため、特定の活性化関数が使われます。二値分類ではシグモイド関数が、多値分類ではソフトマックス関数が用いられます。
ソフトマックス関数はシグモイド関数の一般形で、複数の入力を受け取り、受け取った数と同じ個数の出力を総和が1となるように変換して出力します。

ReLU関数は出力の値が[0,1]に限らないので、出力を確率として表現することは難しいです。
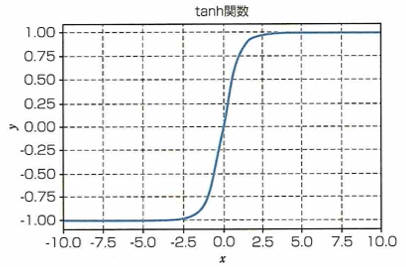
tanh関数とシグモイド関数との関係性
ニューラルネットワークの隠れ層で用いる活性化関数であるtanh関数について、シグモイド関数では、任意の実数で微分したときの最大値が0.25であることに対して、tanh関数は微分したときの最大値がより大きくなるようになっています。このためシグモイド関数と比べて、活性化関数にtanh関数を用いた場合、誤差逆伝搬法を用いて重みなどのパラメータを計算した際に勾配消失問題が緩和されています。またtanh関数はシグモイド関数を式変形(線形変換)することで求めることができます。
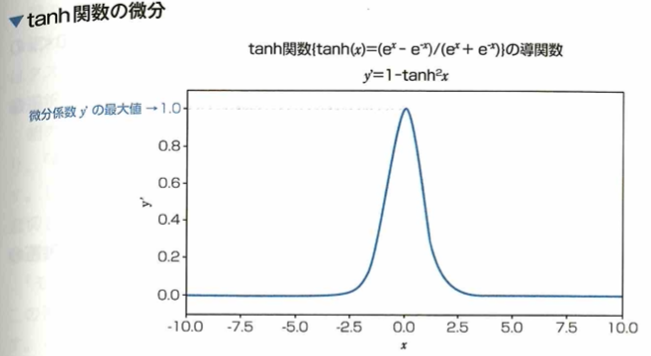
微分のおける最大値が大きいから言って、根本的な勾配消失問題の解決には至りません。
またtanh関数(=(e^x-e^(-x))/(e^x+e^(-x)))はシグモイド関数(sigmoide(x)=1/(1+e^(-x)))を用いてtanh(x)=2×sigmoid(2x)-1とかけます。
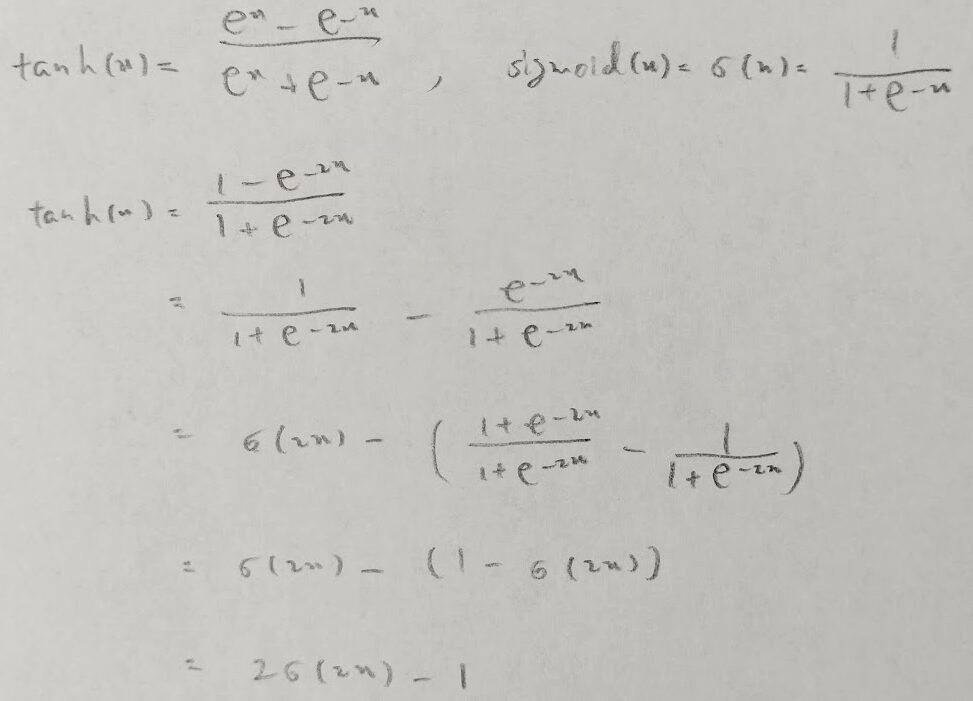
tanh関数は活性化関数に用いられる関数の1つで、入力xの値を−1≦x≦1の範囲の値に変換します。主に隠れ層(中間層)で用います。
ReLU関数
ディープラーニングで使われる活性化関数の1つであるReLU関数(rectified liner unit)は、多くの種類のモデルでよく使われている活性化関数です。ReLU関数はシグモイド関数やtanh関数と比べて大きく異なった形をしていますが、数式ではy=max(0,x)と簡単に表せます。グラフは下図になります。
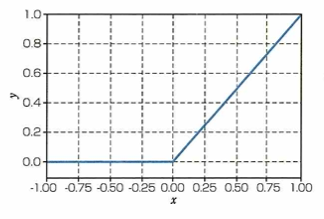
これまでの活性化関数より勾配消失問題が起きにくいですが、どんなタスクにおいてもReLU関数を使うことがベストではありません。この関数は非線形の関数であり、x≦0の時は微分係数は常に0、x>0の時の微分係数は常に1となります。
学習の最適化
誤差関数
ニューラルネットワークの目標はモデルの予測値を実際の値に近づけることであり、この目標を達成するために誤差関数を最小化するアプローチが取られています。朝の気温から正午の気温を予測するモデルを考えます。朝の気温と正午の気温のセットのデータを所持している状態で、朝の気温の平均が16℃で正午の気温の平均が18℃という統計量が求まりました。このデータから朝の気温から正午の気温を予測するモデル(ニューラルネットワーク)を作るとき、次のイメージになります。
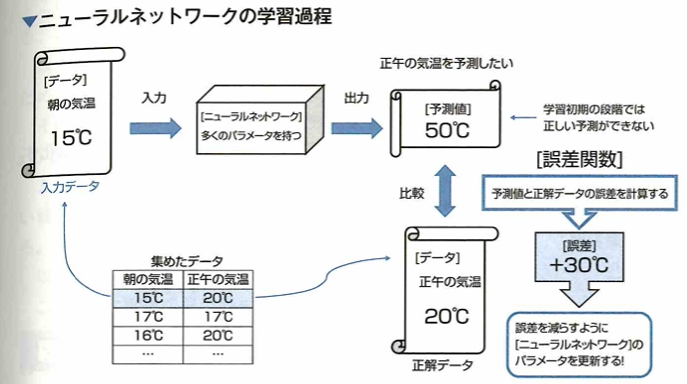
このときの誤差関数は朝の気温に対するモデルの予測値と対応する正午の気温の気温との誤差のように定義されます。
誤差関数とは、モデルの予測値と実際の値(正解データ)との誤差を表した関数です。
傾きの概念
関数の傾きの定義はΔy/Δxです。
微分係数と関数の最小値
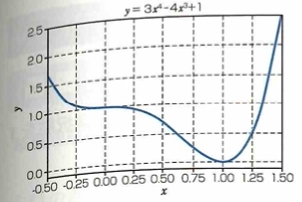
上の関数において、x=1のときにyは最小値を取りますが、このxが未知の場合を考えます。初期値としてx=0.5と設定します。この値の微分係数を求めると符号はマイナスです。これを踏まえて初期ちから未知の最小値x=1に近づく方向に進ためには、xの値をxから微分係数を引くように更新すれば良いです。その後に、更新したxの値で再び同じ作業を繰り返せばx=1の値にどんどん近づきます。また、この際にその時の微分係数は0に非常に近くなるので、それ以降の更新によりxの値は変化しにくくなることがわかります。
実際には学習率という数値を導入してxを更新する際の変化量を調整します。
学習率
勾配降下法における学習率について考えます。関数の勾配にあたる微分係数に沿って降りていくことで、最小値を求める手法を勾配降下法と言います。学習率とは勾配に沿って一度にどれだけ降りていくかを設定するものという役割を持ちます。学習率とは、勾配降下法においてパラメータxを更新する前に微分係数に掛かる0より大きい実数です。学習率は勾配降下法において重要な要素の1つで、設定によっては最適解が得られない場合があります。

勾配降下法によりパラメータが最適解にどれだけ近づくかは、同じ学習率でも関数の形や勾配を求めるパラメータの位置で変化します。また現在の値から更新後の値までの距離は、現在の値における勾配の大きさと学習率で決まります。
勾配降下法は大域最適化に必ず収束しない
勾配降下法の収束値について考えます。
この関数において、勾配降下法を用いて最小値を探します。xの初期値と学習率をあらゆる値で試したとき、xが収束する可能性がある値は-3、0、6です。ただし学習率の範囲は(0、1] とします。このため勾配降下法は確実に最小値を見つけることができるわけではありません。この関数において真の最小値はx=6のときの値ですが、この真の解を大域最適解といい、x=ー3のような局所的な解を局所最適解と言います。
パラメータが大域最適化に収束しやすい学習率
この関数について初期値をx=ー6に設定して勾配降下法を用いたら、局所最適化のx=−3に収束しました。そのため初期値はそのままにして、学習率を調整するアプローチで大域最適化に収束しやすくすることを考えます。このときインテレーションが少ない段階において学習率は大きくなるように設定すると良いです。インテレーションとは勾配降下法においてパラメータの更新回数のことです。そうすることで、局所最適解と大域最適解の間にある一時的にyの値が大きくなる領域を超えて大域最適解に近づくことが可能です。一方で学習率が大きいのままだと大域最適解付近においても最適解を飛び越えてパラメータの更新を続けてしまうという問題が起きやすくなります。そのため学習率を適切なタイミングで調整し直すことが大事です。
学習率が大きいままであることが原因で、計算誤差が蓄積することはありません。また学習率が大きいままであることが原因で、収束する値が初期値に依存することはありません。しかし、学習初期から学習率が小さい場合においては、初期値に近い局所最適解や大域最適解に収束しやすくなるとは考えられます。エポックとは1つの訓練データを何回学習させるかのハイパーパラメータです。
鞍点
鞍点について考えます。3次元以上の関数に対して勾配降下法を用いる際は、鞍点が学習のうまくいかない原因となることがあります。鞍点は一般的に平坦な領域に囲まれている場合が多く、一度鞍点に陥ると再び鞍点から抜け出すことは困難になります。このような停滞状態にあることをプラトーと言います。
鞍点とはある次元から見ると極大点で、ある次元から見ると極小点となる点です。
確率的勾配降下法(SDG)
ニューラルネットワークの学習では、パラメータに対して最適な値に近づく勾配を求めることが大事です。訓練データをネットワークに入力し、結果(出力)を求めて、その結果と正解の誤差を計測します。このように求めた誤差を減らすことを考えてパラメータを最適化する勾配を求めることができます。最急降下法(Gradient Discent)ではデータセットを全てネットワークに入力して誤差を求め、パラメータを更新することを繰り返します。SDG(Stochastic Gradient Discent)確率的勾配降下法はパラメータxを更新する際に、データは全データの中からデータをランダムに抜き出して利用します。このようにしたときSDGのパラメータを更新する式はx_new=(x_old)×学習率×(抜き出したデータを使って求めた勾配)です。
データセット内のデータを全て用いる手法はバッチ学習と呼ばれ、最急降下法はこのバッチ学習の一種です。対して、データを1つずつ逐次的に学習する手法をオンライン学習、いくつかのデータのまとまりを逐次的に用いて学習する手法をミニバッチ学習と言います。SDGは最急降下法をオンライン学習またはミニバッチ学習に適用したものです。
SDGにおいては求めた勾配を用いてパラメータを更新するとき単純に学習率をかけてパラメータから引くことで更新します。この時の勾配は、ランダムに抜き出されたデータを用いて求めた勾配です。SDGに工夫を加えて改良した手法は、モーメンタム、RMSPropがあります。これらの手法は勾配を求めるところまではSDGと同じですが、SDGでは単純に勾配に学習率をかけて引いていた部分に改良を加えることで、良い手法になっています。
モーメンタム
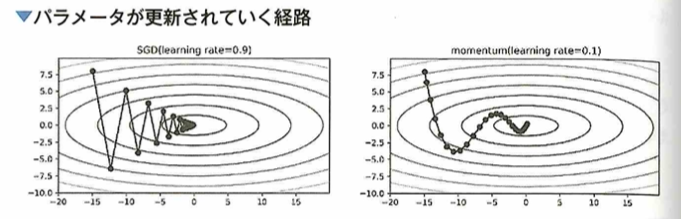
分配下降法の手法について考えます。ニューラルネットワークの学習において基本的な手法であるSGD (Stochastic Gradient Descent: 確率的勾配下降法) は、最急降下法を改良したものの1つです。しかしSGDには局所解に陥ってしまう問題や非効率な経路で学習してしまうといった問題があるので、SGDに改良を加えたモーメンタムと呼ばれる手法が考えられました。この手法自体はディープラーニングブーム以前の1990年代から考えられています。このモーメンタムと呼ばれる手法は、力学の考え方を用いてパラメータの更新に慣性的な性質を持たせ、勾配の方向に減速・加速したり、摩擦抵抗によって減衰したりしていくようにパラメータを更新していくという工夫を加えることでSGDを改善し、学習をより効率的に行えるようにしたものです。
モーメンタムを用いることで最小値まで辿り着く経路がSDGと比べて無駄の少ない動きとなっているとともに、停滞しやすい領域においても学習がうまく行きやすくなるメリットがあります。
勾配降下法の最適化手法
勾配降下法の手法について考えます。ニューラルネットワークの学習において鞍点などに陥る問題に対処するため、ディープラーニングブーム以前からモーメンタムと呼ばれる慣性の考えを用いる手法はありました。その後ディープラーニングのブームを受けてモーメンタムより効率的なさまざまな手法が考えられました。これらはモーメンタム同様に求めた勾配を用いてどのようにパラメータを更新するのかという部分に工夫を加えたものです。古いものからAdaGrad→RMSProp→Adamという手法が考案されています。AdaGradは求めた勾配によりパラメータごとの学習率を自動で調整するものです。RMSPropはAdaGradの学習のステップが進むと、すでに学習率が小さくなり更新されなくなってしまう問題を改良したもので、AdamはRMSPropのいくつかの問題点をさらに改良したものです。
SDGでは手動で学習率を決めてすべてのパラメータに対して同じ値を用いていましたが、AdaGradでは勾配の情報を用いてパラメータごとの学習率を自動で調整していくアルゴリズムです。AdamはRMSPropを改良したもので、2014年に発表されました。
最新のディープラーニングの最適化手法
ディープラーニングを最適化する手法はたくさん提案されています。その1つであるSGD(Stochastic Gradient Descent:確率的勾配下降法)は、学習率を固定してパラメータを更新していきます。これに対しAdamは学習率を動的に求めることで学習速度をSGDに比べて速めることに成功しましたが、Adamの学習率は重要でない勾配に対して大きすぎたり、重要な勾配に対して小さすぎたりすることがあり、学習がうまくいかない場合がありました。そこで重要でない勾配に対して2乗勾配を利用して学習率が大きくなりすぎることを改善するAMSGradという手法が提案されました。しかし、これは学習率が小さくなりすぎることを考慮していないため、学習率の上限と下限を設定し、少しずつ狭めて最終的に1つの値となるようにする手法が生まれました。その手法は2つあり、Adamに対して適応した手法がAdaBound、AMSGradに対して適応した手法がAMSBoundです。これらは学習前半でAdamのように高速に学習し、学習後半でSGDのような学習をします。
AMSGradは、「Adamの学習率が大きくなりすぎることがある」という問題を解決した手法となっています。Adamでは学習率の変化を過去からの勾配情報を用いて行っていましたが、昔の勾配情報を長期的に残すことが困難だったため、重要な勾配情報を忘れてしまうことがありました。AMSGradは現在の勾配情報と過去の勾配情報を比較して重要な方を選択し、保存しておくことで不必要な勾配に関して学習率が大きくなりすぎることを防いでいます。
AdaBoundは「Adamの学習率が大きくなりすぎることや、小さくなりすぎる」という問題を解決した手法となっています。AdaBoundはAdamの学習率の変化に対して、学習率に上限と下限を用意し、その範囲を超えないように学習率を設定します。さらに学習率の上限と下限の幅を次第に狭めていき、最終的に一定値とすることでSGDのような効果を学習後半で期待します。これにより学習前半はAdamのような高効率な学習を行い、学習後半ではSGDのような正確な学習を行うことができます。AMSBoundはAMSGradに対してAdaBoundと同じ手法を適用させたものです。
かなりややこしい部分なので時系列的にまとめます。
最小値を求めたい→学習率→SGD→モーメンタム→AdaGrad→RMSProp→Adam→AMSGrad→(Adamに対して)AdaBound、(AMSGradに対して)AMSBound
ハイパーパラメータ
ハイパーパラメータとは、ニューラルネットワークの学習率や、決定木の深さなど、人が設定するパラメータのことです。機械学習モデルでは、ハイパーパラメータを適切に設定することで学習速度が上がったり、汎化性能が向上したりすることが期待できます。そのハイパーパラメータを探索することをハイパーパラメータチューニングと言います。
ハイパーパラメータチューニングをする方法の1つとして、kー分割交差法を用いた検証を行い評価します。ハイパーパラメータチューニングは、考え得るハイパーパラメータの組み合わせから1つの組を選び、それの学習結果を見て、学習時のハイパーパラメータの良し悪しを決めます。そのハイパーパラメータの選び方として、グリッドサーチとランダムサーチがあります。それぞれの手法特徴はグリッドサーチは考え得るハイパーパラメータの組み合わせを全通り選択し、ランダムサーチはランダムに組み合わせを選択します。
グリッドサーチは、考え得るハイパーパラメータの組み合わせを全通り選択する探索方法です。グリッドサーチは最も良い組み合わせを見つけることができますが、ハイパーパラメータが多いと探索コストが非常に大きくなります(例えば、3つハイパーパラメータがあり、それぞれが5つの値を持っている場合、その組み合わせは5の3乗の125回検証が必要です)。ランダムサーチは、ハイパーパラメータの組み合わせをランダムに選択する探索方法です。グリッドサーチより少ない回数で探索できますが、最適解を見つけられるかはわかりません。そのほかにもベイズ最適化というのもあり、これは結果が良かったハイパーパラメータの組み合わせに似た組み合わせをランダムに探索していきます。
さらなるテクニック
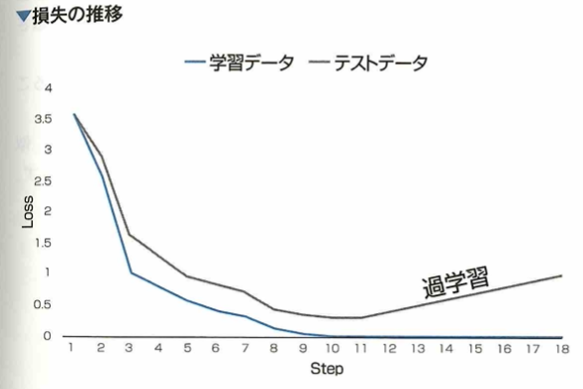
過学習
過学習(オーバーフィッティング)とは、機械学習においてモデルが訓練データに過剰適合することです。過学習が進んでしまっているとき、モデルの予測値と訓練データの間の誤差は十分小さな値に収束する傾向があります。一方でモデルの予測値とテストデータ(学習に用いていないデータ)との間の誤差はだんだん増加していく傾向があります。すなわち、過学習が進んでしまうとモデルの実用性が落ちてしまいます。
二重降下現象
二重降下現象は、モデルのパラメータ数やエポック数を増やすと学習結果のエラーは下降していくが、さらに増やすと上昇して、さらに増やすと下降していく現象です。
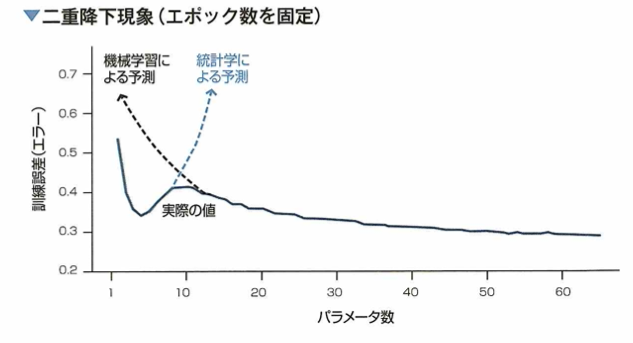
二重降下現象とは、モデルのパラメータ数や学習のエポック数(エポックは学習データセット全体を使った一回の学習プロセスを指します)が増えるたびに、学習結果のエラーが二度降下する現象です。上の図においてエポック数は固定します。ことのき機械学習による予測も、統計学による予測もそれぞれ裏切られることになります。二重降下現象の起きる原因は解明されておりません。
ドロップアウト
ドロップアウトについて考えます。過学習が進んでしまうとモデルの汎化性能が落ちてしまいます。この問題に対して、ニューラルネットワークの学習においては過学習を防ぐ手法の1つにドロップアウトがあります。ドロップアウトとは、学習の際、一部のノードを無視して学習を行う手法です。すなわち、ドロップアウトによってノードを無視するのは学習時のみで、推論時は除外しません。ドロップアウトにより、学習中のニューラルネットワークの形は更新のたびに異なる形となると考えられます。つまり、ドロップアウトを行った場合、複数のネットワークが同時に学習されることになります。このようにすることで、複数のネットワークのうち、いくつかが過学習してしまったとしても、全体として過学習の影響を抑えることができます。すなわち、ドロップアウトはアンサンブル学習を行っていると考えることができます。
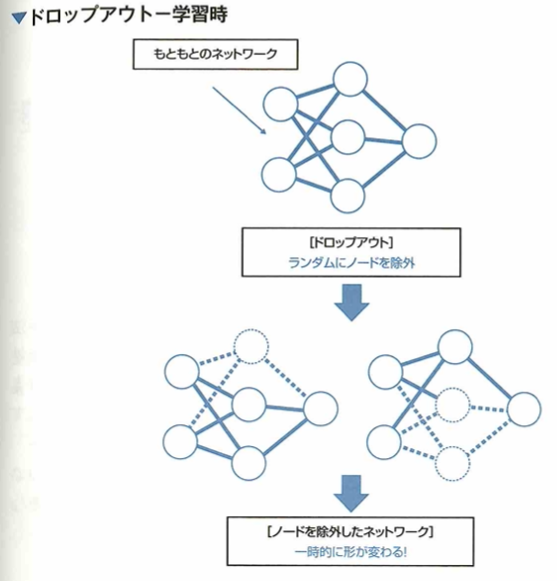
ドロップアウトは学習中ランダムにノードを除外して学習を行う手法です。学習はエポックごとに形の変化したネットワークを学習します。
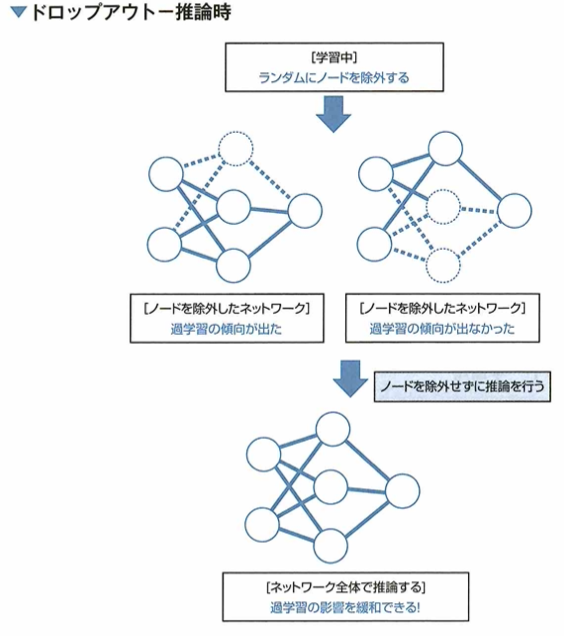
ドロップアウトを行うと、複数のネットワークで推論を行う手法に近くなるので、アンサンブル学習(複数のモデルを学習し結果を統合する手法)をおこなっていると考えられます。
early stopping
early stoppingについて考えます。過学習を防ぐ手法の1つにearly stoppingがあります。 early stoppingとは学習の際、学習を早めに切り上げて終了することです。 このとき学習を打ち切るタイミングをテストデータに対する誤差関数の値が上昇傾向に転じたときとすると、そこが過学習の起きる前の最適な解であると考えることができます。 この手法をニューラルネットワークに適応する際の良い点としてどんな形状のネットワークの学習においても容易に適応できるということです。
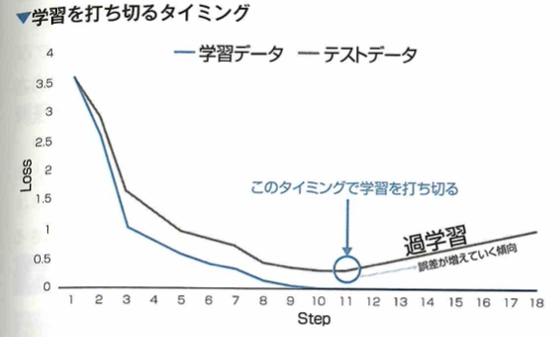
early stoppingにはテストデータに対する誤差の値を利用しますが、この誤差を早く減少させるような効果はありません。基本的に適応するモデルにパラメータ数がいくつあっても適応しますが、そのモデルのパラメータを削減する効果はありません。学習の終盤で作用することで過学習を防ぐ効果がありますが、モデルのパラメータの初期値に対する依存度を下げる効果はありません。
ノーフリーランチ定理とは、あらゆる問題に対して性能の良い汎用最適化戦略は理論上不可能であるという定理です。
データの正規化

この例での正規化とは身長と体重を同じm単位に揃えることによりデータ全体を調整することです。このデータを[0,1]に収まるようにするためには、変換として、各特徴量の最大値で対応するデータの特徴量を割る作業を行うと良いです。
データの標準化
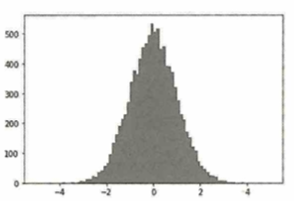
機械学習におけるデータの前処理について、各特徴量を平均0で分散1となるように変換する処理を標準化と言います。例えば任意の実数量をとるデータを10000個集めたとき、次の分布が得られたとします。
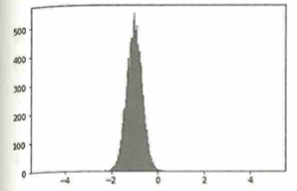
このデータを標準化した後の分布は下図になります。
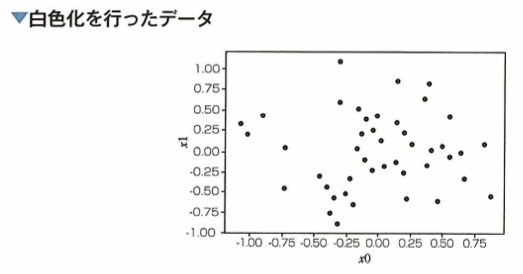
データの白色化
機械学習におけるデータの前処理について、各特徴量を無相関化した上で標準化する処理を白色化と言います。例えば元データが次の散布図があります。
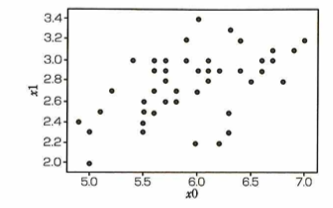
このとき2つの特徴量に対して無相関化を行った後の散布図は下図になります。
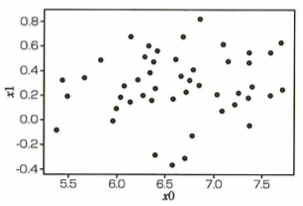
問題文のデータは正の相関があります。そのため無相関化を行うと、相関が0のデータ(上図)が得られます。このデータに対して、標準化を行うことで白色化されたデータが得られます。
ニューラルネットワークの重みの初期値
ニューラルネットワークのパラメータの初期値について考えます。ディープラーニングにおいて、入力前にデータの標準化を行うことでデータの分布を揃えることができました。 しかし、深いニューラルネットワークの学習においては、活性化関数を何度も通るためにその分布がだんだんと崩れていってしまいます。このように分布が崩れて偏りが発生すると、勾配消失問題が起きたりネットワークの表現力が落ちてしまう可能性が高いです。
このような問題に対して、ネットワークの重みの初期値を工夫するというアプローチがあります。 これはネットワーク内のある層に対して、ネットワークの大きさと活性化関数の種類に対応する適切な乱数を設定するというものです。 たとえば、ReLU関数は入力が負の値の場合出力が0になることから、各層の出力に適度な広がりを持たせるには、sigmoid関数と比較して初期値がより広い分布を持ったものであると良いと考えられます。 このアプローチについて、ネットワーク内のある層に用いられている活性化関数とその適切な初期値について適切な組み合わせはシグモイド関数:Xavierの初期値、ReLU関数:Heの初期値です。 ここでXavierの初期値とHeの初期値とは、それぞれ次のようなものです。

ニューラルネットワークで用いられる重みの初期値について、各層に用いられている活性化関数によって、どのような初期値を設定するのが良いかを問う問題において、初期値を特定の分布に従った乱数で設定するのは、ニューラルネットワークの各層において、活性化関数を通した後の値に適度なばらつきを持たせたい、ということが目的になります。例えば、このような分布に偏りが生じている場合、ある層での出力が1または0の2種類に偏ってしまうと勾配消失問題が発生し、0.5などの1つの数値に偏ってしまうとネットワークの表現力に制限がかかってしまうと考えられます。
この問題に対し、ノードの初期値を適切な分布から生成される乱数で設定するというアプローチが考えられており、各層で使用している活性化関数がシグモイド関数(sigmoid関数)やtanh関数の場合は、ノードの初期値としてXavierの初期値を用いると良いと提案されています。これは各層の出力を同じくばらつかせることを目的として求められた値であり、上の表で与えられる標準偏差を持つガウス分布より生成される乱数です。ただし、Xavierの論文では、次層のノード数も考慮したより複雑な設定値が提案されており、ここではそれを単純化したものを用いています。
一方、ReLU関数を活性化関数として用いた場合、Heの初期値を用いるのが良いと提案されています。Heの初期値は、Xavierの初期値と比較して、より大きな広がりを持った分布によって生成される乱数です。ReLU関数は入力が負の値の場合出力が0になります。そこで、各層の出力に広がりを持たせるには、初期値により広がりを持たせなければいけないと考えられ、このような設定値となっています。
バッチ正規化
ディープラーニングにおいて、活性化関数を通ることでデータの分布が崩れていく問題に対するアプローチには、ネットワークの重みの初期値を工夫するというものの他に、直接的なアプローチとしてバッチ正規化というものがあります。これはネットワークにおいて、各層で伝わってきたデータに対し、正規化を行うというものです。これは無理やりデータを変形しているということであり、どのように調整するかはネットワークが学習します。バッチ正規化の処理を行うことによって、データの分布が強制的に調整され、勾配消失問題などが改善することにより学習がうまくいきやすくなると考えられます。さらにバッチ正規化のメリットには、過学習しにくくなるという効果があることも知られています。
バッチ正規化は、ニューラルネットワークの各層で前の層から伝わってきたデータに対して、もう一度正規化を行うものです。
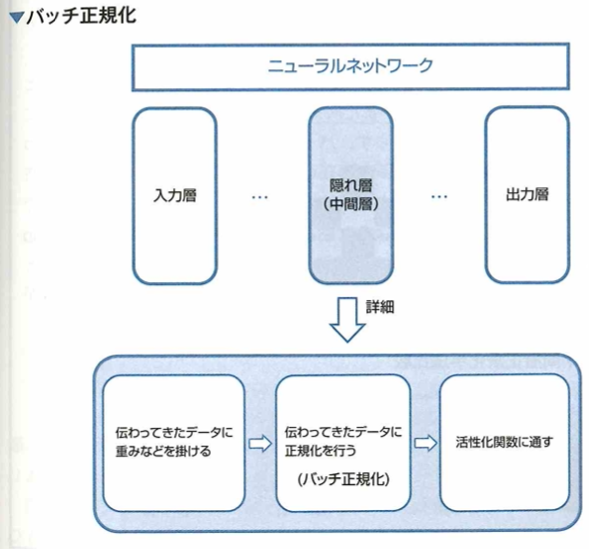
学習において、重みの初期値に対する依存度を下げる効果が期待できます。他にも学習率を大きな値に設定しも、学習がうまく行きやすくなったりするなど、さまざまなメリットがあり、実際にバッチ正規化は多くのモデルで用いられています。
バッチ正規化には、その他の派生としてLayer Normalization、Instance Normalization、Group Normalizationがあります(図参照)。Cが特徴マップのチャネル、Nがミニバッチ数、H、Wが特徴マップのサイズです。グレーの部分が正規化を行う領域を示しており、バッチ正規化がバッチ方向に正規化しているのに対し、Layer Norm.は1サンプルに対しての全特徴マップでの正規化、Instance Norm.は1特徴マップに対しての正規化、Group Norm.はグループ分けした数チャネルに対しての正規化です。
以下の本節の最後の内容は発展事項になります。G検定の合否には関わらない難易度と推測されます。
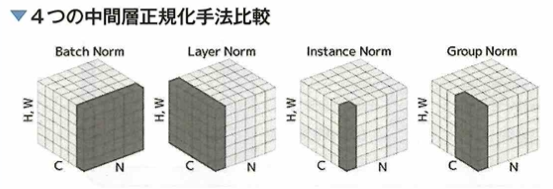
バッチ正規化は、バッチ数が少ない場合での学習では粗い統計量(平均と分散)を使うためノイズに弱く、また時系列を扱うRNNにおいては各時間に対して統計量が異なるにも関わらず、バッチで扱うのは好ましくないとされています。Layer Norm.は1サンプルにのみ集中することでRNNのような時系列を考慮するモデルに使われます。Instance Norm.は特徴マップレベルへ細分化が必要なStyle Transferのような生成系のモデルで使われます。Group Norm.はグループに分けるバランス調整をする必要がありますが、LayerとInstanceを合わせて使うことで、バッチ正規化よりも精度向上を狙うことができます。
CNN:畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワークについて考えます。画像データと数値データの大きな違いの1つに、次元の違いがあります。画像データは縦横の2次元のデータであると考えられ、さらに色情報(RGBなど)が追加されると数値情報としては3次元のデータとなります。通常のネットワーク(多層パーセプトロン)では、この画像データを入力する際に縦横に並んでいる画像を分解して、1次元に並び変えるように変形することでネットワークに入力できる形にする必要があります。したがって、この変形の段階で画像データから画像に映っている物体の位置情報が失われてしまいます。そこで、これらの情報を維持できるように考えられたのが、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)です。CNNでは、画像を崩すことなく、2次元のまま入力に用いることができます。したがって、画像に映っている物体の位置情報の情報が維持されるため、通常のニューラルネットワークに比べて精度の向上が期待できます。
画像データには他の種類のデータと比べて特徴的な部分があります。画像データからその画像に映っているものの特徴量を学習するには、一つ一つのマスを個別に扱うのではなく、複数のマスの領域から得られる情報を学習することが大事です。位置情報が失われてしまう問題を解決するには、CNNでは畳み込み演算処理を用います。これを用いると画像を2次元データのままネットワークに入力して学習・推論を行うことができます。
畳み込み演算のイメージ
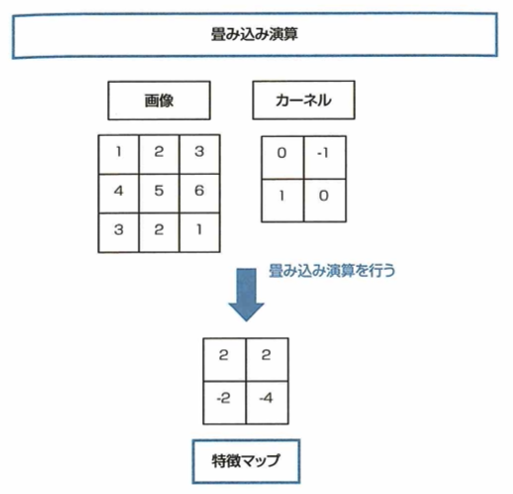
畳み込みニューラルネットワークでは、畳み込みと呼ばれる処理を利用して画像内の一定の領域から情報を得て学習を行うことができます。 畳み込みではカーネルやフィルタと呼ばれるものを用いて計算を行います。具体的にはカーネルを画像の左上から順番に画像上をスライドさせながら移動していき、各領域における画像の値とカーネルの値との積の総和を取っていくという処理になります。 次の画像とフィルタにおいて、畳み込み処理を行っていく場合、(A)の値はカーネルと画像が重なる4ピクセルの領域から計算される値2であることがわかります。 このように畳み込みでは一定の領域を考慮して計算を行うことができます。 畳み込みニューラルネットワークではこの図におけるカーネル内の値をネットワークの重みとすることで、よりうまく画像の特徴が抽出できるように学習が進んでいきます。
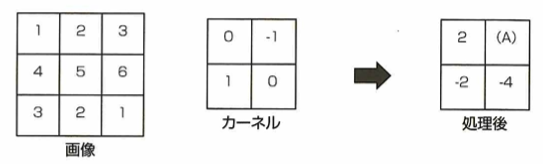
この問題については、求める箇所が、元画像の右上の4つのマスに、カーネルを重ねることにより、(2,3,5,6)と(0,-1,1,0)の内積を考えて2となります。
CNNがどのような値をニューラルネットワークの重みとして学習するか
CNNでは畳み込み演算を用いて画像を2次元のままニューラルネットワークに通して学習を行えます。畳み込み演算は、2次元の入力から新たな2次元の出力を得るものと考えられ、このように得られた新たな2次元の出力を特徴マップと言います。
畳み込み演算において、同じ画像が出力された場合でも、カーネルの中の数値が異なると、特徴マップは異なるものが得られます。そのためCNNでは、畳み込み演算によって得られる特徴マップの中に、入力画像に映っている物体の特徴がうまく抽出されるように、カーネルの中の数値を学習によって最適化します。
カーネルサイズやストライド、パティングは学習前に人の手で決定されるパラメータ(ハイパーパラメータ)となります。実際のCNNでは、畳み込み層でこの畳み込み演算が行われますが、1層の中に複数のカーネルが含まれ、カーネルの枚数と同じ枚数の特徴マップが生成されて次の層に伝播します。
ストライドとは畳み込み処理においてカーネルを移動させる幅のことです。パディングとは畳み込み処理前に画像に余白となるような部分を追加し、畳み込み処理後の特徴マップのサイズを調整するものです。
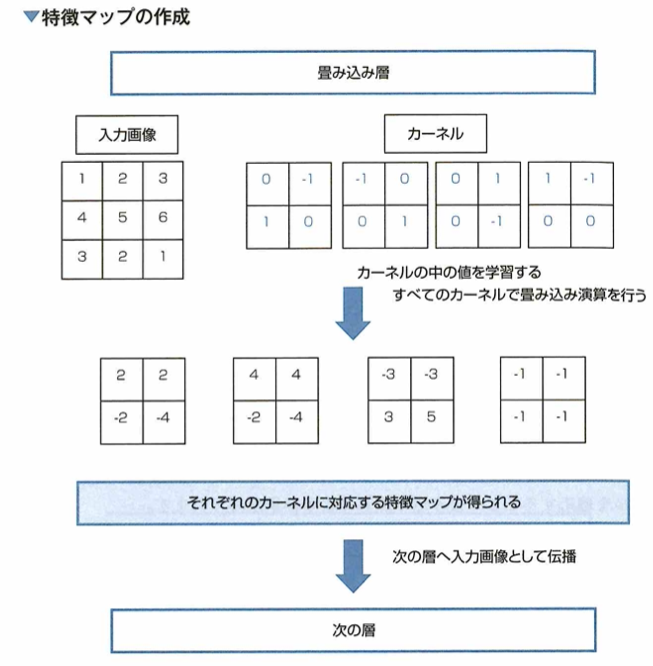
プーリング処理
CNNでは畳み込み演算と組み合わせてプーリング処理も行われます。プーリングは画像や特徴マップなどの入力を小さく圧縮する処理で、圧縮する方法には特定サイズの領域ごとに最大値を抜き出す方法や、平均値をとる方法などがあります。
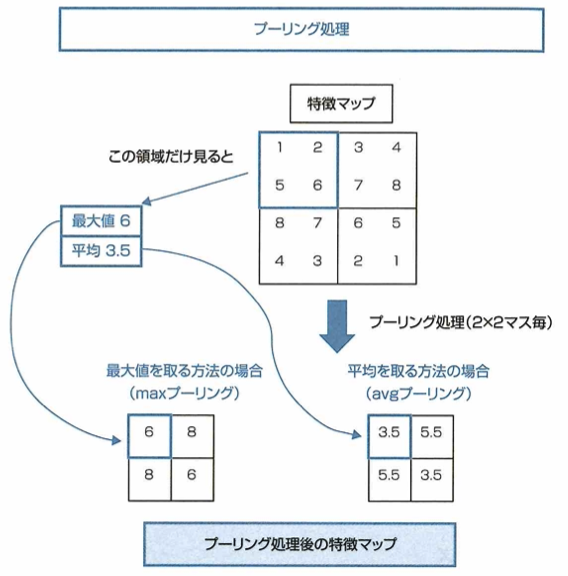
プーリング処理を行うと次の2つの特徴マップは同じマップに変換されます。
ここでは2×2の領域ごとにmaxプーリングを行うとします。プーリング処理によりニューラルネットワークが画像に映っている物体に僅かに物体の位置が変化するといった違いが生じても、同じ特徴量を見つけ出すことができるようになると期待できます。このような物体の位置が変化するといった違いに対する不変性は、CNNにおいて畳み込み層でも獲得することができますが、プーリング処理を行うプーリング層には学習によって最適化されるパラメータが存在しないという特徴があります。
プーリング処理は、特徴マップをより小さな特徴マップへと圧縮します。その中でわずかな位置の違いを含む特徴マップは、先ほどの例のようにプーリング処理によって位置の違いが吸収されてしまうことになります。このため、モデルが画像に映っている物体のわずかな位置の違いを過学習してしまう問題を防ぐことになり、これらの違いを含むデータセットに対して精度が上がることが期待できます。また、プーリング処理は、あらかじめハイパーパラメータとしてどのようなサイズでプーリングを行うかを手動で決定しますが、その後のプーリング処理は「最大値を取る」「平均値を取る」などの決まった計算で実現できます。このためプーリング層は学習によって最適化されるパラメータ(重み)を持っていません。
全結合層
CNNに用いられる全結合層について考えます。CNNでは、入力画像が複数の特徴マップとなり、畳み込み層やプーリング層を伝播していく構造をしています。この構造を局所結合構造といいます。 ここで入力が画像であった場合、特徴マップは入力画像と同じような2次元の形をしていますが、次の犬と猫を分類するモデルの例のように、入力画像に対応付けられている正解ラベルは、1次元の形をしています。 そのため出力層において正解ラベルと特徴マップを比較することができず、パラメータを最適化するために必要な誤差が計算できません。 このような問題を解決するために、基本的なCNNでは特徴マップを1次元の数値に変換したのち、全結合層に接続するといった構造を持っています。 したがって、CNN全結合層の説明として正しいものは多層パーセプトロンに用いられている層と同じ構造をしているです。
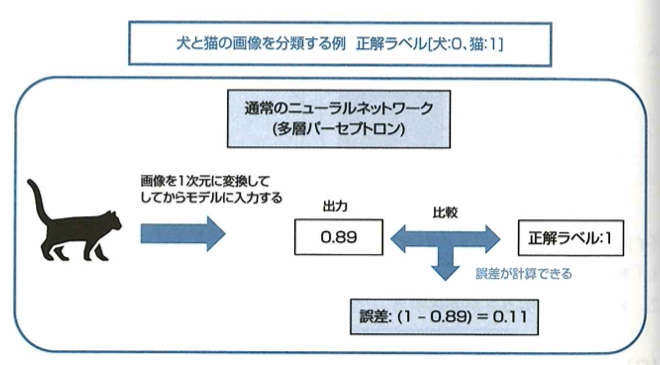
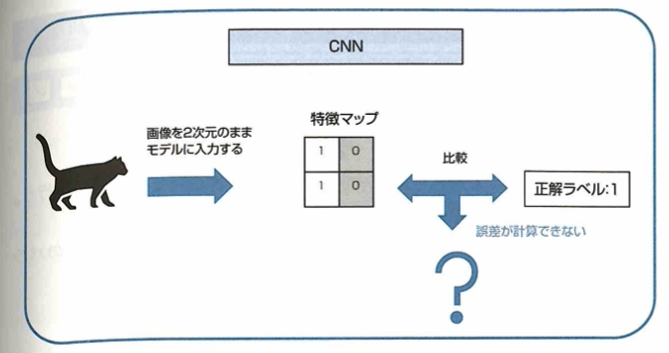
全結合層は、CNNではない通常のニューラルネットワーク(多層パーセプトロンなど)に用いられている層と同じ構造をしています。データの全領域を使う全結合層において、畳み込みがデータの局所領域を用いて特徴抽出を行う構造であるため、CNNの畳み込みのような構造を局所結合構造と言います。
Global Average Pooling
畳み込みニューラルネットワーク(CNN)において、Global Average Poolingという手法が使われることがあります。Global Average Poolingとは、分類したいクラスと特徴マップを1対1対応させ、各特徴マップに含まれる値の平均を取ることで誤差を計算できるようにする手法です。この手法を使うことで、全結合層のみを使う場合と比べてモデルの持つパラメーター(重み)が少なくなるということに繋がるため、過学習が起きにくくなる等のメリットが得られます。
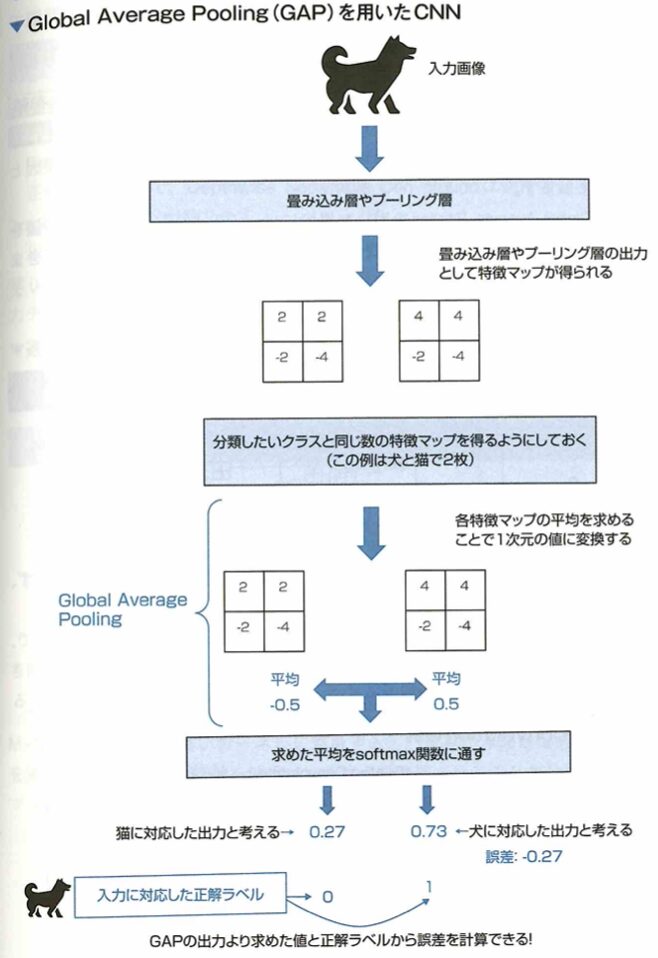
このGAPという手法は、特徴マップと分類したいクラスを1対1対応させる手法です。ここで補足として、Global Average Poolingを行う前に、特徴マップの数と分類したいクラス数を特に合わせたりせずに、GAPを行った後に全結合層を付けることで、分類したいクラス数と出力の数を合わせる方法もあります。特徴マップを1次元に並べるように展開し、全結合層に接続した場合、全結合層では、特徴マップが持っていた値に比例する数のパラメータを持つことになります。多くの場合には非常に多いパラメータ数となり、過学習などの原因となってしまいます。一方、Global Average Poolingを用いた場合には、このような特徴マップの値をすべて使用して全結合をすることがなくなるので、パラメータ数を削減できます。このようにパラメータ数が削減されることで過学習の軽減などに繋がります。
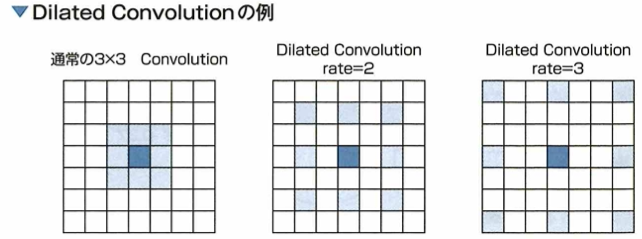
Dilated Convolution
Dilated Convolutionについて、通常のConvolutionのカーネルに隙間のような間隔をあけて畳み込みを行うことにより、広範囲の情報を取得できます。Atrous Convolutionと呼ばれることもあります。カーネルの隙間の間隔はハイパーパラメーターで設定されます。
Direted Convolutionはカーネルのパラメータ数は変わらず、カーネルの間隔を広げることで広範囲の情報を畳み込みます。以下の図では、色が塗られている部分が畳み込みの見る部分で、中心が青色です。この畳み込みの見る範囲はrateの数だけ間隔が開きます。このrateという感覚はハイパーパラメータにより決められます。この方法はAtrus Convolutionとも呼ばれます。
Depthwise Separable Convolution
Depthwise Separable Convolutionについて、通常の畳み込み層を空間方向とチャネル方向の2つの畳み込みに分解することでパラメータ数を減らしました。
Depthwise Separable Convolutionは通常の畳み込み層を2つの畳み込み層に分解します。以下の図での通常の畳み込みはMチャネルの入力に対して、M枚のカーネルを出力チャネルN個分用意します。
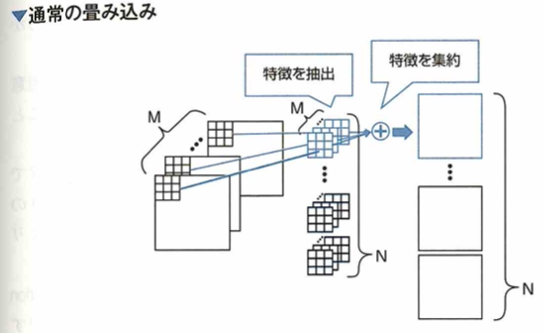
今回の例ではカーネルサイズが3×3なので、この畳み込みは3×3のカーネルがM×N個存在します。青いカーネルに着目して、畳み込み層はM個のカーネルを通して各チャネルの特徴を抽出し、それらを集約させることで1つの出力特徴マップが得られます。
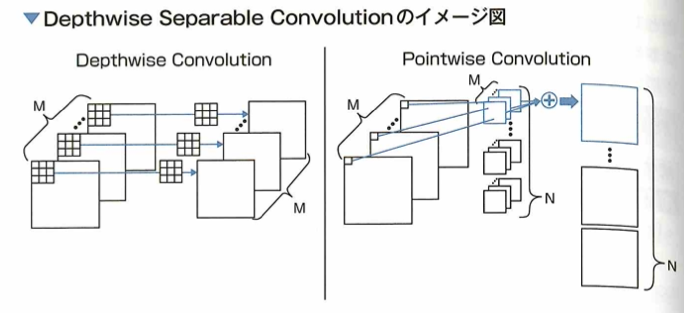
それに対して Depthwise Separable Convolution は、通常の畳み込み層を Depthwise Convolution と Pointwise Convolution の 2 つに分解したものです。Depthwise Convolution は空間方向の畳み込みと解釈でき、M チャネルの入力から各チャネルの特徴を取り出します。通常の畳み込み層と異なる点は、入力のチャネル数と同じ数のカーネルを用意して、抽出した特徴を集約しない点です。これにより空間方向の特徴を得ることができます。もう一方の Pointwise Convolution は、チャネル方向の畳み込みと解釈でき、1×1 Convolution を使います。例のように M チャネルの入力に対して 1×1 の Convolution をして得た特徴マップを集約して 1 つの出力とします。これによりチャネル方向の特徴量の集約ができます。
Depthwise Separable Convolution は、Depthwise Convolution の後に Pointwise Convolution を行う構造になっています。通常の畳み込み層のパラメータ数は 3×3×N×M ですが、Depthwise Separable Convolution は 3×3×M + 1×1×N×M = (9 + N) × M となり、パラメータ数を削減することができます。これを使ったモデルとして MobileNet というものが提案されました。
Dilated (Atorus) Convolution は通常の畳み込み層のカーネルの間隔を広げて活用することで、より広い範囲を見るように工夫することです。VGG という CNN モデルでは、通常の畳み込み層のカーネルサイズを3×3または1×1の小さなもののみにして層数を増やすことで性能向上をします。バディングとは、畳み込み層の後の特徴マップが小さくなるのを防ぐため、入力のマップの周りを0や1などの値で埋めることです。
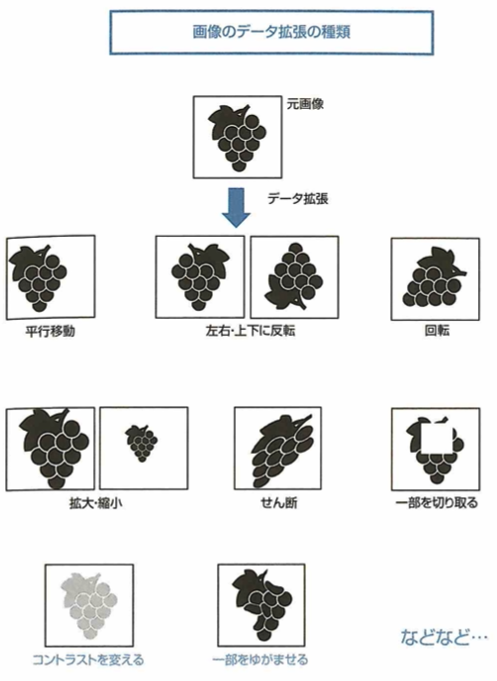
データ拡張
画像データを用いてニューラルネットワークを学習する際に、画像に人工的な加工を行うことでデータの種類を増やせます。具体的な処理は次の通りです。
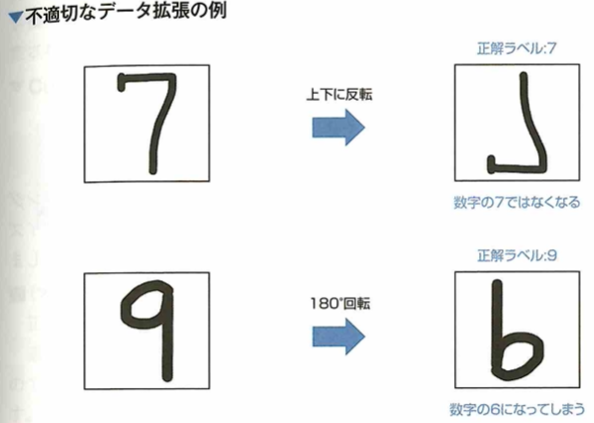
ここで手書き数字0〜9が映っているデータセットに対してデータ拡張を考えます。ただし画像1枚に対して1文字のみ映っています。このようなデータセットに対して、正解ラベルが6や9のデータに画像を180°回転のような変換を行うことは不適切です。
このような問題の時は、意味のない画像や別の数字として見た方が正確な画像に変換されてしまう場合があります。下記の図では上下斑点の例ですが、「3」は問題ありません。しかし「3」の左右反転は不適切です。このようなデータ拡張を行う際は、データ特徴を意識して、どのような変換を行うか選択する必要があります。
データ拡張の手法
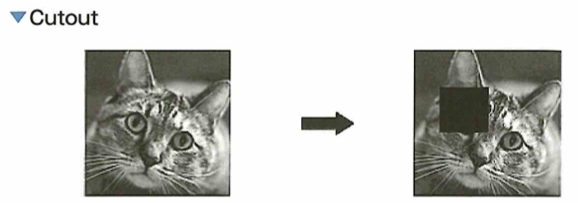
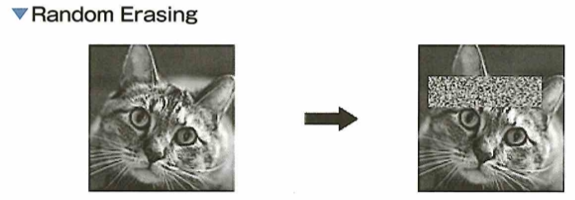
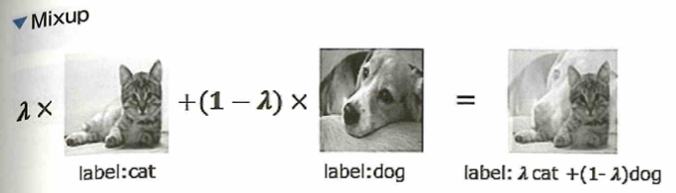
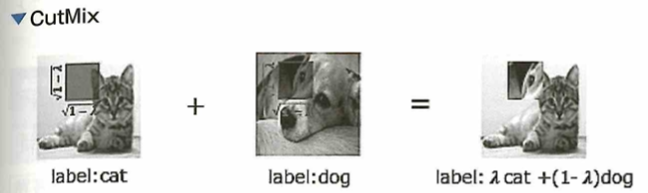
画像に関してのデータ拡張(Data Augmentation)はさまざまな手法が提案されています。たとえば、画像の左右または上下を反転させるフリップや、画像を拡大または縮小するなどがあります。その他にも、手法の1つに画像中のランダムな場所を値の0の正方形領域で削除するcutoutがあります。この手法により一部を失った画像で学習できるため、よりロバスト(頑健)なモデル作成が可能となる。また、ランダムな場所を固定値、もしくはランダムノイズの長方形領域で置き換えるRandom Erasingがあります。こちらもロバストな学習を可能にします。特に最近では2枚の画像をそれぞれランダムな比率で混ぜ合わせるMixupという手法があります。この手法は教師ラベルも同じ比率で混ぜて複数クラスの画像認識との学習を行います。さらに、この手法の派生として、画像のランダムな位置を別の画像で置き換えるCutMixという手法も提案されました。こちらも教師ラベルを置き換えた画像の比率で混ぜ合わせます。どちらの手法も深層学習においてパフォーマンスの向上に成功しました。これらの画像に対するランダムなデータ拡張は学習に対して過学習の抑制が期待できます。
速い収束性については、データ拡張により必ずしも期待できません。メモリの削減については、関係がありません。モデルのスパース化とはモデルのパラメータが0に近い値が多くなることを指しますが、データ拡張でスパース化が起きるとは限りません。
Neural Architecture Search(NAS)
ディープラーニングの発展に伴ってさまざまなモデルが提案されてきました。VGGやResNetはその中でもより深い多層なモデルとなっており、多層にすることで高精度を得られることが実験により示されてきました。しかし、多層にすることでパラメータが増え、モデルの自由度が上がることで汎化性能が下がってしまう問題も同時に存在しました。これまでは正則化項を追加したりすることで汎化性能を上げたり、ハイパーパラメータチューニングをして精度を向上させてきました。それに対してニューラルネットワークの層の数や層の幅といった、アーキテクチャ自体を最適化することを目的とした研究が、昨今盛んに行われています。これをNeural Architecture Search (NAS)といいます。
NASは最適なモデルのアーキテクチャを自動で探索するタスクです。探索方法は様々で、CNNに限定した探索手法ではNASnetやMnasNetなどがあります。
グリッドサーチはハイパーパラメータの探索手法です。ファインチューニングは事前学習したモデルを別のタスクで再学習することです。スクラッチ開発はプログラムを1から書いて開発を行うことです。
NASによるモデル
NASは、モデルの構造自体を自動で探索する研究です。2017年にNASNetと呼ばれるCNNのみに焦点を当てたNASが提案されました。これは畳み込み層のみに注力して最適な構造を探索しました。また、最近ではMnasNetと呼ばれる強化学習の概念を使って、モバイル用の高効率で高精度なモデルも提案されました。これは強化学習の際に実際にモバイル端末を使って評価することで、モバイル用の最適なモデルを探索したものです。その他にも、モデルの深さ、広さ、解像度(入力画像または特徴マップのサイズ)のスケールアップのバランスを重視して探索されたモデルが提案されました。これはNASによりベースとなるモデルを決定し、ベースモデルのスケールアップによる性能の変化を研究することで、各スケールの最適な広げ方を求めました。このモデルをEfficientNetと言います。従来のモデルと比べてとても少ないパラメータ数で、かつシンプルな構造で高精度を出しました。
NASNetは、CNNのみに焦点を置いて探索されたモデルです。従来では探索する範囲が広すぎて最適モデルを見つけることが困難でしたが、畳み込み層に注力して最適な構造を探索することにより、少ないパラメータ数で高精度なモデルを見つけることに成功しました。
MnasNetは、強化学習の考え方を取り入れ、モデルの精度とモバイル端末上での実際の実行速度を見ながら、より良いモデルを探索したモデルです。次の図に探索のフロー例を示します。
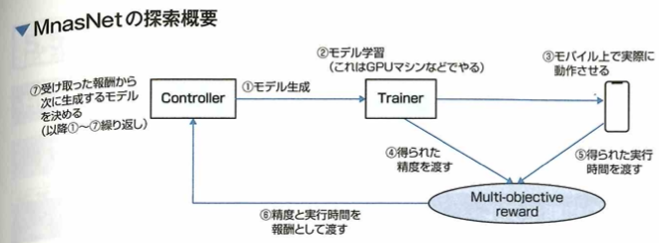
最初にControllerがモデルを生成し(①)、モデルの学習をします(②)。その学習したモデルをモバイル端末上で実行したときの時間とモデルの精度を、Multi-objective rewardに渡します(③④)。それぞれの結果を見て報酬をControllerに渡し(⑤)、次に生成するモデルを決めます。この手順を繰り返すことで高速で高精度なモデルを生成するControllerができます。
EfficientNetは、深さ、広さ、解像度のスケールアップのバランスを重視して探索したモデルです。構造自体もシンプルでかつ従来の高精度モデルよりもパラメータを少なくして、性能向上することに成功しました。現在ではEfficientNetをベースとした新たなモデルでEfficientNet v2なども提案されています。
転移学習とファインチューニング
転移学習について考えます。ニューラルネットワークを学習する目的は、予測を行いたい問題に対して最適なパラメータの値を計算することです。したがって、目的の問題に対して理想的なパラメータが分かっていれば、ネットワークの学習を行う必要がなく、モデル作成の時間短縮に繋がります。ここで画像認識などの分野では、さまざまな問題に対して共通する特徴が存在する場合が多いです。そのため学習済みモデルを利用し、これらのモデルに新しく何層か付け足したものを調整するということが行われています。このように学習済みのネットワークを利用して、新しい問題に対するネットワークの作成に利用することを転移学習、またはファインチューニングといいます。特に付け足した(または置き換えた)層のみを学習するときは転移学習といい、利用した学習済みモデルに含まれるパラメータも同時に調整するときはファインチューニングといいます。基本的にニューラルネットワークでは、次のように入力層付近においては画像に含まれる抽象的な特徴量を学習し、出力層付近においては具体的な特徴量を学習することで知られています。
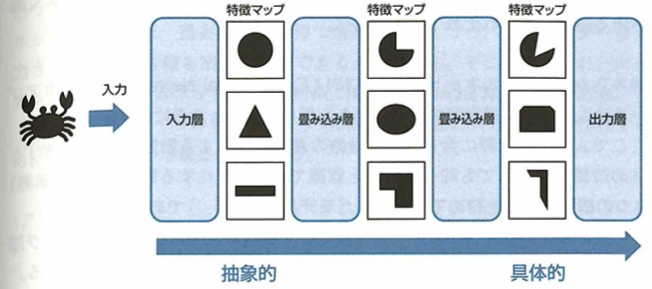
このため、画像データを用いるモデルで転移学習やファインチューニングを行う際は、学習済みモデルにおいて出力層の後に新たな層を追加したり、この層を置き換えて調整を行うと効果的であると考えられます。一方で利用元のモデルと転移先のモデルでデータの種類(ドメイン)の関連性が低い場合では、転移学習やファインチューニングを行うのは不適切であり、精度が逆に悪くなってしまうというような問題が発生する可能性があります。
学習済みネットワークにおける入力層に近い層のパラメータはさまざまな画像の分類問題に応用が効きます。そのためこの部分はそのまま利用し、出力層の後に新たな層を追加したり、出力層を置き換えて調整することで目的の問題に対応させると効果的です。転移学習のメリットは、学習用のデータが少ない場合でも、十分なデータがある問題で学習したモデルで学習したモデルを利用することで、より精度を向上させることが期待できますが、転移学習を行う際には、学習に用いられるデータの特徴を理解しておく必要があります。なぜならデータに共通性が少ない場合では、逆に精度が落ちてしまうからです。
CNNの基本となった初期モデル
畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)のアプローチは人間が持つ視覚野の細胞の働きを模したものであります。ここで人間の視覚野に含まれる、画像の濃淡を検出する細胞(単純型細胞)と物体の位置が変動しても同一の物体と認識できるようにする細胞(複雑型細胞)の2つの細胞の働きを初めて組み込んだモデルはネオコグニトロンです。その後、1998年にヤン・ルカンによって考えられた畳み込み層とプーリング層(サブサンプリング層)を交互に組み合わせたCNNのモデルはLeNetです。
単純型細胞(S細胞)と複雑型細胞(C細胞)の働きを最初に組み込んだモデルは、福島邦彦により1979年に提唱されたネオコグ二トロンです。これはS細胞層とC細胞層を交互に組み合わせた構造で、勾配計算を用いないadd-if silentという方法により隠れ層(中間層)の学習が行われます。LeNetとは1998年にヤン・ルカンによって考えられた畳み込み層とプーリング層を交互に組み合わせたCNNモデルです。この2つのモデルを比べると、2つのモデルは同じ構造をしており、S細胞と畳み込み層、C細胞とプーリング層がそれぞれ対応しています。
RNN:リカレントニューラルネットワーク
RNNの構造
リカレントニューラルネットワークについて考えます。画像データはピクセル間の関係性が重要であり、このようなデータはCNNが有効でした。文章のようなデータから特徴を取り出すためには、ニューラルネットワークを新たな構造にする必要があります。文章では、ある単語がその単語の前後に繋がる単語と深い関係性を持っており、さらにその並び順が非常に重要な意味を持っています。このようなデータを時系列データといいます。ここで時系列データからうまく特徴を取り出すためには、データを時系列に沿って順番にニューラルネットワークに入力できると良いです。このニューラルネットワークでは、過去の入力が持つ情報を保持しつつ、これらのデータが入力された順番の情報を出力に反映できる必要があります。そこで考えられたのがリカレントニューラルネットワーク(RNN:Recurrent Neural Network)です。リカレントニューラルネットワーク(RNN)は、過去の入力の情報を保持するために過去の入力による隠れ層(中間層)の状態を、現在の入力に対する出力を求めるために使うという構造をしています。
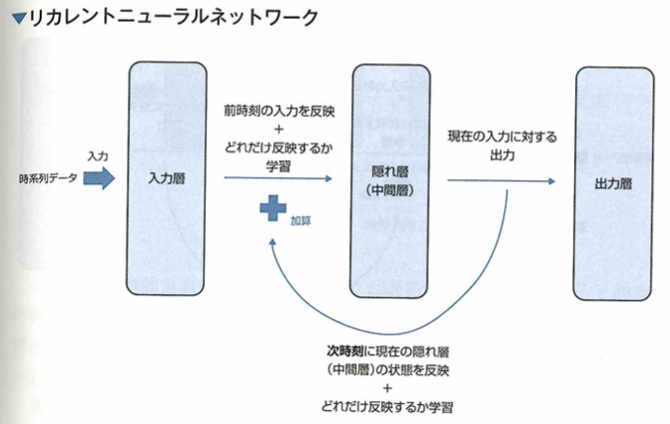
RNNでは現在の入力とそれまでの入力がそれぞれどれくらい現在の出力に影響するかを学習できます。過去も入力の情報が現在の入力に影響を与えることができる構造で、RNNは時系列データの処理に適しています。RNNは誤差を計算する際に、過去の入力に遡って計算していく必要があります。このように計算する方法を通時的誤差逆伝播(BPTT:BackPropagation Througu Time)と言います。
RNNで発生する勾配消失問題
リカレントニューラルネットワーク(RNN)における勾配消失問題について考えます。多層パーセプトロンやCNNにおいては、層が深くなると勾配消失によって入力層付近ほど学習ができなくなるといった課題がありました。ここで時系列データを用いてRNNの学習を行うときは、過去の時系列をさかのぼりながら誤差を計算する通時的誤差逆伝播(BPTT)を用いて勾配が計算されますが、このとき、計算される勾配に対して時系列の古いデータほど勾配消失しやすい特徴があります。
RNNではネットワークは時間方向に深いものとなります。
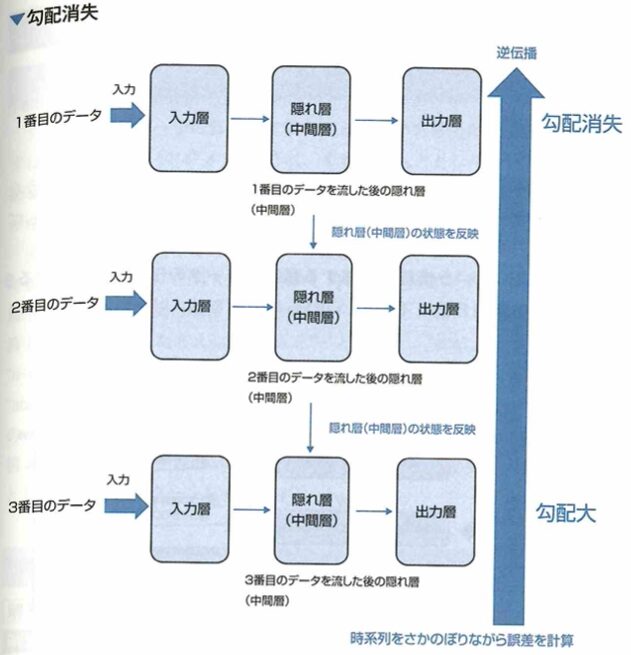
時系列の古いデータの部分で勾配が消失してしまいやすいです。同様に、時系列の古いデータ部分においては、勾配が大きなりすぎてしまう勾配爆発の問題も起きやすいです。
LSTM
RNNの一種であるLSTM(Long-Short-Term Memory)について考えます。RNNは再帰的な構造を持つことにより、過去の入力の状態が現在の出力に影響を与えることができます。もし過去の情報が現在の入力と組み合わせて重要な意味を持つ場合、過去の情報の重みが大きいと考えられます。一方、過去の情報が現在の入力に対してあまり意味を持たない場合は、過去の情報の重みは小さくなります。ここで問題となるのは、現在の入力に対し過去の情報はあまり関係がないが、将来的に重要な情報となる場合です。すなわち、現在の入力に対して過去の情報の重みは小さくてはならないが、将来のために大きな重みを残しておかなければならないという矛盾が生じます。このような問題が、新しいデータの特徴を取り込みときや、隠れ層(中間層)の状態を踏まえて結果を出力するときに発生することを、それぞれ入力重み衝突、出力重み衝突といいます。この問題を解決するために考えられたものが、LSTM(Long Short-Term Memory)です。LSTMは勾配消失の問題や入力重み衝突・出力重み衝突課題を解決するために考えられました。LSTMが持っている構造としてCEC(Constant Error Carousel)という情報を記憶する構造と、データの伝搬量を調整する3つのゲートを持つ構造となります。
入力重み衝突とは、現在の入力に対し、過去の情報の重みは小さくなくてはならないが、将来のために大きな重みを残しておかねばならないという矛盾が、新しいデータの特徴を取り込むときに発生するもので、出力重み衝突とは、現在の入力に対し、過去の情報の重みは小さくなくてはならないが、将来のためにお大きな重みを残しておけねばならない矛盾が、現在の状態を次時刻の隠れ層(中間層)へ出力するときに発生することです。
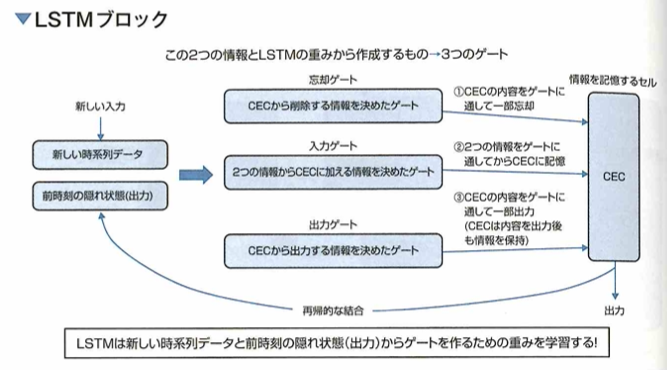
3つのゲートを持つ構造と情報を記憶するセルの構造のセットはLSTMブロックと言います。実際のLSTMでは隠れ層(中間層)にこのLSTMブロックが複数個並んでいます。このLSTMブロックの構造において、忘却ゲート、入力ゲート、出力ゲートがあります。これらのゲートと情報を記憶するセル(CEC)により、LSTMは重要な情報を必要なタイミングで利用したり、不必要になった情報削除のタイミングをコントロールできるようになります。CECにゲートを介して情報をやり取りする構造のおかげで、逆伝播の際に勾配消失の問題も起きにくくなります。
LSTMやRNNなどの学習における損失関数の1つとして、Connectionist Temporal Classification (CTC) lossというものがあります。例えば、スピーチの音声を文章化するタスクを考えたときに、学習音声データは単語毎に分割(セグメント)させ、それらを入力としたネットワークの出力とその単語ラベルの損失が計算されますが、これだと最初のデータの分割にコストがかかってしまいます。そこで、CTC lossはそのセグメントなしで学習することができる損失関数として提案されました。CTC lossはblankと呼ばれる空文字が出力されることと、連続して同じ単語が出た場合は1つに集約する(例えば、“aaabcc”は“abc”)ことを許します。これを例えば、blankを“_”とすると、“abc”という単語=“ab_ccc”、a_bb-c-、“aaabcc”などが同じ意味であることを示します。CTC lossはラベル“abc”に対して“ab-ccc”、a-bb-c-、“aaabcc”、など同じ意味となる単語のすべてのパターンを使って損失を計算できるため、セグメントせずとも入力の時系列と答えのタイミングを合わせることができます(この例では、出力単語の長さを7としてすべてのパターンを考えます)。
GRU
リカレントニューラルネットワーク(RNN)の一種であるGRU(Gated Recurrent Unit)について考えます。RNNには情報を記憶するためのセルと3つのゲートの構造を持つLSTMがあります。LSTMはRNNの勾配消失の問題と、入力重み衝突・出力重み衝突の問題を解決するのに貢献しましたが、一方でLSTMには計算量が多いという問題がありました。そこでLSTMを軽量化したモデルの1つがGRU(Gated Recurrent Unit)です。GRUはLSTMと同じようにゲートを用いた構造のままパラメータを削減し、計算時間が短縮されています。具体的な構造としてGRUはリセットゲートと更新ゲートという2つのゲートを用いた構造を持つブロックの組み合わせによって構成されています。
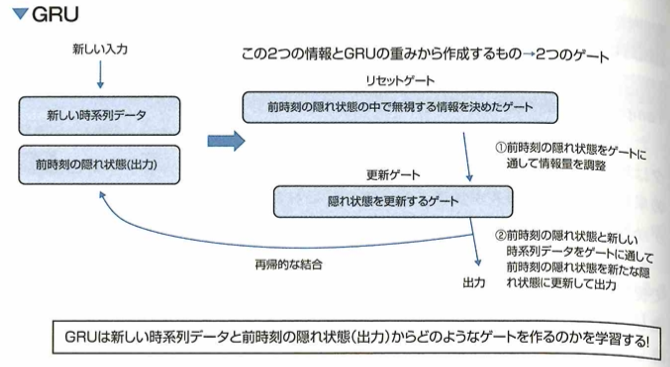
実際のGRUでは、このような2つのゲートを持つ構造のブロックを隠れ層(中間層)に複数個並べることで構成します。GRUはLSTMが持つ情報を記憶するセルのような構造を必要とせず、よりシンプルな構造をしています。
双方向RNN
RNN(BiRRN:Bidirectional RNN)は2つのRNNが組み合わさった構造で、一方はデータを時系列通りに学習し、もう一方は時系列を逆順に並び替えて学習を行います。このような時系列データの特徴を双方向から捉える構造によるメリットは過去と未来の両方の情報を踏まえた出力ができることです。
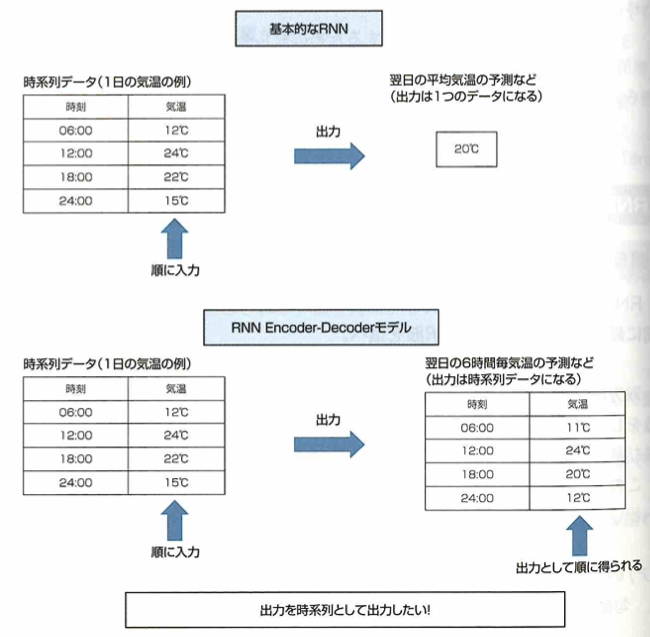
Encoder-Decoderモデルとsequence-to-sequenceの問題
RNNを応用したRNN Encoder-Decoderと呼ばれるモデルについて考えます。これまでのRNNは時系列データから1つの予測を出力するものです。一方で、入力の時系列に対して出力も時系列として予測したい問題もあります。このような問題をsequence-to-sequence(seq2seq)と言います。このsequence-to-sequence問題を解決するためにRNN Encoder-Decoderが考えれられました。これまでのRNNとの出力の違いは下図です。
このような時系列での出力を得るためにRUN Encoder-Decoderモデルでは、エンコーダ(Encoder)とデコーダ(Decoder)と呼ばれる2つのRNN(LSTMなど)から構成されます。ここでエンコーダは入力される時系列データから固定長のベクトルを生成します。その後に、デコーダでは固定長のベクトルから時系列データを作成します。
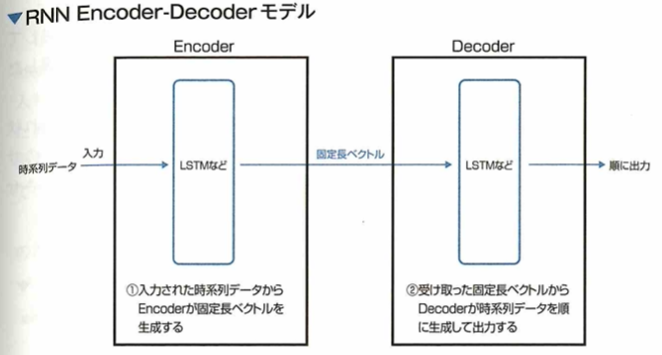
Encoderの出力は、最後の隠れ層(中間層)の状態です。これらの情報は固定長のベクトルなので、Encoderは任意の長さの時系列データを固定長のベクトルに圧縮していると考えられます。
Attention
Attentionについて考えます。seq2seqの問題に対応したモデルとしては、RNNのEncoder-Decoderモデルがあります。しかし、このEncoder-Decoderモデルでは、Encoderによって時系列データを固定長のベクトルに圧縮しなければなりません。したがって、長い時系列データが入力されたときなどで固定長のベクトルの中に情報が入りきらないといった問題が発生してしまいます。このような問題を解決できる手法としてAttentionと呼ばれるものがあります。Attentionとは、入力データと出力データにおける重要度のようなもの(アライメント)を計算する手法であり、seq2seqのモデルに用いた場合は「入力の時系列データ」と「出力の時系列データ」の各要素間で対応するものを選択するようなイメージになります。すなわち次の図のように、Decoderである時刻のデータを生成する際に、Encoderに入力された時系列データの中から影響力の高いデータに注意を向けるということです。
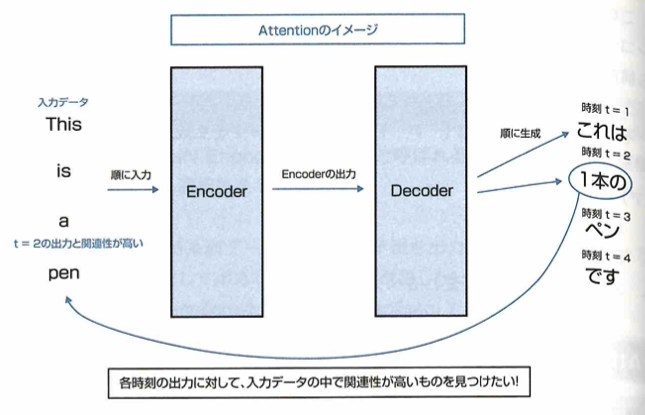
ここでAttentionを持つEncoder-Decoderモデルではこのような動作を実現するために、encoderは隠れ状態を時刻ごとに出力してDecoderに渡しています。このことからAttentionの動作は時系列データにおいては「過去の入力のどの時点がどれくらいの影響を持っているか」を直接的に求めることでデータの対応関係を求めていると考えられます。
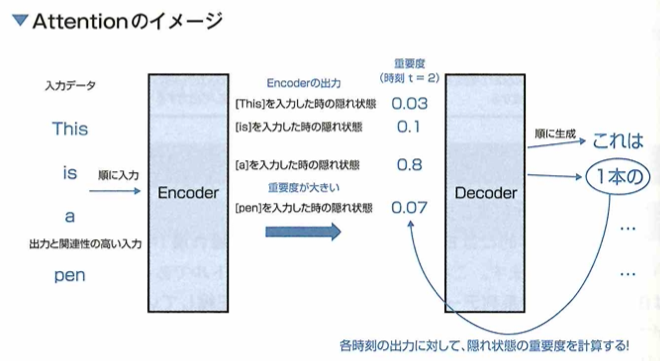
この問題におけるAttentionの手法は、soft Attentionのような、重要度を各時刻における隠れ層の状態(入力データの要素に対応)の重み付き平均を、デコーダでの推論に使用する手法を想定しています。 seq2seqに用いられるAttentionでは、各時刻のエンコーダの隠れ状態に対して出力に影響を与える重要度が計算されます。またデコーダでは重要度を考慮した隠れ状態を用いて入力データから新たな時系列データを生成します。 このような計算をするために、下図のようにEncoderはすべての時刻の隠れ状態を出力してDecoderに渡しています。したがってEncoderの出力は固定長のサイズに縛られることなく、入力となる時系列データのサイズに比例して変化させることができるようになっています。ここでEncoderの出力となる各時刻の隠れ状態には、その時刻に入力された時系列データの要素の特徴が多く含まれていると考えられます。そのため各時刻の隠れ状態は、その時刻にエンコーダに入力された要素とみなせます。ここでこれらの隠れ状態に対する重要度を求めることでAttentionは過去の入力のどの時点がどれくらいの影響を持っているかを直接的に求めていると考えられます。Attentionの手法には、self Attentionといった1つのデータ内での要素間の対応を計算するものなど、様々な手法が考えられています。
Transformer
量み込みや再帰的構造を使わず、完全にAttentionをベースとしたモデルとしてTransformerがあります。Transformerは通常のAttentionとself-Attentionの二つを組み合わせてEncoder-Decoderとし、時系列データの未来予測や言語の翻訳などタスクの精度を上げました。このAttentionとは、入力間の関係性を見ることができます。たとえば、「私/は/この/本/が/好き/。」と「I/lik/this/book/.」の2つの文章の関連を測ります。ここで「/」は各単語の区切りを意味します。この場合、「好き」と「like」の関連度が最も高くなりそうな予想ができます。self-Attentionとは、入力されるデータ自身でAttentionを計算するためselfという単語がついています。例えば、先程の例で、日本語文章自身のAttentionを取ると「好き」と関連度が高い単語は「本」となるなどといった、自身の文章内の各単語間の関連度を計算できるのです。Transformerは、この2つをEncoderに対してself-Attention、Decoderに対してself-Attentionと通常のAttentionを使った構造となっています。
TransformerはEncoder時にself-Attention、Decoder時にself-Attentionと通常のAttentionを使います。なぜならEncoderの入力には予測をするための元データを入れ、Decoderの入力はEncoderの出力と一時点前の予測結果を入れます。そのためEncoderは入力自体のみを使うself-Attentionで実装し、DecoderはEncoderの出力と予測を使う通常のAttentionで実装します。このときDecoderの一時点前までの予測結果に対しては、self-Attentionをします。 以下にすごくシンプルな構造に落とし込んだTransformerの例を示します。この例は「これは本です」を英語に翻訳する例です。
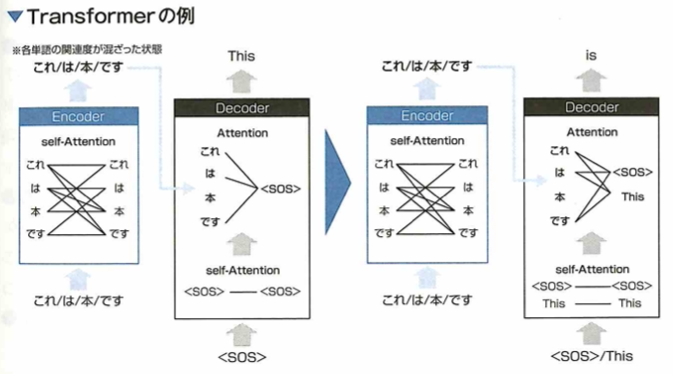
Encoderは入力「これは/本/です」の各単語間のself-Attentionを計算し、その出力はDecoderの途中部分に入力されます。Decoderでは「<SOS>」という最初の単語(Start of Sequenceの略)が入り、その単語のself-Attentionをします。そしてその出力とEncoderの出力に対してAttentionを取ります。これを経て「This」が予測値として出てきます。2単語目(図右半分)も同様の手順で、このときDecoderの入力には1つ前までのすべての予測値「<SOS>/This」が使われます。ただし、実際のTransformerは各Attentionを何度か通し、各単語の位置情報を付与する、単語間で数値計算ができるよう単語を数値ベクトル化するなどさまざまな工夫がされています。
Transformerは難しい概念ですね。
強化学習の特徴
強化学習の用語確認
強化学習では環境と学習目的を設定します。環境は状態、行動、報酬、推移確率などを内包します。行動主体であるエージェントが環境内で学習目的を達成するように、状態に対する最適な行動選択の学習を行います。また、行動選択の結果、エージェントは報酬を得ます。学習目的に近づく行動選択であったか報酬に基づいて評価することで行動選択を改善します。
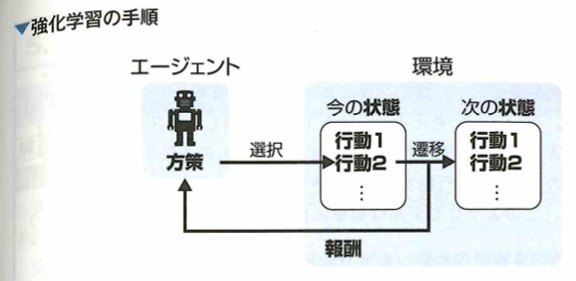
方策はエージェントが持つ行動選択のルールのことです。個々の行動によって得た報酬をもとに、一連の行動選択による報酬和を最大化する方策を求めることが強化学習のゴールです。
方策の学習
行動選択を行なった後に報酬が得られない環境でも方策が学習できます。例えば以後のように勝敗が決した状態に達した時のみ報酬が得られる場合です。このような報酬を疎な報酬と言い、学習には時間がかかります。
強化学習を用いて最適な方策を学習させることについて、意図した目的を達成するために、状態を必要十分に設定することは難しいです。また報酬の設定によって方策の学習結果が異なりますので、達成したい目的に合わせた報酬を設定しないと意図しないものとなることがあります。また、状態や行動の数が多い場合には、現実的な時間で状態と適切な行動を結びつけることが多いです。
深層強化学習
強化学習においてディープラーニングを用いる理由
深層強化学習について、ニューラルネットワークを用いて状態の重要な情報のみを縮約表現します。これにより状態数が多い問題に対しても強化学習が適用できるようになりました。
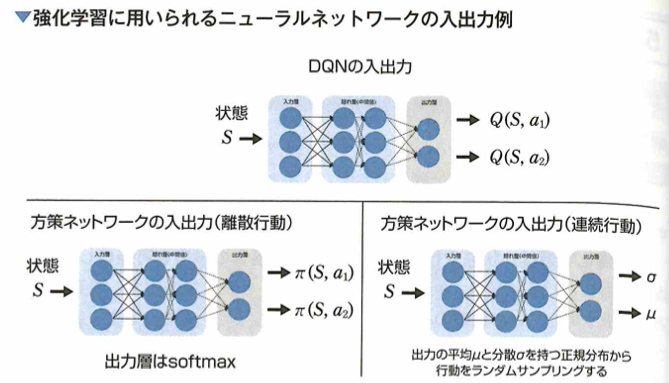
ディープラーニングを用いてなくとも、確率分布関数などで方策をパラメトリックに表現できます。Deep Q Network(DQN)という深層強化学習手法では、状態や行動の価値をニューラルネットワークで表現できますが、その価値の算出に報酬を用います。深層強化学習はあくまで強化学習の手法にニューラルネットワークを用いた手法です。強化学習では行動の組み合わせを直接学習しません。
Q学習
Q学習について考えます。Q学習とは、状態と行動の組に対してその後得られる報酬和の期待値(Q関数)を推定し、期待値が最大である行動を選択するアルゴリズムです。
Q学習は価値ベースの強化学習手法です。価値推定を行う部分と推定した価値を参考にして行動選択する部分に分かれます。状態sと状態aの組の価値を、状態s行動aを選んだ後、得られる報酬和の期待値で表現します。これをQ関数と呼びます。アルゴリズムSARSAではある状態sにおける行動aの価値であるQ関数Q(s,a)の推定値を求める計算では、次の状態s’において方策を用いて選択した行動a'のQ関数Q(s',a')が用いられますが、Q学習ではQ(s,a)の推定値を求める計算では、次の状態s'のQ関数のうち、最大の値を持つQ関数Q(s',a*)が用いられます。しかしQ値が最大である行動のみ選択すると、局所解に陥る場合があります。そこで一定の確率でQ値を無視した選択をします。Q値を参考にする行動選択を利用、Q値を無視した行動選択を探索と言います。探索と利用の間にはジレンマがあります。モンテカルロ木探索とは、ある状態から行動選択を繰り返して報酬和を計算するということを複数回行なった後、報酬和の平均値をある状態の価値とする価値推定方法です。TD学習とは、常態価値の推定において、直後に得られた報酬と次の状態の価値を用いる手法です。
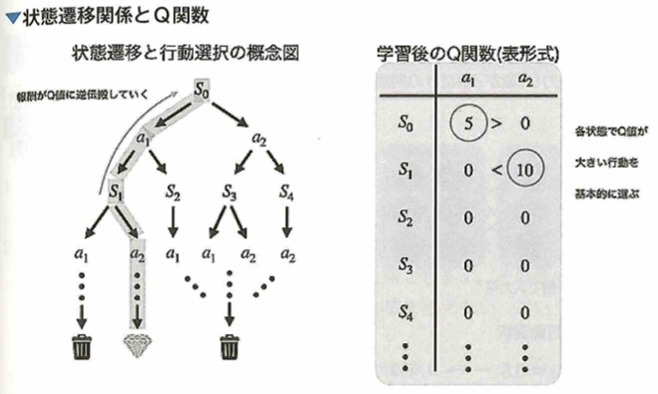
DQN
Deep Q Network(DQN)について考えます。ニューラルネットワークでは、入力に状態を表現するベクトルを受け取り、Q関数を近似します。行動選択などの制御はあらかじめ設定した方策によって行います。
このときの出力層の各ノードは各行動の価値になります。Q関数以外の行動選択の部分はQ学習と変わらないので、DQN学習はQ学習におけるQ関数の近似計算だけをニューラルネットワークで下請けさせるアルゴリズムです。方策勾配法系の強化学習のアルゴリズムでは入力に状態を受け取り、出力に行動(または行動をとる確率)を出力するニューラルネットワークです。Q学習における次の状態s’において最大の値をとるQ関数を用いることを方策オフ型の学習と呼び、SARSAのアルゴリズムでは方策オン型の学習と言います。
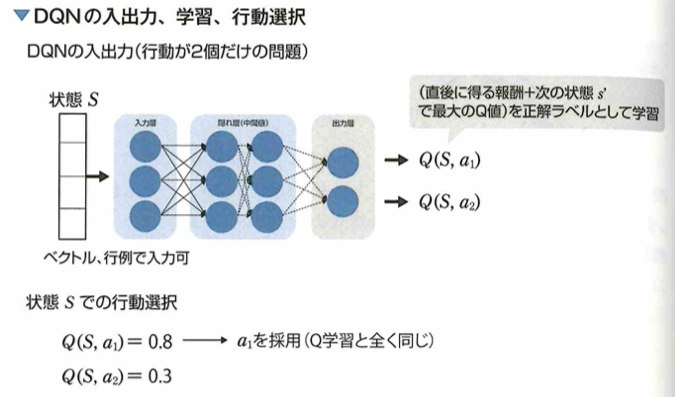
Double DQN
DQNを改良したDouble DQN手法について、強化学習において、多くの手法はデータのサンプリングを前提として学習が行われます。以下の図は、通常のDQNにおいて現状状態sで行動a_1を選択したときに得られた即時報酬rと、現状状態sと次状態s_1の状態行動価値(Q値)からDQNの損失関数を計算する過程を示しています。
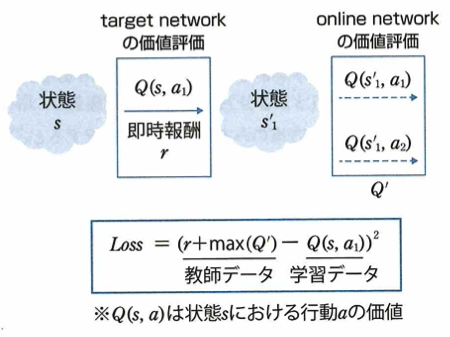
DQNはニューラルネットワークを用いてQ値を推論することで価値評価を行なっており、target networkのパラメータは学習を進めるのに従って変化します。ここで通常のDQNではtarget networkとonline networkは同じ重みを利用しています。一方で通常のDQNを改良したDouble DQNという手法は、価値評価に用いる2つのネットワークで違う重みを利用するようにした手法です。Double DQN手法において、2つの価値評価を異なるネットワークで行うことのメリットは偏ったQ値の過大評価を改善することができることです。
通常のDQNでは2つの価値評価を学習中の同じネットワークの出力でおこないますが、推論したQ値がノイズによって偏ると、偏ったQ値を過大評価してしまう問題があります。Double DQNでは、targetnetworkにonline networkとは別のノイズが乗ったネットワークを利用するので、ノイズによる過大評価を改善します。このときtarget networkにはonline networkの過去のパラメータを利用しています。Double DQNではメモリの使用量が減ることにはなりません。学習済みネットワークを利用する実運用の際はonline neteworkを使用します。また、時系列データに適した構造となっているものではありません。
Dueling Network
DQNを改良したDueling Network手法について考えます。通常のDQNは状態を入力としてQ値を推論するニューラルネットワークです。ここで通常のDQNを改良したDueling Networkの手法では、DQN同様に状態sを入力としてQ値を出力しますが、以下のようにネットワーク内部でQ値(状態行動価値)を状態価値V(s)とアドバンテージA(s,a)に分解しています。
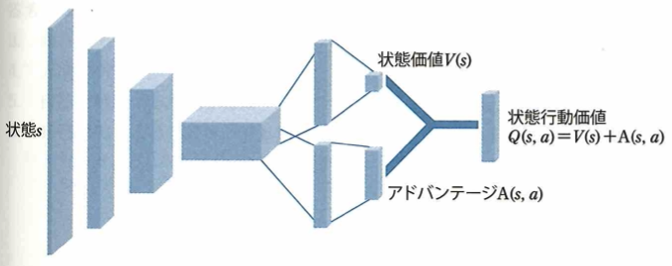
状態価値V(s)とはその状態にいることがどれだけ良いのかを測るもので、アドバンテージA(s,a)とはそれぞれの行動の重要性を相対的に測るものです。Duleing Network手法において、Q値を分解するアイデアの元となった洞察について、行動選択が報酬の獲得にほとんど影響を与えない状態が多く存在することです。
Dueling Networkのアイデアは、多くの状態では、行動選択の重要性が高くない洞察をもとにしています。Dueling Networkで、各行動の選択が重要になるのは、ゲームなどにおいて、障害物が接近した状況などです。Dueling Networkにおいて、分割した構造は、それぞれ状態価値とアドバンテージという異なるものを推論するものであり、推論結果を平均するものではありません。Dueling Networkは、元々直接Q値を推論していた構造を2つに分けたもので、パラメータ数を削減することを目的としたものではありません。
Noisy Network
DQNを改良したNoisy Network手法について考えます。通常のDQNでは方策として、ε-greedy法が用いられます。ε-greedy法では、εの確率でランダムな行動選択を行うことで、新たな行動を探索するものです。しかし、εの値の設定は、ハイパーパラメータとして手動で設定するものであり、モデルの性能を決める必要なパラメータであるとともに、適切な値の設定が難しいという問題があります。ここで通常のDQNを改良した手法にNoisy Networkと呼ばれる手法が存在します。この手法は、ネットワーク内部でランダムなノイズを発生させることで、ε-greedy法を用いなくてもランダムな行動を起こし、新たな行動を探索できるようになっています。Noisy Network法がネットワーク内部でノイズを発生する仕組みとして、平均と標準偏差を学習しつつ、ガウス分布による乱数をネットワークの重みとして用います。
このとき、ノードの出力にノイズを加算するものではありません。ランダムにノードの出力を0にするのはDropout法で、ネットワークの正規化に用いられます。入力データにノイズを加えるものでもありません。
AlphaGo
AlphaGoに用いられる各ニューラルネットワークの入力データと出力データと教師データを考えます。ここでは教師あり学習フェーズと強化学習フェーズの2段階で以後の強さを高めます。
教師あり学習フェーズでは、2つのネットワークを学習させます。 Supervised Learning Policy Network(SL Policy)が、人間の棋譜を教師データとして、ある盤面を見て次の盤面を予測します。これによって人間が考える有望な手のみを探索することができるので、悪い手まで探索する計算を省くことができます。よって入力データが「現在の盤面状態」で出力データが「次の盤面状態」で教師データは「人間の棋譜」です。Rollout Policyは、SL Policyと同様に現在の盤面から次の盤面を予測します。Rollout Policyの特徴は予測性能を下げる代わりに計算を高速にしたことです。そしてSL Policyで探索すると決めた手から終局までざっと計算して勝敗を決めます。これによってSL Policyの手がどれだけ良かったかを勝敗で評価できます。よってSL Policyと同じで、入力データが「現在の盤面状態」、出力データが「次の盤面状態」、教師データは「人間の棋譜」です。
強化学習フェーズでは、SL PolicyとRollout Policyの組み合わせで、人間を参考にした囲碁がざっくりとできるようになったので、強化学習フェーズに入ります。 まず、SL Policy同士で対戦を行わせます。そして勝った方が取った手を方策漸進法で強化していきます。すると、徐々にPolicyが強くなっていくので最強のPolicyをそれ以外のPolicyからランダムに選んで対戦を行います。この繰り返しでPolicyを強化学習していきます。Reinforcement Learning Policy Network (RL Policy)でPolicyの方策を強化学習させ、入力データが「現在の盤面状態」で、出力データが「次の盤面状態」で、教師データは「自己対戦によるエピソードと報酬」でとなります。つまり、RL Policyは勝敗を報酬として強化学習する方策ネットワークということです。 次に学習したRL PolicyとSL Policyを用いて自己対戦を行い、Value Networkという盤面と入力し勝率を予測するネットワークを学習させるためのデータセットを作成します。 自己対戦はランダムな手数ではSL Policyを使い、その後1手はランダムに手を打ち、以降はRL Policyを使って終局まで対戦を行います。このような対局を何度も行い、ランダムに手を打ったときの局面と勝敗を記録することでValue Network用のデータセットを作成します。よって、入力データが「現在の盤面状態」で、出力データが入力盤面の「勝率」で、教師データは「自己対戦による局面と勝敗」です。Value Networkの導入によって、最終的なAlphaGoでは打ち手を選択する際に、最終的な勝敗まで加味することができます。 最後に学習済みの各ネットワークを、モンテカルロ木探索のアルゴリズムの行動選択部分に組み込むことで、AlphaGoが完成します。 すべてのネットワークは、入力が19×19の盤面であるためCNNを用います。 ちなみに最終的なAlphaGoでは、SL PolicyとValue Networkで行動選択を行います。RL PolicyではなくSL Policyを用いる方が高い勝率を上げたそうで、元置きでの手の多様性をもたせたからではないかと考察しています。
AlphaGoの手法
スタートの状態から遷移できる状態をいくつかランダムに列挙します。列挙した状態から1つ選び、この状態を起点としてゲームの勝敗がつくまでランダムに状態遷移のシミュレーションをします。勝敗がつくシミュレーションの起点以前の状態に価値付けを行います。状態の価値付けができたのでスタートの状態から価値の高い状態へ遷移します。すでに列挙済みの状態の中の終端を新しいスタートの状態とします。以上を繰り返します。価値の高い状態を起点としたシミュレーションによって効率的に手の探索を行うアルゴリズムをモンテカルロ木探索(MCTS)と呼びます。囲碁などの状態数と行動数が多いゲームでは価値の全探索が難しいが、このアルゴリズムを用いることで、価値を探索する幅と深さを限定し効率的に状態の価値付けができます。しかし、探索の幅を限定する際、つまりある状態から次の盤面を列挙するときにランダムに選ぶのでは人間が選ばないような悪い手を選んでしまう点、シミュレーションはランダム状態遷移で行うため、同じ状態を起点としても勝ち負けが変わってしまい、価値付けがうまくできない問題がありました。AlphaGoでは、CNNを用いて4つのニューラルネットワークを学習させます。人間の棋譜の遷移関係を学習させることで1つ次の手を予測し勝ちに繋がりやすい状態を列挙するSL Policy、SL Policyの予測性能を落とす代わりに計算速度を上げたRollout Policy、SL Policyのネットワーク同士の対戦による学習で予測性能を向上させたRL Policy、またある盤面からRL PolicyとRollout Policyのネットワークを用いて勝敗がつくまでゲームを進めその勝敗をもとに盤面の勝利確率を学習させ、予測するValue Networkを学習させます。これらのニューラルネットワークによって改善したモンテカルロ木探索(MCTS)で作った囲碁AI同士を対戦させることで、新しい棋譜データを自動生成し、各ネットワークを学習させることで強い囲碁AIを作ります。
AlphaGo以前ではゲームAIの作成方法としてモンテカルロ木探索(MCTS)がありました。MCTSではゲームの手番の進行を木構造で表現します。ゲームの初期では、打ち手が勝敗に繋がるか評価することができません。しかし、すべての打ち手に関して勝敗がつくまで木構造を拡張する膨大な組み合わせという計算ができません。そこでMCTSでは、木構造に含める打ち手をいくつか全打ち手からランダムに選出することと、木構造を段階的に深くする方針を取ります。木構造を段階的に深くしながらランダムに選出した打ち手からさらに選んで勝敗がつくまでランダムに手番を行います(ロールアウト)。これで勝敗がつくので、スタート状態から勝敗がついた状態までの状態を評価することができます。これを繰り返して、価値の探索を行う箇所を限定しながら有望な打ち手の周辺のみを探索できます。しかし、木構造に含める打ち手をランダムに選ぶ時点で最有望手を含まなかったり、ロールアウトを行う際に同じ盤面からスタートしても、勝ち負けが変わってしまったりする問題がありました。これらの問題に対して、盤面から有望手を決めるSupervised Learning Policy Network(SL Policy)を人間の棋譜から学習させ、探索する木の幅を狭くしました。このとき同じく人間の棋譜から学習させ、SL Policyより精度が低い代わりに計算の速いRollout Policyも学習させておきます。ここまでが教師あり学習フェーズです。
ここからが強化学習フェーズです。 ここではSL Policyを初期値として、より強いRL Policy(Reinforcement Learning Policy Network)を作成します。RL Policyの学習は、味方モデルとなる最新のモデルと、相手モデルとなる学習中に保存してきたRL Policyからランダムにサンプリングしたモデルで自己対戦を行うことで、強いRL Policyを作成します。その後、局面から勝率を予測するValue Networkを学習させます。Value Networkは、学習済みのSL PolicyとSL Policyを組み合わせて自己対戦を行い、局面と勝敗データを自動的に記録したデータセットを利用して学習します。最後にSL PilicyとValue NetworkをMCTSの行動選択に組み込むことでこれまでのMCTSよりはるかに高い勝率を実現しました。
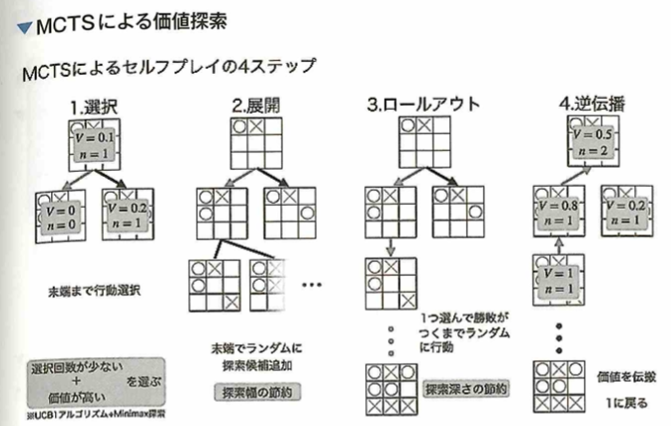
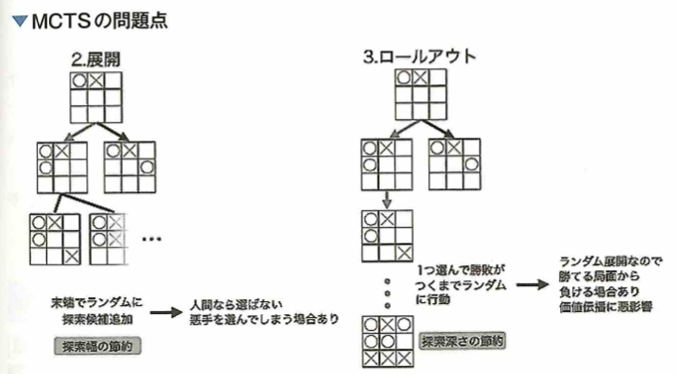
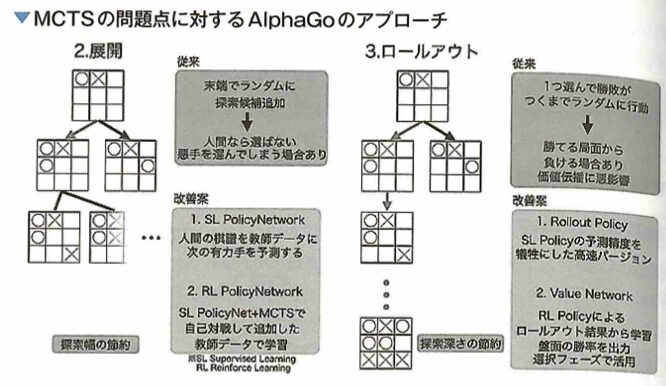

深層生成モデル
深層生成モデルのイメージ
深層生成モデルについて考えます。ディープラーニングは画像をクラス分類するようなタスクにおいて多くの研究が行われますが、これらのタスク以外にも新たなデータを生成するタスクにおいて活発な研究が行われています。このような分野においてディープラーニングを生成タスクに用いたモデルを深層生成モデルと言います。すべて深層生成モデルとして用いられるモデルまたはアーキテクチャはVAE、GAN、WaveNetです。
最近の深層生成モデルの動向として、テキスト情報を加味した未知の画像生成が提案されています。中でもOpenAIのDALL-E、DALL-E2やGoogle社のImagenという手法がインパクトのある提案として登場しました。これらの手法はどちらも自然言語のモデルを用いてテキスト情報を潜在空間に埋め込み、それを加味して画像生成を行います。 たとえば、「犬の散歩しているチュチュを履いた大根」や「アボカドの形をした椅子」といった不思議な文章でさえ画像化します。 特にDALL-Eで使われるアーキテクチャはCLIPと呼ばれ、テキストと画像の関係性を強く学習するため、zero-shot learning(そのクラスの画像を見なくても分類可能とするタスク)においても高精度を出しました。
VAE(Variational Autoencoder:変分オートエンコーダ)はオートエンコーダに工夫を加え、新たなデータを生成できるようにしたモデルです。GAN(Generative Adversarial Network:敵対的生成ネットワーク)は偽データを生成するモデルとデータの真贋を判別するモデルを交互に学習させていくことで、偽データを生成するモデルが本物に近いデータを生成できるようにするアーキテクチャです。WaveNetは音声生成の分野に大きな影響を与えたモデルです。最初の入力から次の出力を次々に予測していくアプローチをベースにCNNで構成されています。
VAE
深層生成モデルの1つであるVAE(Variational Autoengcoder:変分オートエンコーダ)はオートエンコーダに改良を加えたモデルで、新しいデータを生成することができるモデルです。新しいデータを生成するためにVAEのエンコーダ部分は入力データを生成する何かしらの分布の平均と分散に変換する学習を行います。また入力データを生成する何かしらの分布の平均と分散から乱数を使ってデコーダの入力となる値を生成することで変化が加わった新たなデータを生成します。
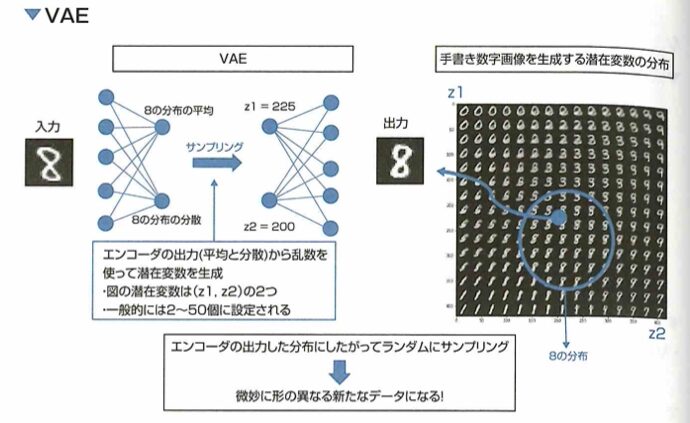
画像データを例にすると、通常のオートエンコーダは入力画像を圧縮し、特徴を捉えたより低次元のベクトルで表現するものでした。上図のようなVAEでは画像を生成する潜在変数(入力データの特徴を圧縮したベクトル)の分布を学習し、入力画像を平均と分散に変換します。変換後に、デコーダの入力となる潜在変数をサンプリングすることで新たなデータを生成できます。このようにVAEでは、入力データとは異なる新たなデータを生成できます。
GAN
深層生成モデルのアーキテクチャの1つであるGANについて考えます。GAN(Generattive Adversarial Network:敵対的生成ネットワーク)と呼ばれるアーキテクチャでは、主に次の2つの構造を持っています。ジェネレータとは、元となるデータやランダムなノイズといった入力を受け取り、偽物のデータを出力します。ディスクリミネータとは学習用のデータセットに含まれている本物のデータもしくはジェネレータが生成した偽物のデータを受け取り、これらデータが本物であるか偽物であるかを出力します。ここでもしジェネレータが、十分精度の高いディスクリミネータを騙せる画像を生成できるように学習できれば、ジェネレータを用いて本物に近い画像を生成することができると考えられます。このような学習をうまく進めるために、GANではジェネレータとディスクリミネータの学習を少しずつ交互に進めるように学習を行います。
GANのアーキテクチャを応用したモデルに、ジェネレータとディスクリミネータにCNNを利用したDCGAN(Deep Convolutional GAN)があります。GANにはこのような派生したモデルが多く考案されており、近年の画像生成分野において人気を博しているアーキテクチャとなっています。
CycleGAN
深層生成モデルのアーキテクチャの1つであるCycleGANについて考えます。画像から別の画像を生成するアーキテクチャで、シマウマと馬、写真と絵画などドメインを変換できるように生成器が学習していきます。
Pix2Pixとは画像から別の画像を生成するアーキテクチャで、実際の画像からベースとなる画像を作成し、ベース画像から生成した偽画像が本物の画像と判断されるように生成器が学習していきます。実画像Yからベースとなる画像Xを生成し、Xからノイズzを用いて偽画像GXを作成します。このX、YとX、GXが本物のペアかどうかをDiscriminatorが学習していきます。それによりGeneratorはより本物に近い画像を生成できるようになります。
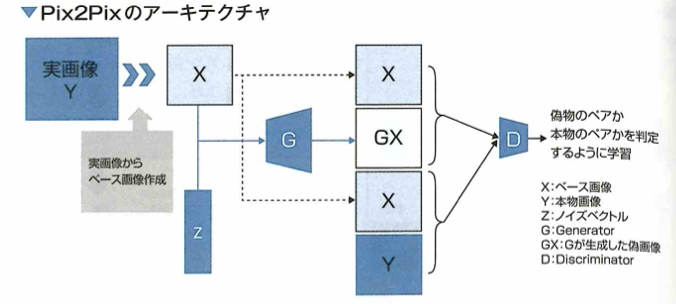
CycleGANは驚くべきことにこのアーキテクチャは、ドメイン間の画像のペアがなくても学習します。
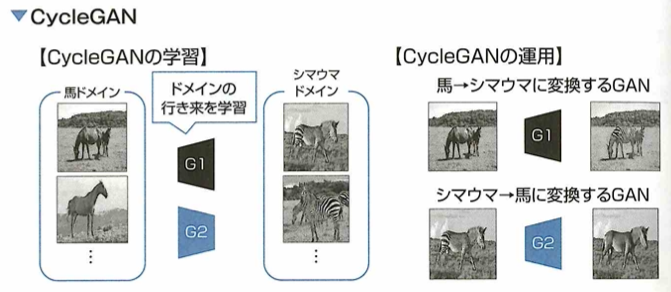
stackGANはテキストを入力として、そのテキストの内容の画像を生成します。styleGANは固定特徴マップを段々と拡大していくことで、高解像度の画像を生成します。拡大後に潜在空間から得られたノイズに非線形変換を行って取得したstyle情報を毎回付与することで、画像の細かいところまで調整された高精細な画像を取得できます。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
CNNは画像データなどを扱うニューラルネットワークです。通常のニューラルネットワークは多層パーセプトロンで、全てのユニット同士を各層で連結させる全結合層のみで構成されます。これでは画像の位置情報が失われるので、CNNでは畳み込み層やプーリング層を導入しそれを防ぎます。これらによって抽出される数値表現を特徴マップと言います。これは多次元です。畳み込み層では、フィルター(カーネル)を適用し畳み込み操作を行います。内積などの処理をします。一定間隔でフィルターをスライドさせながら計算を行います。このフィルタ移動の間隔をストライドと言います。プーリング層では小領域(窓)を設定し最大値プーリングや平均値プーリングなどを行います。つまりサイズを小さくする処理です。これは次元削減の一種です。畳み込み層は学習可能なパラメータで構成されます。プーリング層は学習可能なパラメータを持ちません。同じノード数間の全結合層と比較して、各ニューロン同士の結合が疎であり効率的に学習ができます。プーリング層により入力データに関して位置不変性(移動不変性とも言います)を獲得できます。これも次元削減の一種です。CNNでは出力層付近に全結合層を設置しますが、層への入力データの次元を揃える必要があります。プーリングでは窓の大きさを変えることで出力の大きさを一定に保てるので特徴マップを適切に全結合層に接続できます。また畳み込み層やプーリング層は画像以外にも時系列データなどにも適用できます。
GAP(grobal average pooling)は各チャンネルについて全体の平均を1つのニューロン値とする手法です。パラメータ数を削減でき過学習を抑制できます。チャンネルとは、画像方向の軸を表す概念です。
バッチ正規化とはニューラルネットワークのある層への入力を正規化する手法です。層への入力自体を正規化するということです。ミニバッチ(訓練データからサンプリングされた少数データ)内のすべてのデータを使用して前層の出力をチャンネルごとに正規化する手法です。しかしバッチサイズに影響されます。この対策としてレイヤー正規化があります。前層の出力に対して、ミニバッチ内のデータごとに正規化を行う手法です。インスタンス正規化はチャンネルごと、データごとに正規化を行う手法です。グループ正規化はチャンネルをいくつかのグループに分割し、グループ内でのチャンネルを使用してデータごとに正規化を行う手法です。つまりグループ正規化はレイヤー正規化とインスタンス正規化の利点を活用したものです。
勾配消失問題を防ぐためにスキップ結合があります。ResNetはスキップ結合を用いたネットワークです。スキップ結合に加えてボトルネック構造を用いています。チャンネル数の削減により計算効率化が上がります。
RNN(リカレントネットワーク)は回帰結合層を持つネットワークです。言語データや時系列データで使用します。時間軸に沿って過去に遡りながら誤差を伝播する学習をBackPropagation Through Time(BPTT)と言います。RNNの構造を持つ例として、エルマンネットワークは隠れ層の出力をコンテキスト層で対応させ隠れ層に再起的に接続します。ジョルダンネットワークは隠れ層の出力の代わりに出力層の値を隠れ層に接続する構造を持ちます。LSTMはLSTMブロックを導入したRNNで現在も広く使われているネットワークです。これはボトルネック型の構造を持ちません。LSTMブロックは、CECとゲート構造を有します。CEC(Constant Error Carousel)とは長期的な情報を蓄えます。LSTMは計算量が多く学習に時間を要します。そこでこれを簡略化したGRUが考案されています。
Transformerは時系列データを扱えますがRNNの構造を持ちません。TransforerではAttentionが大事です。これはRNNが入力データを逐次的に扱うので処理速度が遅く、離れた単語間の関係を捉えにくい問題を解決するものです。各時刻の状態に重みづけを行い、その総和を求めることで広範囲の情報を高速に扱います。Self-Attention、Multi-Attention、Source-Target-Attentionなどがあります。Transformerで使用されるAttentionはqueryやkeyやvalueがあります。Self-Attentionではqueryやkeyやvalueを入力文から計算し文中の単語間の関係を捉えます。入力文内のすべての単語間の関係を並列に計算できます。一方で、そのまま計算すると単語の順番に関する情報を保持できません。そこで単語の位置に固有の情報を入れることで回避できます。これを位置エンコーディングと言います。ただし位置エンコーディングにはqueryやkeyやvalueを使用しません。TransformerのエンコーダはAttentionを採用することで並列計算を行え、GPUを用いてより高速に学習ができます。デコーダ出力の際は、Transformerであっても並列計算できません。Seq2Seqと同じように可変長の出力も扱えます。
一般的なRNNは固定長の系列を出力できますが、入力と出力の長さが違うと扱いづらいです。Seq2Seqはこの問題を解決します。エンコーダとデコーダを用いてタスクを扱います。教師強制はRNN学習時に一時刻前の出力に対応する教師データを現時刻の入力として使用する手法です。
オートエンコーダはエンコーダとデコーダで構成されるニューラルネットワークのアーキテクチャです。教師データとして入力データと同じデータを使用します。元のデータができるだけ復元可能な形で圧縮されます。オートエンコーダは特徴抽出や次元削減に利用されます。簡単なタスクを利用して事前学習を行うことでより複雑なタスクを学習しやすくなります。積層オートエンコーダが一例です。入力層から逐次的に層を重ね、それぞれの層を順番にオートエンコーダの仕組みによって学習する手法です。変分オートエンコーダ(VAE)は生成ネットワークの一種で、画像生成のタスクに使われます。学習済みのデコーダに新たに確率分布からサンプリングした値を入力して、データを生成できます。さまざまな派生があります。β-VAEはVAEの学習に潜在変数の分布を調整するハイパーパラメータβを導入し生成画像の質を高めたネットワークです。infoVAEはさらにそれを拡張したネットワークです。VQ-VAEは潜在変数が離散的になるように拡張したネットワークです。VAEが学習時に潜在変数を無視してしまう現象を解消しています。
データ拡張は訓練データを加工することでデータ量を増やす手法です。Paraphrasing、Nothing、Samplingがあります。順に、置き換え、削除・挿入・置換などをランダムに行いデータを増やす、テキストデータの分布を推定し新た強いデータのサンプリングを行う、です。Rotationは画像の回転によりデータを増やす手法です。RandAugmentは画像データに対してさまざまなデータ拡張操作の中からランダムに操作を選び出し、画像データに適用します。データ拡張を用いて1つのデータから条件の異なる多様なデータを生成できます。Random Flipは画像を反転させデータを増やします。Random ErasingやCutoutは画像の一部の画素数を0またはランダムな値にしてデータを増やします。Random Cropは画像の一部を切り取り、サイズの異なるデータを生成します。他にもMixupは2枚の画像を生成、CutMixはCutOutしてマスクした領域に別画像を組み合わせて生成を行う、Random Rotationは画像をランダムに回転などがあり、他にも明るさ調整、コントラスト調整などもあります。RandAugmentは学習時に適用するデータ拡張手法を決定する戦略の一つです。あらかじめデータ拡張手法を決めておき、ミニバッチごとに一定数の手法を無作為に選び、一定の強さで適用します。強さとは、Rotationであれば角度の大きさを表します。RandAugmentではハイパーパラメータはミニバッチごとに選ぶ手法の数と適用する強さの2つであり、探索空間が非常に小さくなることで最適な戦略を見つけやすくなります。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
多層パーセプトロンは、単純パーセプトロン(入力層+出力層のみ)に隠れ層を加えたニューラルネットワークです。隠れ層があるので非線形の分類問題にも対応可能です。勾配消失問題とは、ニューラルネットワークの重みの更新に必要な情報が、出力側から入力側に向かってどんどん小さくなり、うまく伝播できなくなる問題です。隠れ層が多いと深刻になります。誤差逆伝播法は出力側から入力側へ向かって逆方向に誤差情報を伝播し、隠れ層の重みを更新するニューラルネットワークの学習法です。活性化関数とはニューラルネットワークの隠れ層の間で伝播する信号の値を調整する関数で、後段の層で特徴量を抽出しやすくなる役割を果たします。
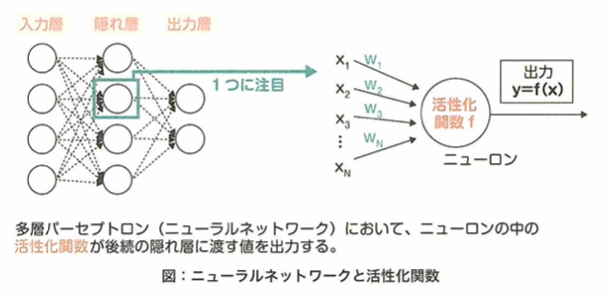
損失関数(誤差関数)はモデルの出力と正解の間の誤差を定量化する関数です。その値を最小化するようにモデルを学習します。つまりパラメータを最適な値まで更新します。勾配降下法はニューラルネットワークのパラメータ(重み)の最適化に使うアルゴリズムです。大域最適化に辿り着けない問題を、局所最適解問題と言います。プラトーとは勾配がゼロに近い平坦領域で学習が停滞しやすくなる場所です。学習率とは、学習の進行を調整するパラメータで、一度に重みを更新する歩幅を制御します。インテレーションとは同じパラメータを更新する回数を表す量です。エポックは同じ訓練データを繰り返しモデルの学習に使う回数を表す量です。SDG(確率的勾配降下法)は一気に全てのデータを学習に用いず、データをミニバッチに分けて、ミニバッチごとにモデルに入力して損失関数を計算し、少しずつパラメータを更新する方法です。局所最適解に陥ることや異常値の影響を抑えることができます。ミニバッチ学習は毎回一部のサンプルからなるミニバッチを取り出して、それを使ってパラメータを更新する方法です。バッチサイズは1つのミニバッチの中でのデータの数で一気にモデルに入力し学習に使うデータの数で、ハイパーパラメータの1つです。オンライン学習は毎回サンプルを一度つ取り出してパラメータを更新する方法です。局所解に陥らないようにできます。欠点は、単一のデータに対してパラメータの更新を行うので、外れ値に敏感に反応し、結果が不安定になりやすいことです。バッチ学習(最急降下法)はパラメータの更新に全ての学習データを一度に用いる手法です。一気に損失関数の変化を評価するため学習結果が安定しやすいですが、全データで計算するため計算コストが高くなります。データの総数が少ない時に使いやすいです。
勾配降下法のアルゴリズムについて、AdaGradは学習が進行するに従い、パラメータごとに自動的に学習率を調整します。RMSpropはAdaGradの改良版です。「最近」のパラメータの更新の影響を大きくし、学習率を急激に下げないように勾配の2乗の指数移動平均を計算に用います。AdamはRMSpropとAdaGradの良いところを組み合わせた改良版です。過去の勾配の二乗の指数移動平均を用いて、勾配の平均と分散を推定します。学習の収束が早く、性能の良さからよく利用されます。
転移学習は、膨大なデータで訓練した学習済みモデルの汎用的なパラメータ値を別のタスクに応用する手法です。ファインチューニングは転移学習に用いる学習済みモデルに、新しいタスクに特化した層を追加し、出力層に近い位置のパラメータ(重み)を調整することです。バッチ正規化は層ごとに標準化を行うことで、データの分布の偏り(内部共変量シフト)を補正することです。内部共変量シフトとは、データがネットワークの中で下流に向かって何層も進むにつれて、隠れ層から出力されるデータに偏りが出てくる傾向です。ドロップアウトとは、学習時に一部のニューロンをランダムに無効化し、過学習を軽減し汎化性能を上げる工夫です。
モデルを軽量化する手段について、プルーニング(枝刈り)は汎化性能への寄与度が比較的低いノード間の接続を切ることで、蒸留とは大規模モデル(教師モデル)への入力データとその出力を用いて、小さいモデル(生徒モデル)を学習することで、量子化はパラメータの値をよりビット数の少ない数値で表現することです。
RNN(リカレントニューラルネットワーク:再帰型ニューラルネットワーク)とは時系列データを扱うニューラルネットワークで、隠れ層でフィードバック機構の働きにより一度処理した情報を再び同じ層に入力し、保持できるため、過去の入力を考慮した予測が可能です。BPTTとはRNNにおける誤差逆伝播の仕組みであり、勾配消失問題の原因になり得ます。重み衝突問題とは、RNNで時系列を扱う際の問題です。「今の時刻では関係性は低いが、将来の時刻では関係性が高い」という入力を与えた場合、重みを適切な値に設定しづらいという問題です。LSTMはRNNの改良版で、長い系列の学習が困難(BPTTなどの問題)を軽減しました。長期的に保存したい情報をメモリに書き留め、不要な情報は忘却します。CECとはLSTMで長期的に情報を保存するセルです。LSTMにおいて活性化関数を用いて情報の取捨選択を行うゲートは、入力ゲート(入力重み衝突問題を防止するためのゲート)、出力ゲート(出力重み衝突問題を防止するゲート)、忘却ゲート(誤差が過剰にセルに停留することを防止し、リセット行う)です。GRUはLSTMを簡略化したモデルで、3種類のゲートの代わりにリセットゲートと更新ゲートの2種類を用います。
CNNは画像認識に用いられるニューラルネットワークで、畳み込み層、プーリング層、全結合層の3種類のレイヤーから構成されます。畳み込み層は入力画像から特徴を抽出します。プーリング層は特徴マップにおける重要な特徴を残しつつ画像の情報量を圧縮することで、対象物の位置にわずかな移動(違い)があるデータに対しても認識結果が変わらないようにします。
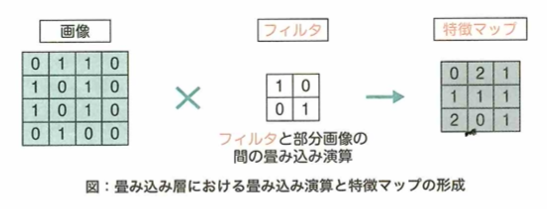
パディングの目的はCNNの各層から出力される画像のサイズを調整することです。ILSVRCは2010〜2017年まで毎年開催された画像認識の競技会で、CNNモデルが優勝したことがディープラーニングの普及につながりました。競技会では誤差率の低さを競います。ImageNetは巨大な画像データセットで、クラス名に関して、WordNetという概念辞書を参照することで、上位語と下位語の概念を使用します。ResNetは2015年にILSVRCで優勝し、初めて人間の認識精度を超えたCNNです。スキップ結合構造により層を飛び越えた層ごとの結合を行い勾配消失を防止し、結果として非常に多層のネットワークを実現できます。
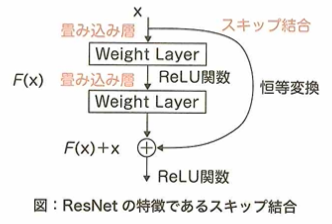
EfficientNetはCompound Coefficientというスケーリングの法則に従い、ネットワークの広さ、深さ、解像度を最適化し、パラメータ数が少ないモデルで効率よく高い精度を達成したCNNモデルです。
強化学習は、特定の状況下で最大限の報酬を得るために行動を学習する機械学習の分野です。Q値(状態行動価値)とは各状態に対する行動により得られる報酬の期待値です。DQN(Deep Q-Network)はDeepMind社に開発された深層強化学習の代表的な手法です。設計の基本思想はQ学習に基づいており、状態行動価値関数の表現にディープラーニングをもちいることで膨大な数の状態を可能にします。AlphaGoはDeepMind社により開発され、CNNを使用して打つべき手の探索にモンテカルロ木探索法を使用しています。強化版のAlphaGo Zeroも開発され、完全自己対局での学習が可能になりました。greedy法は常にその時の状態における価値関数が最大になるように行動を採用し方策を決定するアプローチです。ε-greedy法は探索可能な行動範囲を広げるために、一定の確率εでランダムな行動をとらせるアプローチです。SARSAは強化学習のアルゴリズムで、実際にエージェントを行動させることで得られた次の状態における評価を参考に、少しずつQ値を更新し、行動を最適化します。モンテカルロ法は行動するたびにQ値を更新するかわりに、報酬を得られた時点それまでに行った行動のQ値を一気に更新する方法です。ノイジーネットワークはネットワークに外乱(ランダムな要素)を与えて学習させることでより広範囲に探索ができる手法です。Experience Replay(経験再生)はDQNにおいて一度に複数のサンプルを取り出してミニバッチ学習を行う仕組みにより、サンプル間の相関による影響を軽減させる方法です。
オートエンコーダはエンコーダとデコーダから構成されるニューラルネットワークです。入力層と出力層の間に位置する隠れ層では、入力されたデータを一度圧縮し、重要な情報のみ抽出します。出力層において、入力層と同じデータになるように復元を行います。隠れ層のノードの数を入力層と出力層よりも少なくします。エンコードはオートエンコーダにおいて入力層に入力されたデータを隠れ層に圧縮する処理のことで、デコードはオートエンコーダにおいて、隠れ層に圧縮されたデータを出力層に復元する処理です。事前学習は、ニューラルネットワークのパラメータの初期値を適切な値に設定する方法です。初期値をランダムに設定した場合に比べ、勾配消失問題が抑えられます。積層オートエンコーダは複数のオートエンコーダを積み重ね、順番に学習させていくモデルです。
GPGPUはGPUを拡張した演算装置で、ニューラルネットワークの学習に使えるように、画像処理に特化したGPUを拡張したものです。バーニーおじさんのルールは必要な学習データ量に関する経験則であり、モデルのパラメータ数の10倍のデータ量が必要と主張されています。オーバーサンプリングは学習データを準備する際に、データ数が少ないクラスからサンプリングする件数を相対的に増やすことでデータの偏りを減らすことです。ダウンサンプリングは学習データを準備する際に、データ数が多いクラスからサンプリングする件数を相対的に減らすことでデータの偏りを減らすことです。arXivは数理統計学、自然科学、電子工学、システム科学、経済学などの分野において、プレプリント(査読前論文)を含む様々な論文が保存・公開されているウェブサイトです。
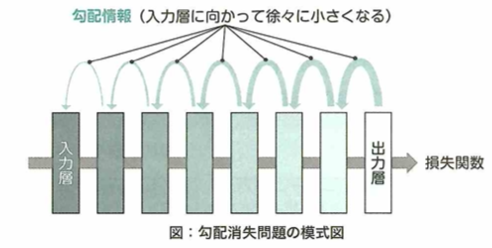
データ拡張は回転や平行移動などで人工的に訓練画像のバリエーションを増やす方法です。転移学習を用いることで、勾配消失問題の回避につながることとして、ネットワークの大部分の(特に入力層に近い)重みがすでに適切な値に設定されているからです。
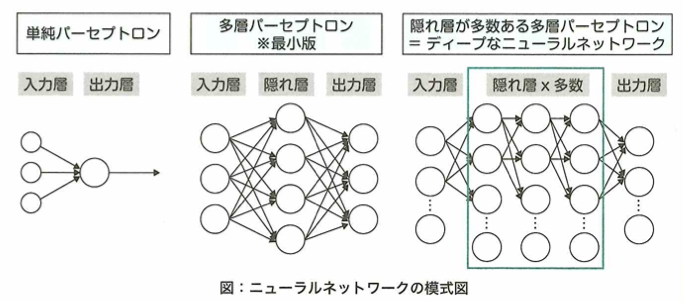
ニューラルネットワークの訓練(最適化)は損失関数を最小化するパラメータの値を見つける過程と捉えることができます。最適なパラメータの設定にたどり着くまでにパラメータを繰り返し更新する必要があります。ニューラルネットワークにおいて隠れ層の各ニューロンに入力された値は、活性化関数(ニューラルネットワークの各ノードの中にある非線形関数)により値が変換されて、次の層へ伝播されます。これにより後続の隠れ層で特徴量を抽出しやすくなり、ネットワークの学習に有利です。活性化関数には非線形関数が用いられます。
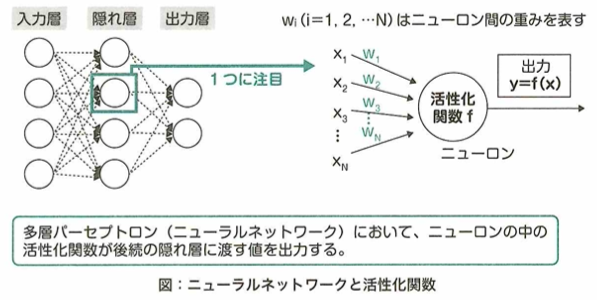
シグモイド関数やtanh関数では入力値が極端に大きい、極端に小さい値になったときに、関数の微分値が0に近づくので、勾配情報が限りなく0に近づき学習が停滞してしまいます。予測値を使って計算される損失関数の値を最小化する方向に、ネットワークのパラメータ(重みやバイアス)を学習し、最終的に最適な値に収束することを目指します。学習率は一度にどの程度重みを更新するかを指定するための学習の進行を制御するハイパーパラメータです。
学習率はハイパーパラメータです。中間層のバイアスと重みは、学習プロセスの中で自動的に値が最適化されるパラメータです。出力ノードの数は分類問題のクラスの数で決まります。
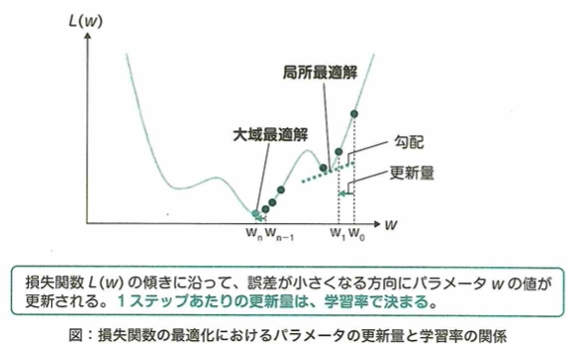
情報利得は決定木におけるデータ分割の基準です。
シグモイド関数の全領域にわたっての微分値は最大でも0.25しかありません。tanh関数は微分値が最大で1より、シグモイド関数より勾配消失問題が軽減する関数です。しかしReLU関数に比べてどちらの関数も横軸の値が大きいときや小さいときに関数が平坦になり微分値が小さい値になりやすく勾配が消失しやすい傾向です。活性化関数は入力されたデータを学習しやすいように整えて、次の層に渡す出力を決定します。出力値と正解の間のずれから計算される損失関数の勾配情報に基づいて誤差を逆伝播するため、活性化関数の微分値をいくつも掛け合わせた値を用います。微分値を決める活性化関数の形状が学習に大きく影響します。Leaky ReLUは入力値が負の時に完全に0でなく少し傾きを持たせています。現実にはReLU関数の方が高い精度を出しますが理由は未解決です。
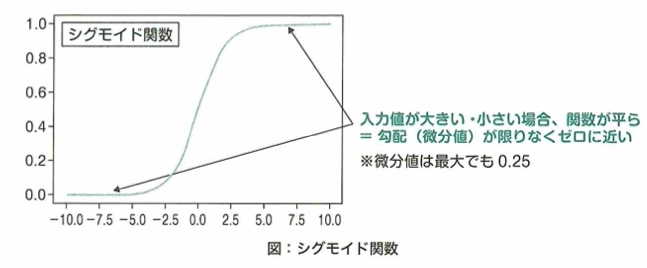
誤差逆伝播法の重みの更新では勾配消失問題が起きやすくなります。ネットワークが深くなるにつれ、重みの更新に必要な勾配の情報が入力層に近い層までただしく伝播されなくなり、学習が停滞してしまう現象です。重み衝突問題はRNNで起こりやすい問題です。一般的なニューラルネットワークの非常に長い版となります。RNNの場合はとくに勾配消失問題が起きやすいです。

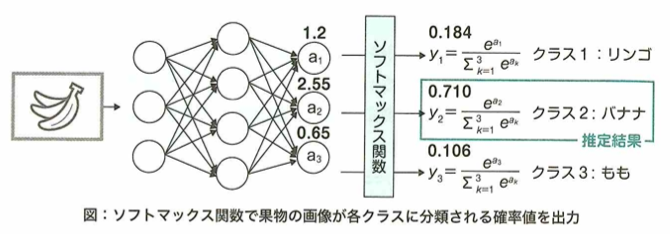
シグモイド関数とtanh関数はニューラルネットワークの隠れ層で用いられます。
Random Cropはニューラルネットワークの最適化手法でなく、データ拡張の手法です。1枚の画像からランダムに切り抜くことで、疑似的にデータの水増しをします。AdaGradは学習が進行するに従い、パラメータごとに自動的に学習率を調整します。RMSpropはAdaGradの改訂版で、最近のパラメータの更新の影響を大きくし、学習率を急激に下げないように調整します。Adamは2つのいいとこどりです。学習の収束が早く、性能の良さからよく利用されます。SDG(Stochastic Gradient Descent)は確率的勾配降下法で、ニューラルネットワークでパラメータの更新を行うのに使用する勾配降下法の一種です。局所最適解や異常値の影響を抑えるため、一気にすべてのデータを学習に使わず、データをミニバッチに分けてミニバッチごとに損失関数を計算し、少しずつパラメータの更新をします。DQNとA3Cは強化学習のアルゴリズムです。
転移学習の例は、ImageNetで訓練したResNetなどの巨大なCNNモデルを一般公開することで、ユーザはそれを手元の小規模な画像認識タスクに用いることができます。学習済みモデルの隠れ層は、すでに優秀な特徴抽出器となっており、それを少し違う別のデータに適用しても、それなりに汎化的なパラメータを提供できます。学習済みモデルを別のタスクに使いまわすときに、新しいタスクに特化した専用な層をネットワークの出力層に近い部分に追加します。転移学習において微調整や再訓練をするのは、ネットワークの下流にある層のパラメータです。
画像分類の精度を上げるため、人工的に学習用画像データのバリエーションを増やすデータ拡張を行います。特徴量選択は、機械学習においてデータのどの部分を予測の特徴量とするかを選ぶプロセスです。
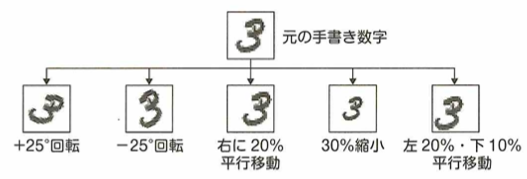
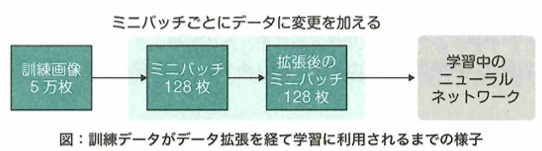
蒸留は大規模なモデルを教師モデルとしてその大きいモデルに入力したデータとそれに対する出力を新しいモデル(生徒モデル)の学習に利用することです。転移学習においてタスクに特化した専用の層を出力層に近い部分に追加し、出力層に近い位置のパラメータ(重み)を調整します。
損失関数L(W)を小さくすることについて、解析的解法(数式変形)、数値的解法(数値演算)、その他(図形解法)があります。勾配降下法は数値的解法になります。
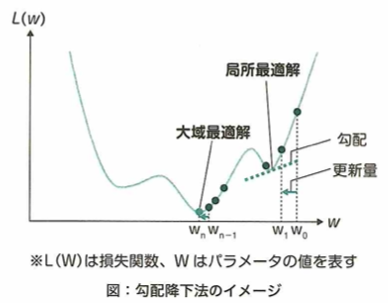
1回のインテレーションは、パラメータを1度更新することです。エポックは同じ訓練データが何回繰り返して学習に使われたかを示す量です。何エポックまで学習させるかはハイパーパラメータです。予測精度が下がってきた時に学習を打ち切ることを早期終了と言います。
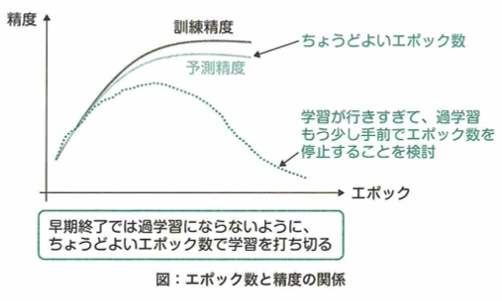
入力されたデータは深いネットワークの中で何層も通過するうちにデータの分布に偏りが出て、過学習が発生し学習精度が落ちます。これを防止するためバッチ正規化があります。層ごとに標準化を行うことで偏りを補正します。データが正規分布に近づくように整えます。これは学習を早くするとともに過学習を防止する効果があります。局所最適化問題はバッチ正規化とは無関係です。SGDは確率的勾配降下法で、局所最適解に用いる確率や異常値の影響を抑えるため、一気に全てのデータを学習に使わず、データをミニバッチに分けて、ミニバッチごとに損失関数を計算し、少しずつパラメータを更新します。ミニバッチ学習は一度に使うデータの数(バッチサイズ)が少ないので、損失関数がパラメータのわずかな変化にも敏感に反応します。局所最適解付近で停滞しにくくなり、大域最適解に向かって学習が進みます。オフライン学習は、あらかじめ実世界から集めた過去のデータのみを使って強化学習を行う手法です。最急降下法はパラメータの更新に全ての学習データを一度に用いる手法です。内部共変量シフトとはニューラルネットワークの中でデータが下流に向かって進むにつれ、出力結果に偏りが出てくることです。オーバーサンプリング(アップサンプリング)は学習データを準備する際に、データ数が少ないクラスからサンプリングする件数を相対的に増やすことでデータの偏りを減らすことです。アンダーサンプリング(ダウンサンプリング)は学習データを準備する際に、データ数が多いクラスからサンプリングする件数を相対的に減らすことでデータの偏りを減らします。
ドロップアウトは一部のニューロンをランダムに無効化し、過学習を軽減し汎化性能を上げる手法です。ランダムフォレストのアンサンブル学習器と概念が似ています。
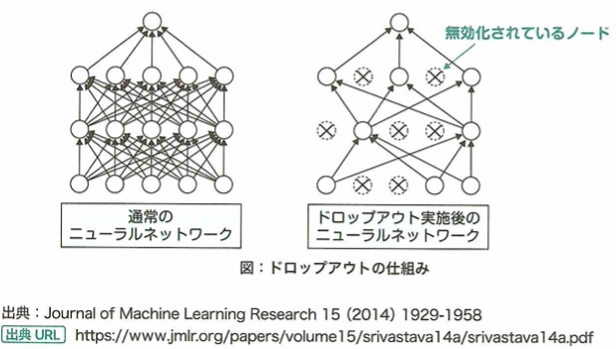
転移学習は膨大なデータで訓練した学習済みモデルを別のタスクに応用するニューラルネットワークの訓練における工夫です。事前学習はオートエンコーダを順番に学習させていくことにより、ニューラルネットワークのパラメータの初期値を適切な値に設定する方法です。オートエンコーダはエンコーダとデコーダで構成される次元削減や特徴量抽出を得意とするシンプルなニューラルネットワークです。学習済みモデルを転移学習に活用する際に、元の出力層を手元のタスクに適した出力層に置き換え、出力層に近いパラメータのみ再訓練することをファインチューニングと言います。さらに高精度を狙うときはネットワーク全体のパラメータを再訓練することもあります。畳み込み演算はCNNにおいて画像から特徴を抽出するためのフィルタと画像の間で行われるピクセル値の演算です。グリッドサーチは機械学習においてハイパーパラメータの最適な組み合わせを格子状に探索する手法です。アンサンブル学習は複数の弱学習器を組み合わせて汎化性能を高めるための機械学習の手法です。
Adamは学習率の調整を効率的に行うことで学習の進行を改善しています。XavierとHeはニューラルネットワークの初期値を決めるアルゴリズムです。HMMは隠れマルコフモデルで、音響モデルの一種です。VAEはオートエンコーダを活用した深層生成モデルです。LSTMはRNNの改良版モデルで比較的長い系列データを扱えます。
正則化は過学習を軽減するために損失関数にペナルティ項(正則項、懲罰項)を追加した上でモデルのパラメータの最適化を行う手法です。白色化はデータ間の相関をなくし、分散の正規化を行うことで学習を効率化することを目標とした前処理です。
エポック数が大きすぎると過学習が起きます。そのために早期終了を考えます。プルーニングはモデルの一部の比較的重要でないノードを断ち切ることで、モデルの軽量化を図る手法です。インフラや学習データの節約の効果もあります。
ドロップアウトはニューラルネットワークの一部のニューロンをランダムに無効にしながら学習を進めて過学習を軽減します。Random Erasingはデータ拡張の一種です。ランダムな値で画像の上の矩形領域を埋めることで、その都度、擬似的に異なる画像データを作り出します。

プルーニングだけでは精度が落ちるので、プルーニング後に再学習を行う必要があります。大きくて複雑なモデルほど訓練データに対するパラメータが多いので過学習しやすいです。対策は訓練データを大量に用意することです。軽量化でパラメータ数を減らしてモデルを簡略化すると、過学習をおさるために必要な訓練データ量が少なくて済みます。蒸留では軽量でありながら、教師モデルと同程度の精度を持つ軽いモデルを作成できます。量子化はパラメータの値をよりビット数の少ない数値で置き換えます。ネットワークの構造を変えずにモデルの軽量化を実現できます。ただしパラメータを表す数値の精度が下がるので、モデルの精度も低下する可能性があります。軽量化と精度のバランスが大事です。
蒸留においての手順は、大規模なデータセットを用いて教師モデルを訓練し、学習済みの教師モデルを用いて、新たなデータセットに対して予測を行い、教師モデルの予測出力を用いて、生徒モデルを教師モデルに近づくように訓練します。教師モデルが最も確率が高いと判断したクラスのみを用いた正解ラベルをハードラベルと言い、全てのクラスに対する確率の出力値を用いた正解ラベルをソフトラベルと言います。蒸留ではソフトラベルを用いて生徒モデルを訓練します。これは情報量を増やすためです。
データ拡張とは、ミニバッチ毎に学習用の画像データに対して回転、平行移動、反転などの変換を施し、その都度、疑似的に異なる画像データを作り出すことです。Cutoutは画像中のランダムな位置を矩形領域(固定値0)で隠します。Mixupは2枚の画像を融合させます。Random Cropは元画像の一部をランダムに切り抜きます。Random Erasingとはランダムな値で画像の上の矩形領域を埋めます。
機械学習のモデルの規模を小さくすることにより、学習しなければならないパラメータの数を減らせます。モデルの規模を小さくしても計算リソースが必要であることが多いです。ニューラルネットワークの訓練には一般にGPUが使用されます。モデルの規模縮小と汎化性能を高めることは関係ありません。GPGPUはGPUを拡張子、ディープなニューラルネットワークの学習に利用できるようになりました。CPUはコンピュータ全般の処理を順番に1つずつ実行するために数個の高性能なコアが使われます。Hadoopは分散技術を用いたアプリケーションです。
モデルのパラメータ数が決まっても必要なデータ量は必ずしも決まるとは限りません。経験則として、バーニーおじさんのルールがあり、モデルのパラメータ数の10倍のデータ量が必要とされていますが、非現実的な計算量になることが多く、実際はモデルのパラメータ数を減らす工夫が行われます。例えば EfficientNetはパラメータを減らしつつ、高い予測精度を実現している優れたCNNモデルです。
CNNはフィードフォワード型(順伝播型)のネットワークのため、時系列データ(音声や文章など)の処理に向きません。処理は全ての時刻に対して独立に行われるので、以前入力された情報は記憶されません。RNNはフィードバック機構の仕組みにより、一度処理した情報が再び同じ層に入力されます。過去の隠れ層の間に繋がり(情報の伝播)があるので、過去の入力を考慮した予測が可能です。RNNでは時間順序の情報が削れないので時系列データを扱うことに適しています。
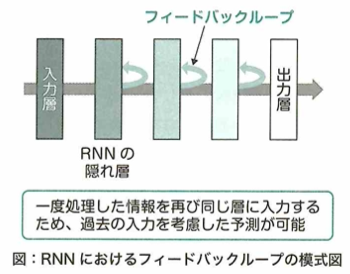
プーリング層はCNNの中で畳み込み層の後ろに配置されることが多く、情報の圧縮に使用されます。エンコーダ・デコーダモデルはその構成要素がRNNで構成され、自然言語処理モデルに使われます。スキッププログラムは自然言語処理の手法Word2Vecのアルゴリズムの1つです。CNNの場合は、猫の画像の判別を行った後に犬の画像の判別をさせても、ネットワークではさっきは猫だったから今回も猫?のように前の判別結果の影響を受けません。RNNでは同じ「ます」という単語の判別でも、直前が「行い」であれば、それに影響を受けて「丁寧語」と判断したり、直前が「美味しい」であれば、それに影響を受けで「食べ物の名前(鱒)」と判断するなど、前のデータの影響を受けます。
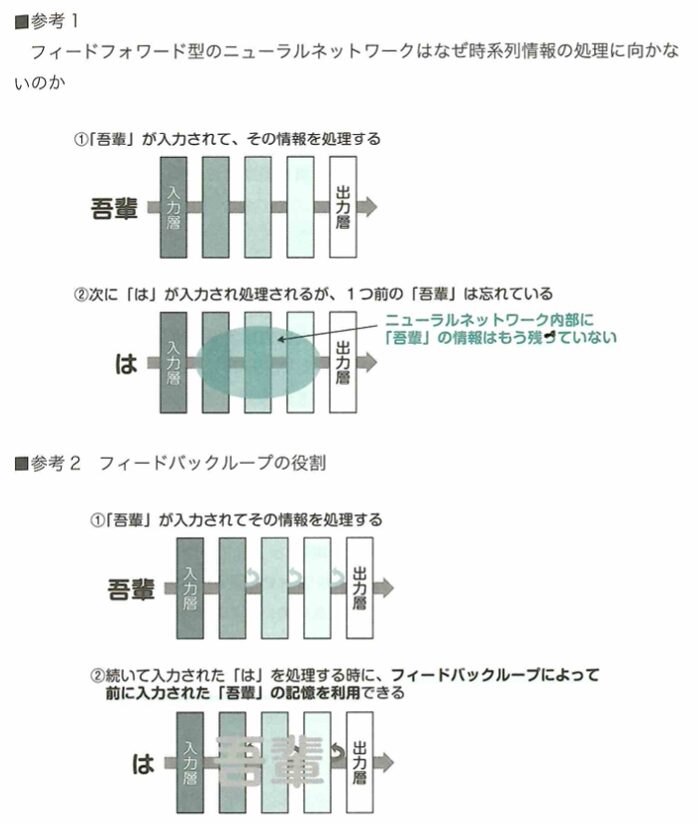
次元削減は教師なし学習の一種です。隠れ層の中で入力と出力の関係性が重みとして表現されます。RNNでは異なる隠れ層の間の繋がりに加えて同じ隠れ層の過去と現在の状態の間にも繋がり(情報の伝播)があるので、過去の情報に基づいて次に来る情報が保つべき重みを学習します。プーリング層ではCNNの一部であり、ここでは画像を圧縮することで、被写体のわずかな動きが予測結果に影響しないようにするための処理を行います。
RNNにはフィードバック機構があり、一度処理した情報が再び同じ層に入力されます。RNNでも勾配消失問題が生じます。セルにフィードバック機構を持つので、時間方向に展開すると時間のステップ分だけ非常に深い構造になります。一般的なニューラルネットワークより勾配消失問題が発生しやすいです。系列が長くなるにつれて時間軸方向の重みの不均一により精度が落ちます。情報を書き留める機能を持つLSTMによりある程度改善されましたが、一定の長さ以上の文章の解析にはやはり向きません。ニューラル機械翻訳に関してRNNの代わりにTransformerを用いた長文に適したモデルが採用されます。RNNの隠れ層の中で、データを1つずつ時間の流れに沿って処理しており、並列演算はできません。
RNNは可変長の入出力に対応できます。機械翻訳などの文章では、入力文章と出力文章で単語数が一致しない場合がよくあります。RNNではCTCという仕組みを用いて可変長のデータを扱えるようになっています。CTCは、入力系列長と出力系列長が一致しない場合に、空白文字(blank)を加えて処理することで形式的に系列長を揃える技術です。これに対してCNNなどのモデルは原則として、入力画像を同じサイズになるようにトリミング、または拡大縮小しないといけません。つまり固定サイズの画像のみ許容されます。
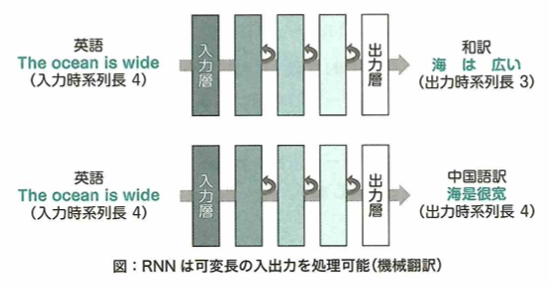
RNNを時間方向に展開すると非常に長い順伝播型モデルになります。モデルの最適化は一般的なニューラルネットワークと同様に誤差逆伝播法が適用されます。RNNの時はBPTTと言います。LSTMでは複数種類のゲートを取り入れて情報制御を行い、長期的に保存したい情報をメモリに書き留め、不要な情報を忘却する仕組みです。長期的に保持したい情報を保存するセルをCECと言います。VAEはオートエンコーダを活用した生成モデルです。入力画像の特徴量を統計分布に変換し、そこからデータ点をランダムサンプリングし、デコーダにより復元して新たな画像データを生成します。例えば手書きの風景画像を入力して、似ているが実際には存在しない写真風の風景画像を生成します。
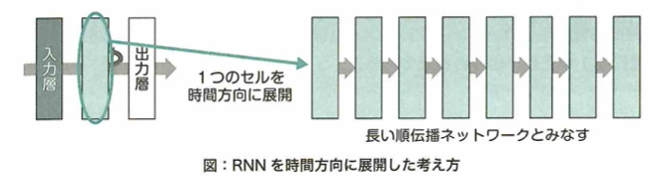
ニューラルネットワークの技術を活用し、画像に写っている物体の説明を自然言語で生成する技術をニューラル画像脚注付け(NIC)と言います。画像処理と自然言語処理を融合したマルチモーダル技術です。画像認識モデルと文章生成用モデルを組み合わせています。
RNNの長文などの長い系列をうまく扱えない原因は、勾配消失問題によって入力側に近い重みが適切に更新されないことと、重み衝突問題の2つです。LSTMはRNNを改良したものです。ゲート構造には入力ゲート、出力ゲート、忘却ゲートがあります。勾配消失問題について、時間の遅い側(出力側)に近いほうの勾配が大きくなり、重み更新にいおいて重視され、早い方(入力側)の重みは不適切に更新されます。重み衝突問題とは、A-B-C-Dという時系列を考えます。AはCの解釈に不要だが、Dの解釈に重要とします。この場合、Cから見るとAの重みは小さくしたいが、Dから見るとAの重みは大きくしたいです。この時間間の違いにより重みが衝突します。
LSTMブロック内のセルであるCECは誤差を内部に止めることで勾配消失を防ぐ効果があります。VGGはILSVRCで準優勝したCNNモデルです。LODはウェブ上でコンピュータ処理に適したデータを公開するための技術です。GRUはLSTMを簡略化した手法です。リセットゲート、更新ゲートの2種類があります。
CNNの構造は以下です。畳み込み層では入力画像から特徴を抽出します。フィルタを用いて画像同士の畳み込み演算を行います。そして特徴マップが生成されます。これをCNNの次の層への入力データとして渡してより高度な特徴量を抽出するための材料として用います。
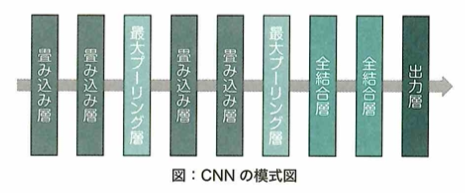
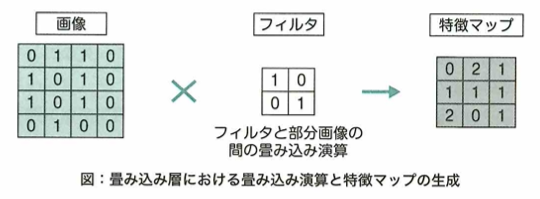
プーリングは入力データにおける重要な特徴を残しつつ画像の情報量を圧縮する操作です。些細な位置変化によって認識結果が変わらないようにする効果があります。畳み込み層とプーリング層を交互に使うことで特徴を検出できるようになります。
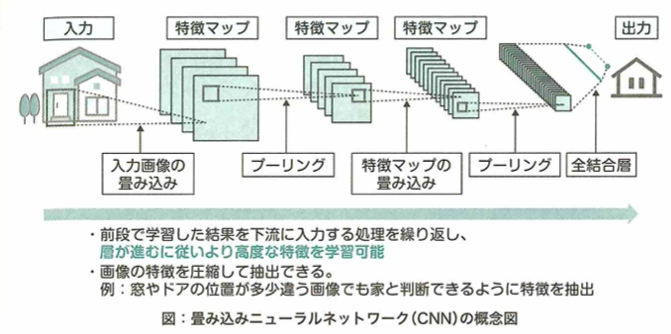
Lpプーリングは特定の領域の中の値をp乗し、足し合わせた上で、p乗根を求める手法です。
GoogLeNetは2014年のILSVRCで優勝したインセプションモジュールを用いた横に広がりを持つ構造が特徴です。派生モデルにinception-v3、inception-v4、inception-ResNetなどがあります。ResNetはスキップ結合構造を用いて、層を飛び越えた層ごとの結合を行うことで勾配消失を防止し、結果として非常に多くの多層のネットワークを表現できます。
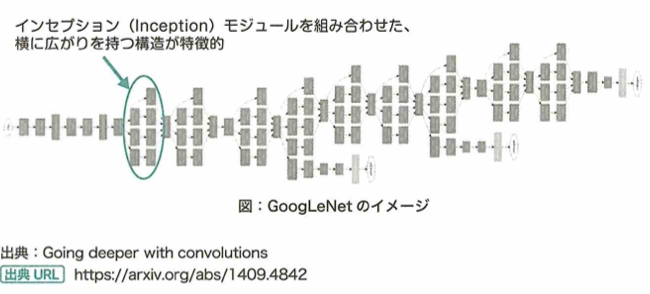
ILSVRCは2010年から始まった毎年開催される画像認識の競技会で2017年以降はkaggleの中で開催されています。Signateは一般の機械学習の競技会です。ImageNetは多くのCNNの学習に用いられた世界的に有名な巨大な画像データセットで、ILSVRCで行われたタスクの学習材料にもなりました。ResNetは2015年にILSVRCで優勝したCNNモデルです。人間の認識精度といわれる5%を超えました。1000層でも勾配消失を抑えた学習が可能です。2015年の大会では152層でした。
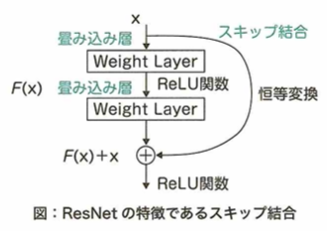
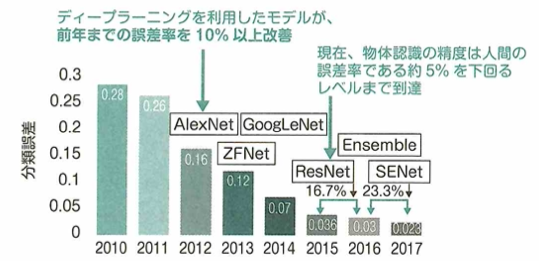
Fashion MNISTは靴や洋服など10種類のファッションアイテムのグレースケール画像のデータセットです。CoLAは画像認識でなく「文の文法の正確さを測定する」自然言語タスクのためのデータセットです。CIFER-10は動物や乗り物のカラー画像データセットです。Fashin MNISTやCIFER-10もクラス数は10でボリュームは数万枚です。ImgeNetは1400万枚以上で教師ラベルのカテゴリは約2万種類程度で桁違いです。クラスラベルについて、WordNetという概念辞書を用いることで上位語、下位語を使用できます。例えばダルメシアンの上位語は犬などです。
ILSVRCは誤差率の低さを競います。top-1 error rateであれば、分類ラベルとして上位候補5個をモデルに提示して、その中の出力確率が一番高い候補が正解と一致するかで判断します。Top-5 error rateであれば、分類ラベルとして上位候補5個をモデルに提示させ、その中に正解が含まれるかで判断します。
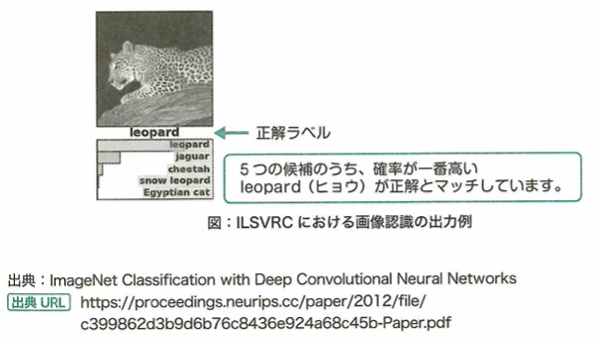
EfficientNetは広さ、深さ、解像度を最適化しながらスケール調整して、小さなモデルで効率よく高い精度を達成したCNNモデルです。このスケーリングの法則をCompound Coefficientと言います。幅は1レイヤーのサイズ(=ニューロンの数)、深さはレイヤーの数、解像度は入力画像の大きさです。開発当時の最高水準の精度を上回り、従来のモデルよりパラメータ数を減らすことに成功しています。EfficientNetはCNNモデルであり、最適化アルゴリズムではありません。転移学習との相性も良いです。
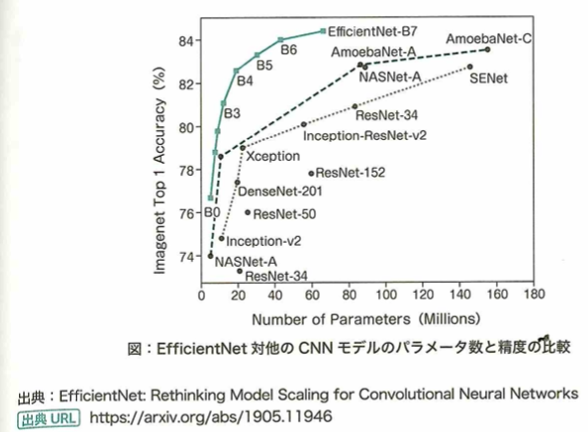
学習データの文字列を数値化するための手法として、One-Hot エンコーディングとラベル・エンコーディングがあります。One-Hot ベクトルに変換すると列の数が増えます。ラベル・エンコーディングを用いると、1つのクラスに1つの番号を割り当てるだけなので列の数は増えません。目的変数は学習データの構造上1列にとどめる必要があります。
パディングは画像(特徴マップ)のサイズを調整し、画像の端にある特徴量を抽出しやすくします。
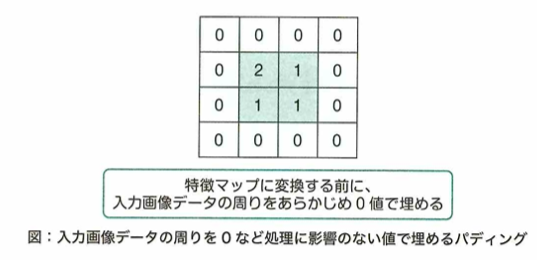
画像処理を用いたタスクは、画像のクラス分類、物体検出、物体セグメンテーション、異常検知、画像生成などです。スマートスピーカーは音声処理と自然言語処理を用います。Actor-Criticは強化学習のアルゴリズムです。AlphaGoはCNNが使われています。機械翻訳は自然言語処理技術です。グリッドサーチは機械学習におけるハイパーパラメータの最適化手法です。
DQN(Deep Q-Network)はDeepMind社によって開発された深層強化学習の手法です。AlphaGoにも使用されました行動探索の範囲を広げるためにε-greedy法を用います。常に価値の高い行動を選び続けるgreedy法の際に行動の探索範囲が狭くなる欠点を改善したものです。DQNでは意図的に外乱を与えています。Q値は行動価値関数つまりQ関数を効率的に推定します。Q学習では各時刻のある状態の下でとった行動に対する価値(Q値)をQテーブルで管理し、行動するごとにQ値を更新します。状態sを基点として行動aを選択肢、その行動をとって状態s’に移行します。続いて行動価値関数Q(s,a)を更新したいので、最も価値の高い行動a'と状態s’の組み合わせ(s',a')を用いてQ値を更新します。ロボットの滑らかな動作など行動の組み合わせが無数に膨らむ際は、Q関数をニューラルネットワークを使った近似関数で求めることで、Q値を現実的な時間内で更新できるようになります。ノイジーネットワーク、ダブルDQNなど学習の安定性や高速化を目指したDQNの改良版が開発されました。
SARSAは強化学習における学習法で、実際にエージェントを行動させることで得られた次の状態における評価を参考に、少しずつQ値を更新し、行動を最適化します。ブルートフォース法は総当たり攻撃であり、考えられるすべてのパターンを試す方法です。
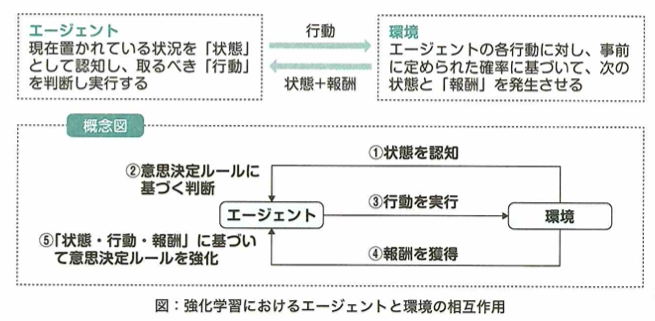
強化学習における活用(一連の試行錯誤の後に報酬が最も高かった行動を選択しようとする)と探索(より高い報酬をもたらす別の行動がないか探す)はトレードオフの関係にあります。パンディットアルゴリズムは活用と探索のバランスを目指し、同時進行または交互に行います。探索は経験を蓄積するために行動することで、活用は経験を活かして行動することです。
DQNが開発された当初は、1ステップごとにそのステップ内容を学習しました。学習内容の時間的な相関が過学習を引き起こし、学習が不安定になりました。そこでDQNに取り入れたのはExperience Replay(経験再生)です。バッファーに各ステップのサンプル(各時刻の学習内容)を保存して、バッファーから一度に複数のサンプルをランダムに抽出し、ニューラルネットワークのミニバッチ学習を行う仕組みです。これによりサンプル間の相関による影響を軽減できました。学習内容とはエージェントが試行錯誤したサンプルです。時間的な相関とは、時刻tの学習内容と時刻t+1の学習内容が似ているということです。時刻が隣り合わせであればこのような相関があるのは自然です。各時刻でエージェントから得られた学習内容のサンプルをexperience、バッファーから一度に複数のサンプルをランダムに抽出することをreplayと言います。
方策勾配法では方策をパラメータで表現し、パラメータを勾配降下法を用いて逐次的に更新しながら、累積報酬の期待値が最大になるように、直接的に方策を最適化します。TD(時間的差分)学習は実際の経験(エージェントと環境の相互作用)に基づく強化学習の手法です。実際にエージェントを行動させ、次のステップ状態で価値を確認しながらQ値を更新していきます。行動を最適化することで方策を間接的に改善していくアプローチです。Q学習とSARSAは共にTD学習を行う手法ですが、違いがあります。Q学習はQ値の更新に用いる行動を現在の方策に基づいて決めるのではく、最大の価値をもたらすと推定される行動を用いてQ値を更新します。方策オフのTD学習と言います。SARSAは各ステップでその時の方策に従って実際に選択した行動を用いてQ値を更新しますので、方策オンのTD学習と言います。報酬を最大にする行動を取るために、最適な方策を直接求める、行動価値関数を最大にするような行動を求める2つのアプローチがあります。前者は方策勾配法があります。ロボットの制御などで用います。後者は行動価値関数(Q関数)を用います。行動価値関数Q(s,a)は特定の状態sにおいて特定の方策に従って行動aを取った際に、将来もらえる価値(累積報酬の期待値)を表します。行動価値関数が最大になるような行動を導くことで、最適な行動を選択する能力が間接的に求められます。つまりロボットの制御などで用いると計算量が膨大になります。
オートエンコーダでは外部から出力に対する正解が与えられるわけでなく。エンコーダとデコーダで形成されるモデル内部において、次元削減や特徴量抽出を行うことが本質です。隠れ層では入力されたデータを一度圧縮し、重要な情報のみ抽出し、不要な情報を削ぎ落とします。このような効果を実現するには、オートエンコーダにおける隠れ層のノードの数は入力層と出力層のノードの数より少なくする必要があります。続いて出力層において、入力層と同じデータになるように復元を行います。
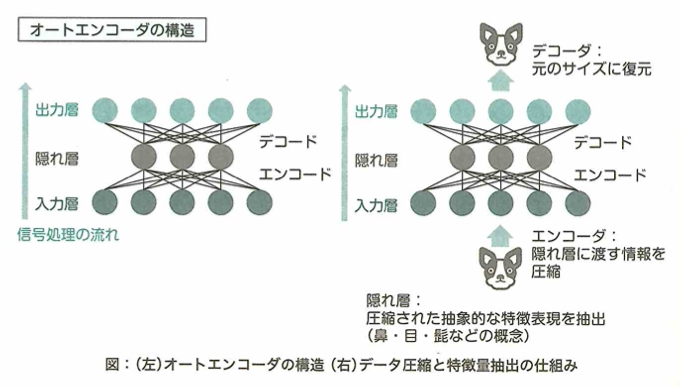
入力と出力を同じデータになるように要求することで、データを最もよく代表する情報を抽出するように隠れ層の重みが最適化されます。全結合層は隠れ層の全ニューロンが前後の層のニューロンと接続された状態にある、一般的なニューラルネットワークの基本構造を指しています。可視層はオートエンコーダにおける入力層と出力層を指します。プーリング層はCNNにおいて特徴マップのダウンサンプリングを行う部分です。オートエンコーダのエンコーダを通して次元削減や特徴量抽出を行う仕組みは勾配消失および過学習を抑える効果があります。かつてニューラルネットワークの事前学習にはオートエンコーダが使用されていました。現在はReLU関数を活性化関数に用いることで勾配消失問題が軽減できるようになりました。ここでの事前学習は、オートエンコーダを用いてニューラルネットワークの重みの初期値を事前に推定しておくことです。初期値をランダムに設定した場合に比べて層を深くしても勾配消失が抑えられます。事前学習では複数のオートエンコーダを積み重ね、順番に学習させる積層オートエンコーダが使用されます。このとき、前のオートエンコーダの隠れ層が次のオートエンコーダの可視層(入力層と出力層)になります。積層オートエンコーダの終端に、ロジスティック回帰層でなく、線形回帰層を足すことで回帰に使用できます。ファインチューニングとはオートエンコーダの文脈では、積層オートエンコーダの終端に、新しいタスクの出力をするためにもう1つ層を追加すること、および出力層を追加した後に、再度ネットワーク全体の仕上げ学習を行うことを指しています。例えば、分類問題についてロジスティック回帰層を、回帰問題に対しては線形回帰層を追加します。その後、ネットワークの下流の重みを中心に再調整することで新しいタスクのためにモデルを最適化します。
ディープラーニングの手法(2)
画像分類など有名なタスクや新しいモデルの名前と中身について、しっかりと押さえておく必要があります。話題となった手法は把握できるようにしておくとG検定への合格へ近づきます。
画像認識
CNNを用いた代表的なモデル
CNNのモデルについて考えます。画像認識の分類精度を競う大会であるILSVRC(imagenet large scale visual recognition challenge)においてAlexNetと呼ばれるCNNを用いたモデルが注目を浴びて以来、CNNを用いたモデルが良い成果を出しています。2012年にAlexNetが1位を出してILSVRCにおいて初めて深層学習の概念を取り入れました。2014年にGoogLeNetが1位となりinceptionモジュールという小さなネットワークを積み上げた構造をしています。2014年にVGGI6が2位となり、サイズの小さな畳み込みフィルタを用いて計算量を減らしています。2015年にResNetが1位となり、層を飛び越えた結合(Skip connection)をしています。
GoogLeNetの特徴の1つは、Inceptionモジュールと呼ばれる小さなネットワークを積み上げた構造をしていることです。
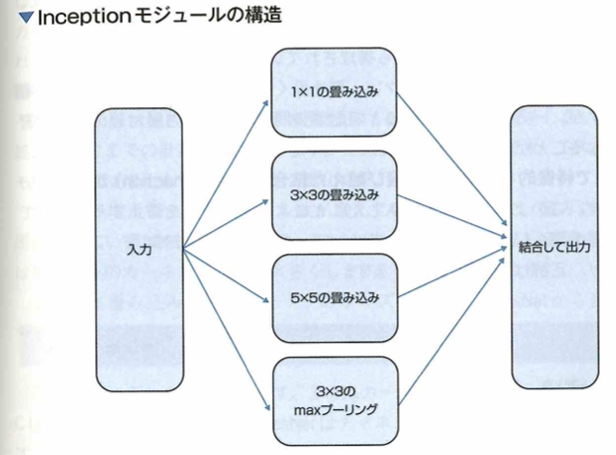
Inceptionモジュールは3つの異なるサイズの畳み込みフィルタと3×3のmaxプーリングから構成されます。Inceptionモジュールは入力画像に対して、各畳み込みフィルタとmaxプーリングをそれぞれ行い、その後これらの出力を結合して出力します。 実はこのモジュールを用いたブロックは、5×5の畳み込みフィルタを複数個持つ畳み込み層で同じものが表現できます。Inceptionモジュールでは、このような畳み込み層と比較して、表現力を維持したままパラメータ数を削減することが期待できます。 次にVGG16は、このように13層の畳み込み層と3層の全結合層の合計16層から構成されているモデルです。 VGG16では、3×3の小さな畳み込みフィルタのみを用いた上で、層を深くしたという特徴があります。 畳み込み演算において、5×5の畳み込み1回と3×3の畳み込み2回の出力を比較したとき、これらの出力ピクセルに含まれる情報は、元画像の同じ範囲から計算されたものになります。 一方で畳み込みフィルタに含まれるパラメータ数は、3×3の畳み込みフィルタ2枚のほうが5×5の畳み込みフィルタ1枚のときより少なくなります。 このことから畳み込みフィルタのサイズを小さくし、層を深くすることで、表現力を維持したままパラメータ数を削減できることがわかります。したがって、過学習を防止するなどさまざまなメリットが得られるようになります。 最後にResNetは、最大152層から構成されているネットワークです。 基本的にニューラルネットワークは、層を深くすることで表現力が増えると考えられますが、一方で層が深くなると勾配消失問題により入力層付近の層が学習できなくなることが課題でした。 ResNetで特徴的なのは、層を飛び越えた結合(Skip connection)があるという部分です。このような構造を導入したことにより勾配消失を防止することができ、より層を深くした表現力の高いネットワークとなっています。
Wide ResNet
ResNetは通常のCNNにResidual blockを導入することにより多層化に成功しました。これによりモデルを深くすればするほど精度が上がることが示されました。しかし、深さだけでなく同様に幅も重要ではないかと考えた研究もあります。その1つにResNetの派生としてWide ResNetがあります。ResNetの幅をよりwideにすることでモデルを深くすることなく高精度を出しました。ここでいう幅とは畳み込み層の出力チャネル数のことである。さらにWide ResNetはResidual block内にDrop outを入れることで過学習を防ぐ効果があることを示しました。Wide ResNetはResNetに対して精度以外にも計算速度を上げるという効果も期待できます。
ディープラーニングは層を深くすることで入力に近い層の勾配が消失してしまう問題があり、ある程度以上は深くできませんでした。その問題に対してResidual blockを導入することで、勾配消失を防ぐことができ、層を多層にすることが可能となりました。Residual blockを使うResNetでは、層を多層にすることで精度が上がることが示されました。 このResidual blockとは、ある層に与えられた信号を、それよりも少し出力側の層の出力に追加するスキップ接続(ショートカット接続)により、深いネットワークを訓練できるようにすることで、入力に近い層の勾配が消えないようにするものです。 層を深くすることは、モデルの自由度が上がるため、過学習する可能性が高くなります。 また、層が深くなることで計算量も増加するため、学習速度は遅くなります。層が増えることでパラメータ数が増えるため、メモリの使用量も増えます。
Wide ResNetは通常のResNetの各層へ読み込むチャネル数を定数倍します。畳み込み層のカーネルサイズやdilation rate、畳み込み層の数はベースとなるResNetで決定されています。層を深くしないため、最終的な出力までの計算が速く済みます。その代わり幅が広いため、GPUなどのメモリ使用量は増えます。 層の幅が増えることはチャネル数が増えているだけなので、畳み込み処理で画像内の広い領域を見ようとしているわけではありません。広い範囲を見る場合は畳み込みのカーネルサイズを大きくします。また、各層読み込み後の特徴マップのサイズは元となるResNetから変わらず、チャネル数が増えます。
3x3はカーネルサイズ、ReLUは活性化関数、Cはチャネル数のことでWide ResNetはチャネル数が増えていることがわかります。実際にはここにバッチ正規化やDropoutなどが入ります。
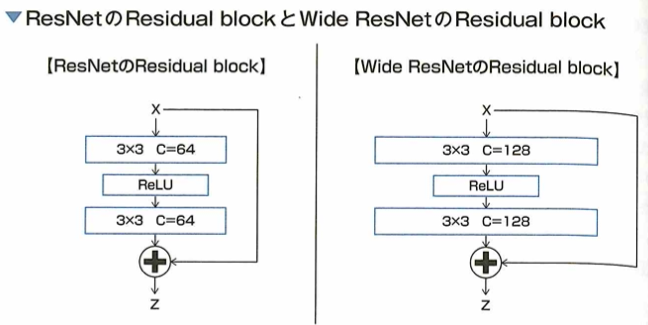
DenseNet
ResNetはある畳み込み層の出力をそれよりも出力側に近い畳み込み層の出力に追加することで、層を深くすることによる勾配消失問題を解決しました。これをResidual blockと呼ばれ、ある畳み込み層の出力とそれよりも出力側に近い畳み込み層の出力同士を足し合わせます。このResNetの派生としてDenseNetがあります。DenseNetはResNetに対してDense blockというものを使います。このブロック内ではResNet同様各畳み込み層の出力がそれよりも出力側に近い畳み込み層の出力に追加されるが、ResNetとは異なり出力同士をチャネル方向に連結します。さらにDensNetではブロック内の各層の出力が以降の畳み込み層すべてに直接追加したため、特徴量の伝達が強化されています。
DensNetについて、特徴マップのサイズに関しては、入力の画像サイズや畳み込みのカーネルサイズなどに依存するためDenseNetの構造で特徴マップの大きさが大きくなるわけではありません。 層の出力同士が連結されることでチャネル方向に増えていますが、各層の出力はチャネル数が増えているわけではありません。 また、スパースとは情報量が希薄な状態を指します。これをDense blockと呼んでいます。
ResNetとDenseNetの違いを以下の図に示します。Cはチャネル数です。Dense blockではチャネル方向に出力を連結するため、入力のチャネル数が後半の層で増えていることがわかります。 さらに各層の出力がすべての後ろの層に連結されています。実際には3=64チャネルではなく3→12チャネルといった少ないチャネル数でも高精度を出すことが論文では示されています。また、バッチ正規化などもDense block内の各畳み込み層の前に導入され、このブロックの出力に1×1カーネルサイズの畳み込みとAverage Poolingがされています。 ただし、最後のDense block後は、Global Average Poolingが適用され、その出力が全結合層に入力されます。
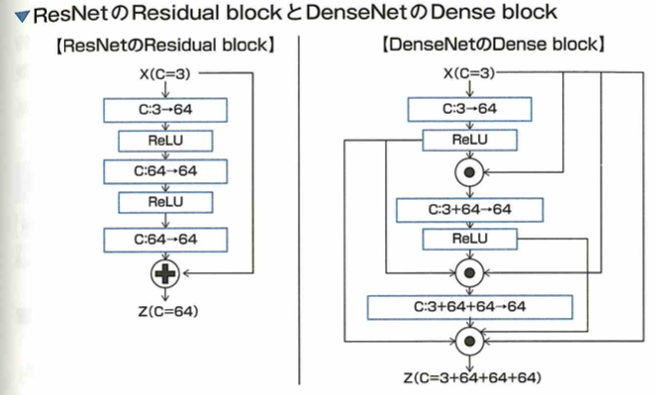
SENet
CNNは畳み込み層を複数用意することで画像認識分野において大きな貢献をもたらしました。特に層を深くして高精度を出したResNetや、畳み込み層の幅を大きくして高精度を出したWide ResNetなどがあります。中でもSqueeze-and-Excitation Networks(SENet)は畳み込み層の特徴マップの各チャネル情報に注目した派生モデルです。その特徴マップの各チャネル情報から各チャネルの重みを考慮することで重要なチャネルを際出せることが期待できます。
SENetは畳み込み層の出力特徴マップのチャンネル間の相互依存性について着目し、モデルのアーキテクチャを提案しました。これは特徴マップの各チャンネルの平均値をそれぞれ求め、それらを全結合層に通して代表値を求め、それぞれを元の特徴量に掛け算します。例えば、16チャンネルある特徴マップに対して16個の平均値を求め、全結合層で重要度を作成したあと、16個の代表値が得られ、それを元の16チャンネルの特徴マップに掛け合わせます。
「チャンネル毎のカーネルサイズ」を変える手法では、MixConvというものが提案されています。 「出力のチャンネル数」は、畳み込み層の幅のことなので、これに対してWide ResNetが提案されています。 「特徴マップのサイズ」は、畳み込み層のカーネルサイズやスライドサイズに依存します。SENetは特徴マップにそれぞれの代表値を掛けるため、重要度が高いチャンネルの特徴マップは強調されます。
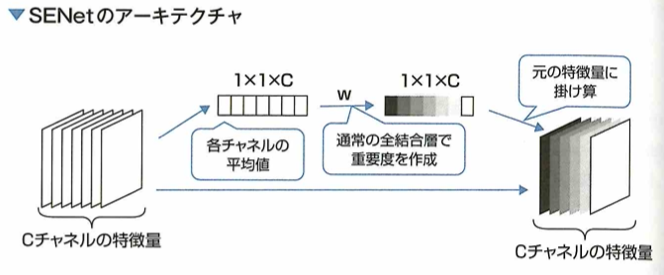
物体検出
物体検出について、画像に写っている物体をバウンディングボックスと呼ばれる矩形の領域で位置やクラスを認識します。
物体検出を行う手法は、R -CNN、YOLO、SSDなどが存在します。画像分類とは、画像がどのクラスに属するのかを予想することです。セグメンテーションとは、画像に写っているものをピクセル単位で領域やクラスを認識することです。画像生成とは、敵対生成ネットワークや変分オートエンコーダなどを利用し、画像を生成することです。
R-CNNは2014年に発表されたCNNを用いた物体検出モデルです。YOLOは物体検出手法の1つで検出と識別を同時に行います。SSDとは物体検出手法で、特徴の1つに小さなフィリタサイズのCNNを特徴マップに適応することで、物体のカテゴリと位置を推定することが挙げられます。
R-CNNとFast R-CNN
物体検出は、深層学習以前では、人手で画像から良い特徴量を抽出するように設計されていました。たとえば、スライドウィンドウ内の輝度ヒストグラムを使って特徴抽出をして物体検出をするhistogram of oriented gradients(HOG)という手法があります。 しかし、畳み込みニューラルネットワーク(CNN)が登場し、ImageNet Large Scale Visual Recognition Challenge(ILSVRC)という画像認識コンペティションにおいて非常に高い精度を出しました。そこで、物体検出においてCNNを使うことが提案されました。 最初は1枚の画像を大量の領域に分けてCNNに入力し、領域毎に背景、物体を認識して最終的に1枚の画像内の物体検出を行います。
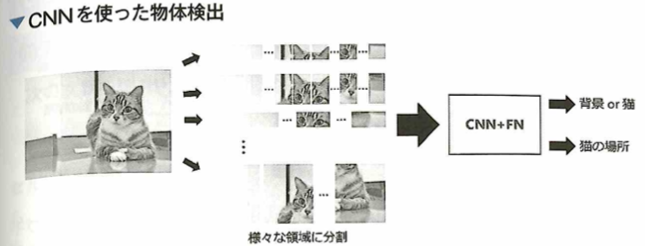
図のように画像をさまざまなサイズに分割し、それが背景なのか物体なのか、またその画像内のどの部分が物体なのかを判断します。ここでFNとはFully connected layer(全結合層)のことであり、クラス分類用とバウンディングボックス(bbox)の位置特定用の2つ用意されています。この手法の特徴はCNNを使うため高精度を出しましたが、分割数が非常に多く処理速度が非常に遅かったです。この手法をより良くしたのがR-CNN(Regional CNN)です。R-CNNは分割した画像をすべてCNNに掛けるのではなく、物体がありそうな領域を探してそれらのみを検出器であるCNNに入力します。この物体がありそうな領域をRegion-Of-Interest(ROI)と呼び、これを探し出すモデルをRegion Proposalと呼びます。
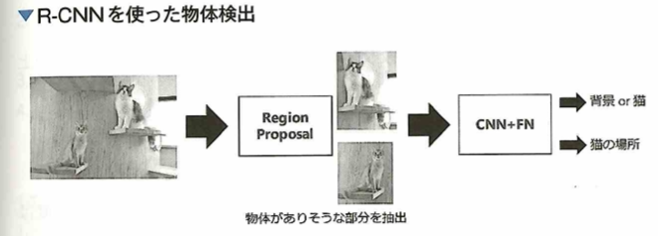
図のようにRegion Proposalは、画像中の物体がありそうな部分を切り出し分割します。それらの分割した画像毎にCNNを使って物体検出をします。この手法の特徴は画像中の物体のありそうな部分のみを使うため処理速度が向上したことです。この手法をさらに改善したものとしてFast R-CNNがあります。これはRegion Proposalで切り出す部分を画像ではなく画像の特徴量にすることでR-CNNを高速化しました。
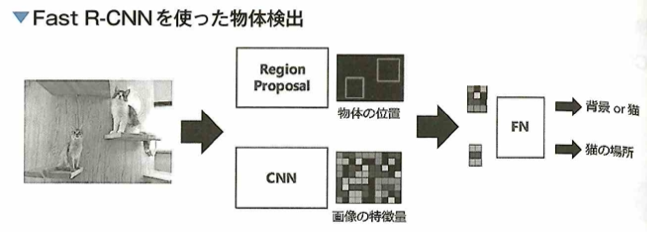
このようにFast R-CNNはRegion ProposalとCNNを並列して実行します。この手法の特徴はFast R-CNNはR-CNNに対してCNNを使う回数が1回で済むので、高速化に成功したことです。
Region Proposalは深層学習ではなくSelective Searchという手法で行うため、これ自体に処理時間がかかり、処理速度は絶対的に遅いままでした。さらにRegion Proposalで分割した枚数が多いと、その数だけCNNを使うため、処理時間がかかる場合もありました。このRegion Proposalを深層ニューラルネットワークでさらに高速化したものに、Faster R-CNNというのも存在します。これは2015年にマクロソフト社が開発した物体検出アルゴリズムです。
セグメンテーションの基本
セグメンテーションとは、画像全体や画像の一部の検出ではなく、ピクセル一つ一つに対して、そのピクセルが示す意味をラベル付けするタスクです。このタスクは、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーションなどさらに細分化されます。それぞれの特徴として、セマンティックセグメンテーションは背景、猫、車といったカテゴリごとにピクセル単位でクラス分けします。 インスタンスセグメンテーションはそれぞれの人や車などといった物体ごとにクラス分けを行い、背景などの数が得られないものはクラス分けを行いません。 パノプティックセグメンテーションは、背景、猫、車といったカテゴリごとにクラス分けをしつつ、それぞれの人や車などといった物体ごとのクラスも判別します。 セグメンテーションは画像を入力とするため、畳み込みニューラルネットワーク(CNN)を活用することで高い精度を得ることができました。 たとえば、セマンティックセグメンテーションに対してFully Convolutional Networks(FCN)と呼ばれるモデルが提案されました。これの特徴はすべての層が畳み込み層のみで構成されています。
セグメンテーションは、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーションの3種類があり、それぞれの特徴は次の通りです。 たとえば、セマンティックセグメンテーションは、オブジェクトそのものをカテゴリライズしたいときに使うことができ、インスタンスセグメンテーションは物体を個別に分類したい際に使え、パノプティックセグメンテーションはその両方をしたいときに使うことができます。
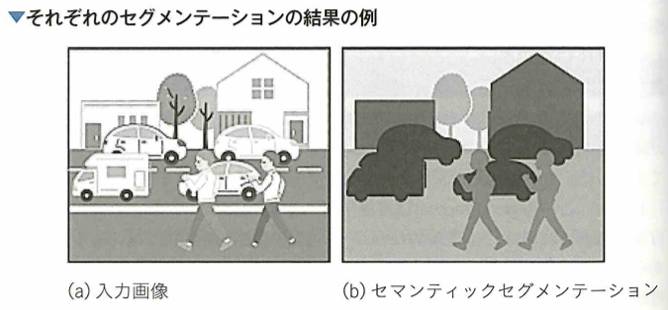
セマンティックセグメンテーションに対して、CNNを用いた手法がFCN (Fully Convolutional Networks) です。これはすべての層が畳み込みのみで構成されているため、任意のサイズの入力を受け取って、セグメンテーションをすることができます。U-Netはオートエンコーダ形式でエンコーダからデコーダへのスキップコネクションがあります。SegNetはオートエンコーダ形式で、デコーダ時の特徴マップの拡大の仕方をpooling時の位置情報を用いて工夫しました。FPNは特徴マップをピラミッド型に伝播していきます。
SegNetは2017年に提案されたセマンティックセグメンテーションを行う手法の1つです。入力画像から特徴マップの抽出を行うEncoderと、抽出した特徴マップと元の画像のピクセルの位置の対応関係をマッピングするDecoderで構成されています。U -Netはセマンティックセグメンテーションの手法の1つです。全層畳み込みネットワークの一種で畳み込まれた画像をdecodeする際にencodeで使った情報を用いるのが特徴です。
セグメンテーションの理解
セグメンテーションは、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーションというタスクに細分化され、それぞれに対してさまざまな深層学習モデルが提案されています。 セマンティックセグメンテーションに対して最初に畳み込みニューラルネットワーク(CNN)を使ったFully Convolutional Networks(FCN)があります。これはすべての層を畳み込み層のみで実現していることが特徴です。その他にもオートエンコーダ形式で、デコーダ時にエンコーダ時のpooling位置を参照してup samplingするSegNetMask R -CNNや、エンコーダの出力に異なるサイズのpoolingをし、それらをデコーダに入力するPSPNetや、エンコーダの出力に異なるdilationの畳み込みを行い、それらをデコーダに入力するDeep Labなどがあります。 インスタンスセグメンテーションは、物体検知のモデルを派生させたMask R -CNNなどがあります。 パノプティックセグメンテーションには、ピラミッド構造のようなオートエンコーダを用いてセマンティックセグメンテーションとインスタンスセグメンテーション両方を学習するPanoptic FPNなどのモデルがあります。
SegNetはデコーダ時に特徴マップの拡大の仕方を工夫したモデルです。エンコーダ時のpoolingの位置を保存して、デコーダ時に保存していた位置を使うことでpoolingと対応づけて特徴マップの拡大をするので、up samplingの学習が不要です。
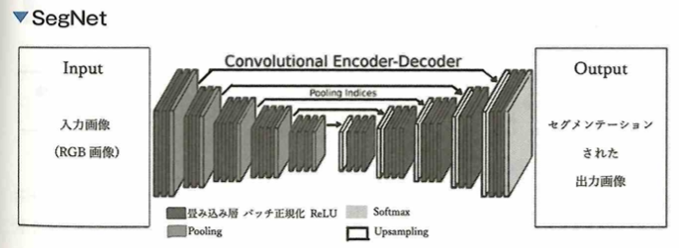
PSPNetはエンコーダの出力に対して異なるサイズのpoolingを行い大域的な特徴と局所的な特徴の両方を得られます。異なるサイズのpoolingをすることで異なるサイズの特徴マップを得ることができ、その特徴マップの特徴をup samplingしてサイズを合わせてデコーダの入力とします。
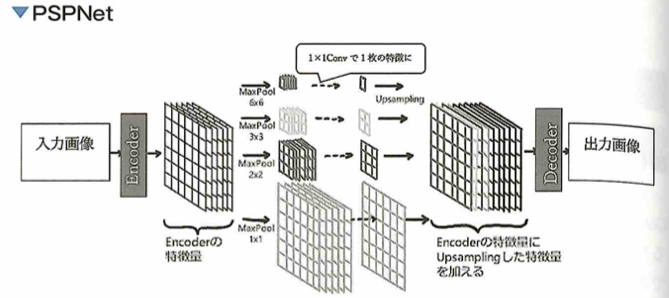
DeepLabはPSPNetと違い、Atrous Convolutionという畳み込みのパラメータ間隔を広げたものを使います。この感覚は畳み込みではdilationと呼ばれます。異なるdilationの畳み込みを行い、異なるサイズの特徴マップを得ます。
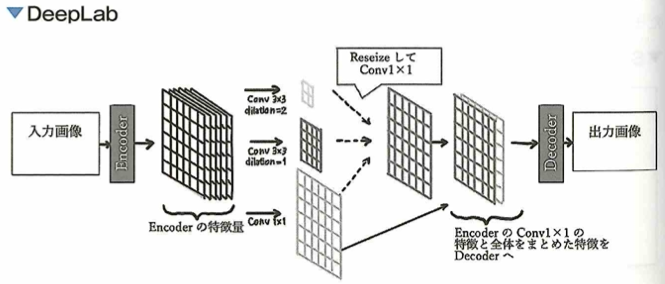
Mask R-CNNは、物体検知モデルのFaster R-CNNをセグメンテーション用に拡張したものです。これにより、物体毎に色分けを可能としました。
OpenPose
画像または動画内の人のポーズや姿勢を推定する姿勢推定というタスクがあります。人のポーズや姿勢推定は、もともと画像中から人を検出する物体検出を経た後、ポーズ推定をそれぞれの検出部分に適応させていました。これはトップダウンアプローチと呼ばれます。しかしこれは人の検出数が増えるほど時間がかかり、リアルタイム性に欠けます。 それに対してボトムアップアプローチと呼ばれる姿勢のキーポイントを直接画像から検出し、それらを繋げる手法があります。その中でPart Affinity Fields(PAFs)という手法が提案されました。これを使うことで、一度に画像内の複数の人に対して姿勢推定ができ、トップダウンよりも高速な推定が可能となりました。このPAFsは検出した間接点同士の結線の繋がりを推論するものです。このPAFsと関節を検出するネットワークを並列にして学習、推論することで高速かつ高精度な検出が可能となりました。
姿勢推定では高速化をするためにPart Affinity Fields (PAFs) を使うことが提案されています。Part Affinity Fields とは検出された関節点のどことどこが繋がるかを推論するモデルになっています。実際には線ではなく点から点へのベクトルの向きを使って繋がりを検出します。このモデルではPart Affinity Fields と関節を検出する2つのモデルを並行に並べて実現されています。
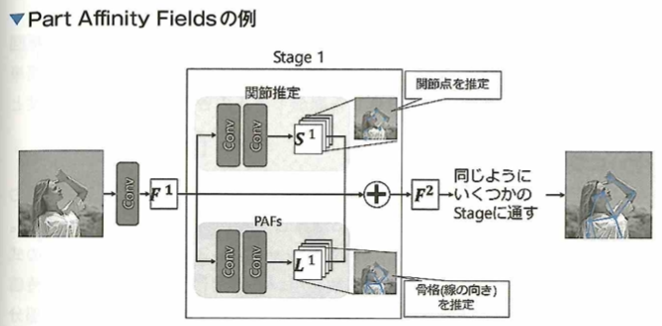
このように、関節推定とPart Affinity Fieldsの2つのモデルで、それぞれを推定させています。これをstage 1とし、何段階か同じ処理を通すことで大域的な部分を見ることができ、より細かく推論が可能となることで高精度な推論結果を得ることができます。
モデルの解釈性
ディープラーニングは、多層にすることによる表現力向上で、さまざまなタスクにおいて高いパフォーマンスを発揮しました。 しかし、ディープラーニングのモデルは非線形で多層なため、モデル自体の振る舞いを理解することができません。そのためディープラーニングはブラックボックスと呼ばれ、モデルの予測結果の判断根拠を解釈することができません。これを解消するためにExplainable AI(XAI)という研究分野が生まれました。単純な線形モデルでは各説明変数にかかる重みが、それぞれの説明変数の重要度と解釈でき、モデルが何を重要としているかを解釈できます。これに目を付け、複雑なディープラーニングモデルなどを線形モデルや決定木などで近似させて説明性を考慮したLIMEが提案されました。その他にも協力ゲーム理論をベースに用いて重要度を測るSHAPも提案されています。これらはテーブルデータ、画像データにも適用できます。画像を扱う上で近年では畳み込みニューラルネットワーク(CNN)が使用されます。 CNNに対してモデルの最後の畳み込み層の特徴マップとGlobal Average Pooling(GAP)後の全結合層の重みを用いて説明性を考慮したCAMも提案されました。これはLIMEやSHAPのように近似をしたり重要度を再計算する必要がなく、学習したモデルにデータを流し、そこで得られる最後の畳み込み層の特徴マップにGAP後の全結合層の重みを加えてデータの注目箇所を可視化します。
NASはモデルの構造事態を探索するタスクです。Feature Pyramid NetworksはU -NetのようにAuto Encoderにスキップコネクションが追加された構造を持ち、特徴マップを拡大していくたびに予測することで、異なるスケールの物体検知やセグメンテーションが可能になるモデルです。PCA(Principal Component Analysis)は主成分分析という次元削減の方法です。
LIMEは複雑なモデルを単純な線形重回帰で近似することで重要度を近似モデルで表現したものです。図でいうと近似した線形モデルの各結線の重みが重要度となっています。SHAPは、シャープレイ値という協力ゲーム理論で使われる重要度を近似的に計算してモデルの解釈性を表現します。SHAPはシャープレイ値を計算するための式を、モデルに対する条件付き期待値関数を用いて近似します。条件付き期待値関数の入力値は、元の入力の重要度を測りたい説明変数を固定して、他の部分をランダムにしたものを入力とします。CAMはモデルの特徴量を取得して活用します。CAMは畳み込み層の最後の出力(Black boxの最後の部分)に着目し、この特徴マップを使います。その特徴マップは、Global Average Pooling(GAP)を経て、最後の線形重回帰に渡されます。このときの各特徴マップと線形重回帰の重みを掛け合わせて足したものがヒートマップとなり、これを入力画像にすることで、モデルが画像のどこに注力したかを判断します。ただしCAMはGAPを持つモデルにしか適用できず、その他のモデルに対してはGrad CAMというものが提案されています。これは特徴量ではなく特徴量の勾配を使うことでモデルの解釈をしたものです。
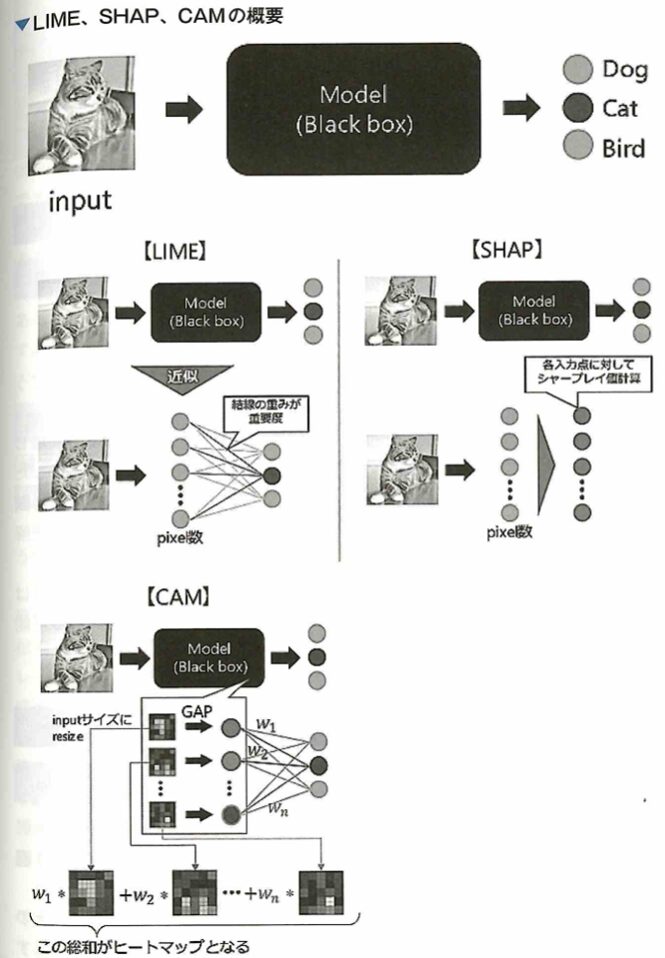
Efficient
EfficientNetの特徴を考えます。これはモデルの深さ、広さ、入力画像の大きさをバランスよく調整しています。
EfficientNetは、2019年にGoogle社から発表されたモデルで、これまで登場していたモデルよりも大幅に少ないパラメータ数でありながら、SoTAを達成した高精度で高速なモデルです。モデルの深さ、広さ、入力画像の大きさをバランス良く調整しているのが特徴です。 DenseNetの特徴は前方の各層から出力すべてが後方の層への入力として用いられており、Dense Blockと呼ばれる構造を持ちます、ResNetの特徴は最大152層から構成されているネットワークを持っており、Skip connectionがあります、GoogleNetの特徴はInceptionモジュールという小さなネットワークを積み上げた構造をしています。
ドメインアダプテーション
深層ニューラルネットワーク(DNN)の研究が進んだことで、画像の識別などのタスクにおいて高い性能が達成されるようになりました。しかし、DNNを用いた識別モデルの学習には、大量の教師ラベル(正解ラベル)付きサンプルが必要となるため、少ないデータで学習できる手法や他のデータセットのラベルを流用するなどの手法を模索されていました。中でもドメインアダプテーションという手法があります。ドメインアダプテーションとは、すでに教師ラベルが準備されたデータ(ソースデータ)で学習されたモデルを目標のデータ(ターゲットデータ)に利用する際に用いる手法の1つです。ドメインとは「何についてのデータか」というデータの種類や形を指し、ソースデータのドメインはソースドメイン、ターゲットデータのドメインはターゲットドメインと呼ばれています。予測対象であるターゲットドメインとは異なる分布であるソースドメインの情報を活用して、モデルの予測性能を向上させることを目的としています。
ドメインが異なるソースデータで学習したモデルをそのままターゲットデータに用いると、精度が大きく下がります。ドメインアダプテーションはこの問題を解決する手法です。精度が大きく下がる原因としてソースデータとターゲットデータの分布の違いがあります。そのためドメインアダプテーションでは、ソースデータとターゲットデータの分布を揃えるアプローチを取ります。Maximum Mean Discrepancyや共分散の指標を使用して分布間の距離を測ったり、敵対的学習を用いたりすることにより分布を揃えています。ドメインアダプテーションは、教師ありドメインアダプテーションに加え、教師なしドメインアダプテーションが提案されています。2015年に発表された"Unsupervised Domain Adaptation by Backpropagation"では、従来の誤差逆伝播の途中にGradient Reversal Layerと呼ばれる層を挿入することで教師なしアダプテーションによりモデルの精度を向上させました。また、ドメイン画像認識の分野において実世界の撮影環境はドメインの1つであるため、撮影環境の違いはドメインの相違に含まれます。
sim2real
近年ではロボットの制御に強化学習を取り入れる研究が進んでいます。強化学習を用いたロボット制御の方策獲得では、安全性の向上やコスト削減を目的としたsim2realが望まれています。sim2realとはシミュレーション環境で方策を学習してから実環境に適用することを指します。しかし、シミュレーション上の環境と実環境ではリアリティギャップと呼ばれる相違が存在します。リアリティギャップが原因で実環境にロボットがうまく適応できない問題が生じます。リアリティギャップを埋めるための方法としてドメインランダマイゼーションが提案されています。ドメインドメインランダマイゼーションにおいて、実環境におけるすべての影響をシミュレーションで再現し学習させることは不可能なので、実環境の行動選択が必ず成功するとは限りません。
シミュレーション環境で方策を学習してから実環境に適用することをsim2realといいます。しかし、シミュレーションと実環境の相違が原因で、ロボットが実環境に適応できない問題が生じています。シミュレーションと実環境の相違をリアリティギャップと呼び、リアリティギャップを埋める手法としてドメインランダマイゼーションが提案されました。ドメインランダマイゼーションとは、質量や摩擦係数といった物理パラメータ等のシミュレーション環境に関するパラメータをランダムに複数生成することで、それら複数の環境で学習することで、シミュレーションの時点でさまざまな環境における学習を行うことができます。
seq2seqはRNNのモデルの1つです。pix2pixも深層生成モデルの1つです。end2endはデータの変換や出力結果の調整等の必要ない構造のことを示しています。end2endのモデルは生データをモデルに入力するだけで結果が出力されます。OCRを例にすると、通常は文字が書かれた画像に対して、「テキスト検出」や「文字分割」といった細かいタスクを経て文字が認識されます。end2endでは、入力となる文字画像と出力となる文字のラベルのみを与え、「テキスト検出」や「文字分割」などの中間の処理すべて学習させます。
ドメインランダマイゼーションとはシミュレーション環境に関するパラメータをランダムに複数生成することなのです。また、ロボットがカメラで認識する物体の形状や色もランダム化するパラメータとなります。2017年に発表された論文"Domain randomization for transferring deep neural networks from simulation to the real world."では物体の形状や色、素材の質感などのパラメータをランダムに生成して学習を行いました。
自然言語処理
形態素解析と構文解析
自然言語処理には形態素解析、構文解析、意味解析、文脈解析の4つの工程があります。形態素解析とは、文章を「意味を担う最小単位(=形態素)」に分割し、それぞれに品詞などの情報を振り分ける処理です。形態素解析は解析を行う際に辞書を用意しておくことで解析精度が向上する可能性が高まります。構文解析は定義した文法に従って形態素間の関連づけを解析する処理を行います。
形態素解析とは、形態素と呼ばれる言語で意味を持つ最小単位まで分割し、解析する手法です。また、単純に単語を分割するだけでなく、それぞれの形態素の品詞などの判別も行います。そのため、英語は単語毎にスペースが入っている場合が多いですが、例外の存在や、品詞などの情報を付与することが重要です。また、形態素解析を行う上で単語埋め込みモデルは不要です。形態素解析は辞書がなくても行うことができますが、造語や新語などを特定することが難しい場合があり、そういった単語を辞書に登録しておくことで確実な形態素解析を行うことができます。また、文章のトピックを推定する解析ではないです。
構文解析は、文法に従って形態素間の関連付けを解析し、どの形態素がどこにかかっているかを解析することをいいます。また、構文解析を行うことで、形態素間の関係を下図のような構文木にし、係り受け関係が見えるようになります。形態素解析は形態素同士の関係を推測する処理であり、意味を考慮したり文同士の関係を推測したりしないです。文が肯定的か否定的かを判断することは、文の肯定的/否定的を推定する感情分析と呼ばれる自然言語処理の応用分野です。構文解析の工程のみでは文の肯定的/否定的を推定することはできないです。意味解析は意味を考慮して適切な構文を選択する処理であり、文脈解析は複数の文について構文解析と意味解析を行って調整する処理です。
GPT
GPT (Generative Pre-trained Transformer) とは、2018年にOpenAIによって発表された言語モデルです。GPTはベースとなるTransformerに対して、事前学習とファインチューニングを行うことによって高い性能を実現しました。 GPTは後継モデルとしてGPT-2やGPT-3といったモデルが発表されています。GPTは約1億1,700万個のパラメータを持つ大きなモデルであるが、GPT-2では約15億個、GPT-3では約1,750億個となっており、より大規模かつ高精度なモデルとなっています。OpenAIが、悪用されるリスクが高く公開することが危険であるという理由で、最大サイズのモデルの公開を延期し、段階的に公開されたことで話題となったバージョンとして正しいものは、GPT-2です。
オリジナルのGPTは2018年に論文が発表されました。2019年2月にGPT-2が発表され8月にパラメータ数が約8億個のモデルを公開し11月に最大サイズのモデルを公開しました。パラメータ数は15億個です。GPT-3は2020年5月に論文が公開されましたが、パラメータそのものは公開されず、一般の開発者・研究者はAPI経由でのみ利用できる状態です。GPT-3の独占ライセンスはマイクロソフト社が2020年9月に取得しています。これは2021年12月の情報です。
トピックモデルと潜在変数
文書や単語に潜む潜在的なカテゴリーを説明するモデルに、トピックモデルがあります。文書以外でも、たとえば通販サイトにおいて、顧客の購入履歴から商品の潜在的なカテゴリ分けを知ることができます。
トピックとは、意味のカテゴリーのことです。トピックモデルを使うことにより、文書の集まりなどの与えられたデータから潜在的なトピックを推定することができます。トピックを固定されたものではなく潜在的なものとして扱うのは、データセット毎に現れる意味のカテゴリーが変化するためです。また、対象データは文書にとどまらず、離散的な観測データを対象にしたクラスタリングとして広く利用できます。
LDA
トピックモデルの代表的なモデルにLDA(Latent Dirichlet Allocation)があります。LDAでは、1つの文書には複数の潜在トピックが存在すると仮定します。また、具体的な単語などのデータがそれぞれ生成される確率は、トピックごとに異なります。
LDAは、文書集合集合から各文書におけるトピックの混合比率を推定する手法の1つです。1つ文書に複数のトピックがあることを表現できるため、たとえば「ジャガー」という単語が車トピックでもネコ科トピックでも使用されることを表現できます。また、スポーツの記事と政治の記事から「ホームラン」という単語が同じ確率で生成されるとは考えにくいでしょう。LDAでは、各トピックから単語が生成される確率もトピックと同時に推定します。他にもLSI(Latent Semantic Indexing)などが有名です。
bag of words
日本語や英語のような自然言語も、通常のデータと同様テーブルの形にすることで、テーブルデータに対する学習アルゴリズムを適用することができます。例えば、文書の数をk、出現しうる単語の数をnとしたとき、その文書内の出現回数を値に持つk×nのテーブルを作ることができます。このように各文書をベクトルで表現する方法を、bag og wordsといいます。
Bag of Wordsの概念は非常にシンプルです。たとえば、“This is a pen.”という文1と“I have a pen.”という文2があるとき、そのBag of Wordsは下表のようになります。

しかし、一方で欠点もあることに注意が必要です。 文書の長さによる影響が反映できないことや、一般に出現しにくいが、その文書をうまく特徴付ける単語の影響が弱くなってしまうことが問題点としてあります。 たとえば、ある文書が長ければ長いほど、その文書内ではどの単語も総じて出現しやすくなる、といった影響を受けてしまいます。さらに、単語の出現頻度だけが数値となるため、その単語の意味が考慮できていないことも欠点の1つです。
TF-IDF
自然言語を特徴量のテーブルにする手法としてbag of wordsがあるが、より一般的な単語の重みを低くし、特定の文書に特有な単語を重要視する手法にTF-IDFがあります。TF-IDFは、単語の文書内での出現頻度と、その単語が存在する文書の割合の逆数の対数の積で定義されます。
TF-IDFの名前は単語の文書内での出現頻度(Term Frequency:TF)と、その単語が存在する文書の割合の逆数の対数(Inverse Document Frequency:IDF)の頭文字に由来します。 bag of wordsに比ベレアな単語に注目できるようになるものの、依然として文書の長さによる影響が残ることに注意が必要です。
word2vec
自然言語処理を行う際にはコンピュータに単語を理解させるために固定長のベクトルで表す分散表現が重要になります。単語の分散表現を獲得するにはさまざまな方法が存在するが、中でもword2vecはニューラルネットワークを用いた推論ベースの手法で非常によく使われます。また、word2vecにはCBOWとSkip-gramの2つのモデルが存在します。CBOWは、単語周辺の文脈から中心の単語を推定し、Skip-gramは逆に中心の単語からその文脈を構成する単語を推定します。
word2vecは名前の通り、単語をベクトルにする、つまり、分散表現の獲得を行うことのできる手法になります。この分散表現の獲得はさまざまな手法が存在し、以前はbag of wordsなどのカウントベースと呼ばれる、周囲の単語の頻度によって単語を表現する方法が一般的でした。 2013年にGoogle社のトマス・ミコロフの研究チームが開発したword2vecは、ニューラルネットワークを用いた推論ベースの手法として広く使われています。 このword2vecには、CBOWという単語周辺の文脈から中心の単語を推定する方法と、Skip-gramと呼ばれる中心の単語からその文脈を構成する単語を推定する方法の2つのモデルが存在します。この両者を比較すると、Skip-gramの方が、精度が良いと言われていますが、学習コストが高く計算に時間がかかります。
fastText
fastTextはword2vecの後継モデルであり、meta(旧Facebook)社が開発した自然言語処理モデルです。word2vec同様、単語をベクトル化することによって単語間の距離を計算し、コンピュータ上での言葉の処理を可能にしています。 word2vecと異なる点は、単語埋め込みを学習する際に、単語だけでなくその単語を構成する部分文字列の情報も含めることです。 単語以外に部分文字列を考慮することで、訓練データに存在しない未知の単語(OOV:Out Of Vocabulary)であっても単語埋め込みを計算することができます。また単語のベクトル化やテキストの分類を高速で行うことができます。
fastTextはmeta(旧Facebook)社の人工知能研究所が開発したword2vecの後継モデルです。単語埋め込みの学習時に部分文字列を考慮することにより、訓練データに存在しない単語の計算や活用する単語の語幹と言語を分けて学習することを可能にしました。また、fastTextは学習に要する時間が短いという特徴があります。下図に、fastTextにおける部分文字列の学習と言語幹の共有についての例を示します。「play」の活用形について4文字の部分文字列で分割しています。「played」を4文字の部分文字列で切り出すと「play」「laye」「ayed」に分割できます。同様に「playing」は「play」「layj」「ayin」「ying」のように分割でき、共に「play」を含んでいます。「playing」を学習することで部分文字列である「play」を学習できるため、「played」が訓練データになくてもベクトル化の計算ができます。
ViT
Visiion Transformer(ViT)について考えます。自然言語処理分野で使用されているTransformerを画像処理分野に適応したもので、CNNを用いない新たなモデルとして提案されています。
ViT は画像処理分野に持ち込まれた Transformer で、CNN を使わないモデルとして提案されています。入力画像を複数枚に分割しパッチを作成し、そのパッチをベクトル化して Transformer のエンコーダに入力することで画像を言語モデルのように処理します。下図は ViT の概観図です。入力画像を 9 つのパッチに分割し、ベクトル化した後、Transformer のエンコーダに入力しています。Transformer のエンコーダやエンコーダの後に多層パーセプトロン (MLP: Multilayer Perceptron) を使用しています。ViT は画像処理分野での使用を想定して提案されています。また下図が示すように Transformer の前処理に CNN は用いられていないです。
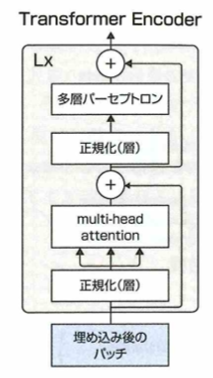
音声認識
音素・音韻の要素とA-D変換、パルス符号変調機
音声は、空気の振動が波状に伝わるものです。人の発話による音声の構成単位は、音素あるいは音韻と呼ばれています。音韻は言語によらず人間が認知可能な音の総称を指し、音韻の最小単位を音素と呼びます。たとえば、/sa/と/si/は人間が区別可能な音であるため、異なる音韻と捉えます。/sa/を最小単位に分けると/s/と/a/という音素を取り出すことができます。音声は時間と共に連続的に変化するアナログなデータであり、コンピュータで処理するためにはデジタルなデータに変換する必要があります。この変換をA-D変換といいます。音声はパルス符号変調(Pulse Code Modulation:PCM)という方法でA-D変換を行うことが可能です。PCMは標本化→量子化→符号化の3ステップを経てデジタルなデータに変換します。
ハフ変換とは画像処理分野における画像中から直線や円などの図形要素を検出する手法のことです。
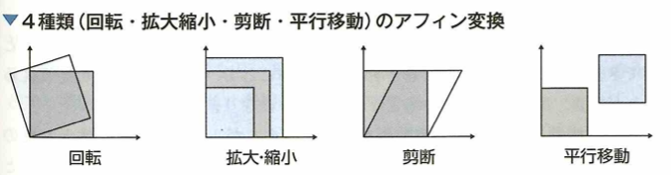
音声はパルス符号変調によってA-D変換を行います。以下の図のように、音波を一定時間毎に観測する標本化(①)、音波の強さをあらかじめ決められた値に近似する量子化(②)、量子化後の値を0と1の羅列(以下、ビット列)で表現する符号化(③)の手順でデジタルに変換します。音素・音韻についても紹介します。音韻は言語によらず人間が認知可能な音の総称を指し、音韻の最小単位を音素と呼びます。たとえば、/sa/と/si/は人間が区別可能な音であるため、異なる音韻と捉えます。/sa/を最小単位に分けると/s/と/a/という音素を取り出すことができます。
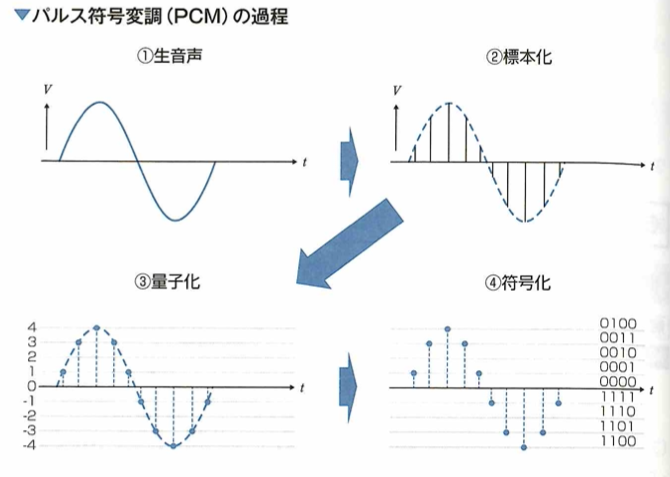
高速フーリエ変換
音声信号はさまざまな周波数や振幅の三角関数を足し合わせたものと考えることができます。音声信号にどのような周波数がどれほど含まれるか示したものを周波数スペクトルと呼び、横軸を周波数、縦軸を信号の強さとするグラフで表されることが多いです。音声信号に含まれる周波数を分析することで音声の特徴を捉えることが可能となります。周波数成分を抽出する手法として高速フーリエ変換(Fast Fourier Transform:FFT)が使用されています。高速フーリエ変換は短時間ごとに周波数解析を行う必要がありますが、高速に周波数特性を求めることができます。
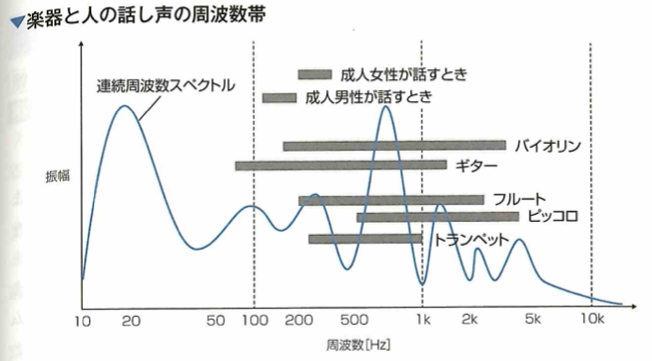
複数の音源の音が混在している音響信号からそれぞれの音を分離して認識することを音源分離といいます。「Deezer」が開発したオープンソースAIツール「Spleeter」では、周波数の特性を機械学習モデルへ入力し、音源分離を行っています。また、目的の周波数以外の音声を除外するフィルタリングを行うこともできます。そのため、音声信号に含まれる周波数の分析は、非常に重要となります。無限に続く連続的な信号にどのような周波数が、どれほどの強さで含まれているかを分析する際に、使用される手法がフーリエ変換です。しかし、コンピュータ上で扱う音声信号は、離散的なデジタルデータであり、この離散的な信号に適応できるフーリエ変換を離散フーリエ変換(DFT:Discrete Fourier Transform)といいます。演算量を減らして高速化した離散フーリエ変換が、高速フーリエ変換です。フーリエ変換の欠点の1つは、時間領域の情報が欠落することであり、高速フーリエ変換を含めフーリエ変換に時間情報の欠落を補完する機能はありません。また、高速フーリエ変換は、選択肢2にあるように、短い時間毎に信号を区切り、高速に周波数解析を行います。工作機械の異常音検知など、音声信号の周波数特性を機械学習モデルの入力とする事例は多くあります。
メル尺度
「音の大きさ」「音の高さ」「音色」は音の三要素(三区別)と呼ばれています。中でも「音色」は音波の質の違いによって生み出されるものです。同じ「音の大きさ」、同じ「音の高さ」であっても、「音色」の違いから異なる音声だと認識することができます。「音色」の違いはスペクトル包絡の違いから確認できます。スペクトル包絡とは周波数スペクトルにおける緩やかな変動のことであり、スペクトル包絡を求める手段の1つとしてメル周波数ケプストラム係数を用いて求める方法があります。メル周波数ケプストラム係数は「音色」に関する特徴量として多用されています。 スペクトル包絡を求めるといくつかの周波数で振幅がピーク値を取ります。このピークをフォルマントと呼び、フォルマントのある周波数をフォルマント周波数と呼びます。 メル周波数ケプストラム係数やフォルマント周波数は、音声認識の特徴量として使うことができます。
スペクトル包絡は、周波数スペクトルにおける緩やかな変動のことをいいます。人間の音の高さの知覚特性を考慮した尺度をメル尺度と呼び、このメル尺度に対応する周波数をメル周波数といいます。つまり、メル周波数は、人間の知覚特性に即した周波数スケールということです。また、メル周波数軸上で計算されるケプストラム係数をメル周波数ケプストラム係数といいます。このメル周波数ケプストラム係数は「音色」に関する特徴量として音声認識などに使用されています。下図は周波数スペクトルに対するスペクトル包絡を描いたものです。スペクトル包絡のピークを周波数が低い方から順に、第1フォルマント、第2フォルマント、第3フォルマントと呼びます。フォルマントのある周波数をフォルマント周波数といい、スペクトル包絡のピークを周波数が低い方から順に、第1フォルマント周波数、第2フォルマント周波数、第3フォルマント周波数と呼ばれます。フォルマント周波数は気道の共振周波数を意味するため、2つの音色について音響が同じであればフォルマント周波数も近い値を取ります。
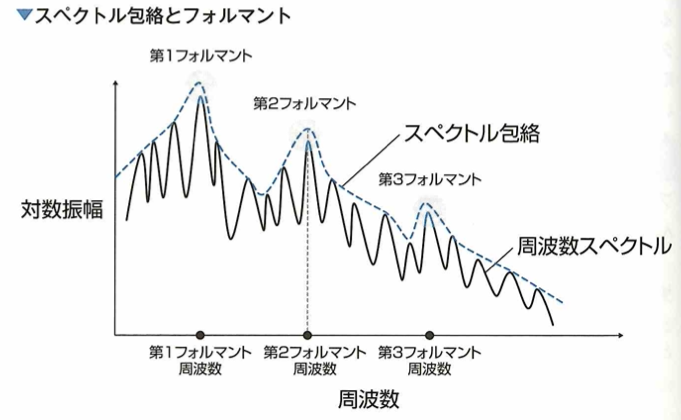
ケプストラムとは、音声認識で使われる特徴量の1つです。音声信号に対してフーリエ変換を行った後、対数をとり、もう一度フーリエ変換して作成します。メル尺度とは人間の音声知覚の特徴を考慮した尺度で、メル尺度の差が同じ時、人が感じる音高の差が同じになります。メル周波数ケプストラム係数(MFCC)とは、音声認識の領域で使われることの多い特徴量の1つです。ケプストラムにメル周波数を考慮したものです。
隠れマルコフモデル
隠れマルコフモデルについて考えます。隠れマルコフモデルは、音素ごとに学習しておくことで、さまざまな単語の認識に対応できます。
HMM(Hidden Markovo Model:隠れマルコフモデル)は音素を学習しておくことでさまざまな単語音認識に対応することができます。 また、HMMはこれまで音声認識を行う音響モデルとして用いられています。 単語を認識する際には、あらかじめ用意した単語と音素列の対応辞書により音素列に変換し、入力された音素列を基にHMMを連結することでモデル化します。 HMMの欠点はモデルのパラメータを決定する処理が複雑で計算量が多いことです。
隠れマルコフモデルとは、マルコフ過程に従って内部状態が遷移し、取得できる情報から状態遷移を推定する確率モデルです。 次頁の図1は「天気」を隠された状態、各天気における「人の行動」を取得できる情報とした隠れマルコフモデルです。「天気」の矢印に記載されている数値は「天気」が遷移する確率を表しています。たとえば、「雨」から「晴れ」に天気が遷移する確率は0.1となっています。また、「人の行動」に記載されている数値は各行動が観測される確率を表しています。これらの確率を使用して「天気」の遷移をモデル化します。一般のHMMは次頁の図のように遷移の矢印が両方向を向いており、任意の状態間の遷移が可能です。しかしHMMで音声をモデル化する場合は、HMMの状態を横一列に並べたときに左右方向の遷移がない(時間が逆戻りしない)モデルが用いられます。逆方向に遷移しないHMMモデルをleft-to-right型モデルと呼びます。
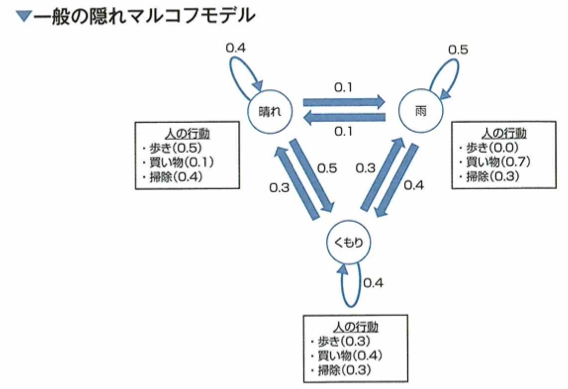
下図で示す例ではHMMを用いて音声の文字起こしをしています。「I play tennis」の音声がHMMに入力されています。音素毎に学習されたHMMが連結されているHMM(図中の連結HMM)が「I play tennis」の文字列を出力しています。音声認識でHMMを用いる場合は、メル周波数ケプストラム係数などの周波数特性に関する特徴量を入力する手法が多用されています。
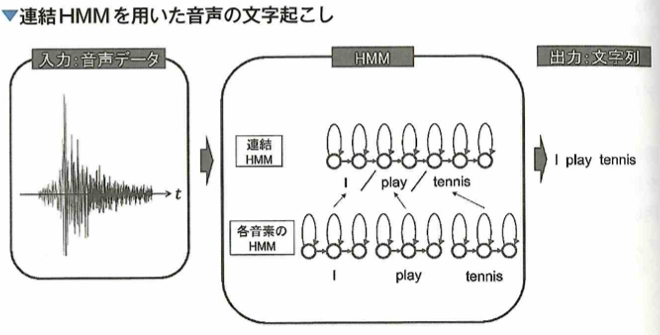
CTC(Connectionist temporally Classification)とは音声認識などで用いられる損失関数です。LSTMやRNNなどEnd-to-Endに音声認識を行う際に用いられることがあります、
WaveNet
音声合成について考えます。これはCNNなどで使われる畳み込み処理を行なっています。
WaveNetは2016年にDeepMind社によって開発されたモデルで、非常に自然な発音の音声を合成することができ、コンピューターによる音声合成・音声認識に対して大きな衝撃を与えた技術といわれています。PixelCNNというモデルをベースに作られたディープニューラルネットワークで、Dilated Causal Convolutionと呼ばれる、層が深くなるほど畳み込む層を離さず処理が内部で行われています。
強化学習
代表的な強化学種の発展アルゴリズム
強化学習との関わりが強いものを考えます。RAINBOW、Actor-Critic、REINFORCEです。
アルゴリズムの中身は理解できなくてもOKで、アルゴリズム名と対応する強化学習手法を覚えておきましょう。
RAINBOWは、Deep Q NetworkをベースにDueling Network、Double DQN、Noisy Network、Categorical DQNなどのアルゴリズムを全部搭載したアルゴリズムです。他のアルゴリズムを大きく上回る性能を発揮しました。Actor-Criticは、行動を選択するActorと、Q関数を計算することで行動を評価するCriticを、交互に学習するアルゴリズムです。発展型のアルゴリズムにA3Cがあります。REINFORCEは、一連の行動による報酬和で方策を評価して直接方策を改善する方策勾配法系のアルゴリズムです。
自然言語処理に関する語群はTransformer、BERT、Attention、生成モデルに関する語群はDCGAN、LDA、VAE、木系アルゴリズムに関する語群はDecision tree、Random forest、Gradient Boostです。
BERTはGoogleが2018年に発表した総方向Transformerを使ったモデルで、事前学習に特徴があります。MLM(Masked Language Model)はBERTにも用いられている事前学習のタスクで、文中の複数箇所の単語をマスクし、本来の単語を予測します。GSG(Gap Sentences Generation)はPEGASUSというモデルにも用いられている事前学習タスクで、複数箇所の文をマスクし、本来の文を予測します。また、マスク部分の決定はランダム以外の方法で決定します。
マルチエージェント強化学習、オフライン強化学習、残差強化学習
医療の現場において、強化学習を利用して患者の病状に合わせた最適な薬の量を求めたいですが、データを集めるために実際に患者に投薬を繰り返すことは危険であるため、報酬をサンプリングしながら学習を進めることが難しいです。そこで過去に集積されたデータのみから強化学習ができないかと考えました。このとき、最も関わりが深い手法はオフライン強化学習です。
マルチエージェント強化学習とは、複数のエージェントが存在する環境において、他のエージェントと協調しつつ共通の目的の達成を目指す強化学習手法です。 今回の問題文のシナリオは、病状から薬の量を推定するといった単一のエージェントで実現できることに注意します。残差強化学習とは、既存の制御手法による行動と、最適な行動との差分を強化学習によって求める手法です。 残差強化学習、例えば、現実世界で物体を投げるようなシナリオにおいて、まず既に課されている物理法則から行動を計算し、それを現実世界で実行した際に生じる誤差を強化学習によって補完する、といった手法になります。 シナリオによっては過去のデータのみから強化学習を行う必要があることに注意します。オンライン学習とは、過去にサンプリングされたデータのみを利用して学習を行うオフライン強化学習に対して、報酬をサンプリングしながら学習を行う通常の強化学習を言います。 シナリオによっては通常の強化学習のように報酬がサンプリングできないことに注意します。オフライン強化学習とは、エージェントを環境中で行動させつつ学習する通常の強化学習と異なり、事前に集めたデータのみから強化学習を行う手法です。 過去のデータのみから強化学習を行う際の課題として、収集されたデータに含まれている状態遷移からしか正確なフィードバックが得られないことや、データ収集に用いられた方策と学習中のモデルの持つ方策が異なるという、分布シフトと呼ばれる現象が課題となっています。このような問題により価値評価の不確実性が大きくなってしまい、誤った価値の過大評価などに繋がってしまうため、オフライン強化学習は、通常の強化学習よりも最適な方策の学習が難しいものとなっています。 しかしながら、オフライン強化学習は現実世界で実際に試行錯誤することが危険であったり、多くのコストがかかったりするような分野への強化学習の応用が期待されており、自動運転や医療領域への応用はその代表的な例となります。これらの分野では別のシステムによって経験データが蓄積されている場合があり、オフライン強化学習ではこのようなデータを有効活用して問題を改善できるのではないかと期待されています。
連続値制御、報酬設計
強化学習を利用した深層学習モデルを利用して、実際に現実の問題を解決しようとすることを考えます。このときに発生する課題について考えます。このとき次の3つ課題が例となります。まずは、シミュレータ環境で学習したモデルを現実世界で動作するロボットに搭載したが、シミュレータ環境と現実世界とのギャップにより上手く動作しなかった。次に、自動車を運転するためのハンドル操作を学習してみたが、学習によって獲得した方策が安全運転とはかけ離れたものだった、最後に、ロボットアームの制御を学習するとき、動かすアームだけでなくその移動量を出力したいため、移動量を少しずつ変えた行動の選択肢を大量に用意する必要が出てきたなどです。
順に例を追っていきます。強化学習を行う場合は、安全面やコスト面の課題によって現実世界で試行錯誤することが困難な場合があります。このような場合は、シミュレータで学習環境を作成して学習を行うことが有効なアプローチの1つですが、一方でシミュレータ環境と現実世界のギャップが大きく動作しないことがあり、強化学習における課題の1つとなっています。
方策を学習する強化学習モデルは、基本的には人が設定した報酬を最大化するように行動を最適化します。したがって、自動運転のために目的地に短い時間でたどり着いた場合に大きな報酬を与えると、多少危険な運転をしてでも早く目的地に向かおうとする方策に収束する可能性があります。逆にほんの少しでも事故の可能性がある行動をするとマイナスの報酬が与えられるような環境では、報酬を最大化するために全く動かないという方策を獲得するかもしれません。このように最適な報酬を設定することは難しく、期待する方策を獲得するための報酬成形(reward shaping、報酬設計)は強化学習の課題の1つとなっています。
強化学習モデルには、DQNのように各状態における離散的な行動の価値をそれぞれ推定し、推定結果から最も価値の高い行動を機械的に選択する(greedy方策を利用する)タイプのモデルが多く存在します。このようなモデルは基本的に連続値へ拡張しにくいという特徴があり、強化学習における課題の1つとなっています。連続値へ拡張する手法の1つとして、方策近似法と呼ばれる手法が存在します。これは方策をパラメータで表現し、最適な方策となるようにパラメータを直接学習するといったアプローチとなっています。このようなアプローチを連続値制御(continuous control)ともいいます。
ただし、強化学習は方策や状態価値に対する直接的な正解ラベルではなく、サンプリングによって得られた報酬と選択された行動を元に、方策や状態価値の評価値の精度を改善していきます。そのためオセロのように各盤面で最善手がわからなくても、勝利条件を満たした時に報酬を与えれば、各盤面における最適な方策や状態価値の正確な評価が学習できます。
状態表現学習
強化学習においてネットワーク内部で外部世界をモデル化することができると、目的の達成において有益となる場合が多いです。このように、観測データから世界をモデル化するモデルを世界モデルと呼び、世界をモデル化するために利用できる特徴を状態表現と呼びます。状態表現学習では状態表現をエージェントの観測データから自動的に獲得することが目的となります。観測データから得られる、良い状態表現に関わる性質として、状態表現を学習したモデルは関連したタスクにおいて、転移学習に効果的です。
画像などの高次元な観測データに対して、状態表現はより低次元な特徴が良いとされます。 たとえば、カメラ画像を利用してロボットアームの制御を行うことを考えると、掴みたい物体の座標値などが状態表現になり得ると考えられますが、このとき入力画像に対して座標の情報はより低次元な方が取り扱いやすくなっています。状態表現はエージェントの行動の影響を受けて動くものであること、同じ行動でも同じような影響を受けることが直感的にイメージできます。状態表現を学習するための目的関数には、このような事前知識を取り入れたさまざまなものが提案されています。関連するタスクにおいては、同じような状態表現が効果的に利用できると考えられます。したがって、関連したタスクを事前に学習するといった、転移学習の手法が適するものとなっています。世界モデルの元となる状態表現がエージェントの行動の影響を受けるものであることで、モデル化した世界を利用して、エージェントが行動の影響を学習することができるようになると考えられます。
AlphaZeroの新規性
AlphaZeroとはAlphaGo Zeroの改造バージョンとしてDeepMind社が2017年に発表したアルゴリズムです。 DeepMind社は、AlphaGo→AlphaGo Zero→AlphaZero→AlphaStarという順番で新しいアルゴリズムを発表しているが、ここでAlphaZeroを発表したときの新規性として適切なものは、囲碁に加えて、将棋やチェスも解けるようにアルゴリズムを汎化したことです。
初めて人間のプロに勝利したバージョンはAlphaGoで、2015年にファン・フィ二段(5勝0敗)、2016年にイ・セドル九段(4勝1敗)、2017年にカ・ケツ九段(3勝0敗)に勝利しました。人間の対局データを使わない自己対戦のみの学習はAlphaZeroでも行われていますが、これはAlphaGo Zeroにおいてすでに実現されていたものです。 AlphaGo Zeroは人間のプロ棋士に勝利したAlphaGoに100戦100勝しています。AlphaZeroはAlphaGo Zeroのアルゴリズムを将棋と囲碁も解けるように発展させたものです。AlphaZeroではAlphaGo Zeroで行われていた盤面の対称性を利用する回転などのデータ拡張は利用せず、さらに将棋やチェスで発生する引き分けを考慮したアルゴリズムとなっています。Blizzard Entertainmentが開発した「StarCraft II」を学習したのはAlphaStarの新規性になります。
OpneAI Five,アルファスター
OpenAI Fiveとは、Valve Corporationが開発した「Dota 2」と呼ばれるリアルタイムストラテジーゲームを解くOpenAIが開発したアルゴリズムです。Dota 2はそれぞれ5人のプレイヤーから構成される2チームで対戦します。ゲームでは各々がヒーローと呼ばれる異なるキャラクターを操作し、味方と協力しつつ相手の本拠地を破壊することが目標となります。ここで以後・チェス・将棋よりDota 2における強いアルゴリズムを作成することが難しい要因を考えます。細かなフレームごとの行動選択が長時間続くため、1試合のエピソードが長くなります。また、ゲームに関わる情報が部分的にしか観測できないので、わからない情報は推測しつつ行動を選択する必要があります。マップ上のオブジェクトやヒーローの位置といった観測される情報の空間が大きいです。
Dota 2は30fpsで動作し、1試合に約45分かかります。OpenAI Fiveは4フレーム毎に状態を観測し行動するため、1試合で約20,000回もの行動選択を行うことになります。ここで多くの個々の行動選択はゲームにほとんど影響を与えないものの、重要な場面ではわずかな行動選択がゲームに長期的な影響を与えることもあります。このような長期的な時間軸でゲームが行われることは、囲碁や将棋と比較してDota 2のタスクが難しい要因の1つとなっています。
また、将棋や囲碁は自分の手番にゲームに関するすべての情報が盤面から得られます。このようなゲームは完全情報ゲームと呼ばれます。一方でDota 2では自分の視界などから得られる部分的なゲームの情報しか得られません。Dota 2はこのような不完全な情報に基づいて相手の戦略などを推論する必要があり、これがタスクが難しくなっている要因の1つとなります。
さらに、Dota 2では1試合の中に10体のキャラクターが存在し、各々の持つスペルやアイテム、多くの建造物やNPC、マップのあらゆる場所に生えている木など、さまざまな要素が戦略に関わります。このようなゲームにおいて人間がアクセスできる要素は、OpenAI FiveではゲームのAPIを通じて得られ、その数は約2万個になります。チェスの状態は6種の駒と8×8サイズの盤面の情報で表せるのに対し、Dota2の状態はこのように膨大でかつ不完全であり、これはタスクが難しくなっている要因の1つとなります。
注意点としてDota2は各ヒーローが数十もの行動をとることができ、その行動の多くは地上の任意の地点や他のオブジェクトなどを指定して利用します。OpenAI Fiveではこのような行動空間がヒーローごとに約17000個の離散的な要素で表されており、ある状態で選択できる行動は平均1000種類存在します。これはチェスや囲碁と比較して大きいものであり、タスクが難しくなっている要因の1つです。
生成モデル
モデル圧縮
ディープラーニングはさまざまなタスクで高精度を達成できます。多層にすることで表現力の向上は可能であるが、その反面パラメータ数が増えてしまうことによる計算速度の遅延やメモリの使用量の増加などの問題があります。そこでモデル圧縮という概念が生まれました。 モデル圧縮にはいくつかの手法が提案されています。例えば、モデルのパラメータはコンピュータでは32bitといった高精細な値を持つが、これを16bitや8bitまで落とすQuantization(量子化)という手法があります。しかし、これはパラメータの情報が圧縮した分消減するため、モデル精度が悪くなることがあります。 モデル内の影響の小さい重みを削除することでパラメータ数を削減するPruning(枝刈り)という手法もあります。これは重要なパラメータのみを使うといった精度が悪くなることを防ぐ工夫がされています。 その他にも、生徒モデルと呼ばれる小さなモデルを用意し、教師モデルと呼ばれる大きなモデルの出力を真似るように学習するDistillation(蒸留)という手法もあります。これはかなり小さい生徒モデルで運用することができ、生徒モデル単体で学習するよりも生徒モデルの精度を上げることが期待できます。
量子化とは、パラメータのbit数を減らすことです。これによりパラメータのメモリ使用量は減りますがbit数を小さくするほど精度は下がる可能性があります。たとえば、0.567836725…が0.5678となり、小数の細かい部分が落ちてしまうことで最終的な推論結果に影響を及ぼしたりします。枝刈りとは、モデル内の重要度の低いノードを間引く方法です。この重要度の低いパラメータは、たとえば、ユーザーが0に近い値を閾値として決定し、その閾値内のパラメータを削除することで計算量を減らします。これによりあまり精度を下げることなく、メモリの使用量の減少と実行速度の向上が見込めます。蒸留は、生徒モデルと呼ばれる小さなモデルを学習する際に、教師モデルと呼ばれる大きなモデルの出力を真似るように学習をしていきます。これにより生徒モデルは、より単体で学習するよりも良い精度を出すようになります。蒸留に関して以下に概要を示します。 soft targetとは大きいモデルの出力のことで、hard targetとは実際のラベルの値のことです。hard targetを使って学習することは、通常の教師あり学習と変わりません。
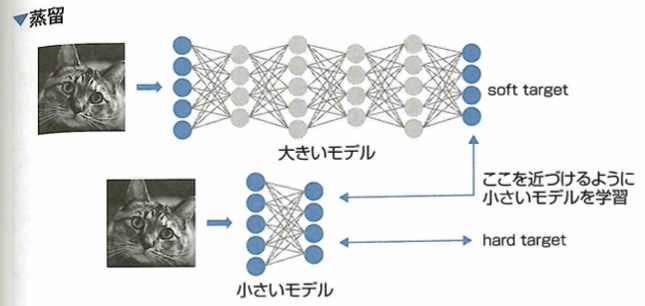
自動運転
自動運転のレベルと内容
自動運転のレベルについて考えます。レベル1はシステムが前後・左右のいずれかの車両制御を実施します。レベル2はシステムがステアリング操作、加減速のどちらもサポートします。レベル3は特定条件下においてシステムが全ての運転を実施しますが、緊急時は人が運転します。レベル4は特定条件下においてシステムが全ての運転を実施します。レベル5は常にシステムが全ての運転を実施します。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
CNNの順番はAlexNet、ResNet、DensNet
Lenetは初期の畳み込みニューラルネットワーク(CNN)です。畳み込み層とプーリング層を交互に数回重ねた後、全結合層を配置した構造で、回帰結合層(RNNに採用)は用いられていません。GoogLeNetは2014年にILSVRCで優勝したCNNでInceptionモジュールを採用しています。プーリング層もありますが、スキップ結合はありません。ResNet(2015年ILSVRC優勝)はスキップ結合がありますが、ドロップアウトは採用していません。152層などの深いネットワーク学習が可能です。その後、DenseNetもスキップ層を有しています。AlexNet(2012年ILSVRC優勝でResNet以前に開発)はCNNですがスキップ結合はありません。WideResNetはResNetを改良したCNNです。層数を減らし畳み込みチャンネル数を増やして高速で高精度なネットワークを実現しました。SENetは畳み込み層が出力した特徴マップにAttentionを適用して精度を改善したCNNです。
MobileNetは2017年にGoogleによるCNNです。モバイル端末でも使用可能で計算量やメモリ使用量が少ないです。Depthwise Separable Convollutionという畳み込み処理で、非常に少ない計算量で出力を求められます。それぞれ独立したフィルタで畳み込み計算量を削減します。区間方向の畳み込みはDepthwise Convolutionで、チャンネルごとに畳み込みがおこなわれます。チャンネル方向の畳み込みはPointwise Convolutionといい、1×1のフィルタを使用して画像のある一点がチャンネル方向にたたみ込まれます。Depthwise Separable ConvollutionEfficientNetでは通常の畳み込みと同様に1つのネットワークの中に複数回配置できます。同じパラメータ数でより広い範囲を畳み込む方法は、Dilated Convolutionを用います。EfficientNetは2019年にGoogleが発表したCNNでResNetやMobileNetを再検討し、ベンチマークにおいて従来のネットワークを大きく上まわる性能を出しました。
ニューラルネットワークの構造の自由度は高いので最適構造の模索が難しいです。最適構造そのものの学習が研究されています。これをNASと言います。ハイパーパラメータの学習を行い、適切なネットワーク構造を出力します。VAE(変分オートエンコーダ)は画像生成を行う生成ネットワークです。RandAugmentは学習時に適用するデータ拡張手法を決定する戦略です。LTSM(Long Short -Tern Memory)はゲート構造を採用したRNNです。NASの技術を用いたネットワークとして、NASNetやMnasNet(計算量を抑えるように工夫して構造探索を行うことで得られたネットワークで高精度で計量)があります。
物体検出は画像内に存在する物体位置を特定し、物体のクラスを識別するタスクです。物体の位置はバウンティングボックスで表現します。物体識別は物体のクラスを識別するタスクです。画像認識や物体認識と言います。CNNを用いて画像認識や物体認識といえば一般物体認識を指します。物体認識は特定物体認識と一般物体認識に分けられます。特定物体認識はある画像に写っている物体と全く同じ物体が写っているか否かを識別します。一般物体認識は椅子や猫といった一般的な物体のカテゴリを判別します。
セグメンテーションは画像を画素の単位で識別するタスクです。セマンティックセグメンテーションは、同じクラスに属する別個体は区別されません。インステンスセグメンテーションは同じクラスに属する別個体も区別します。つまり画像中の全ての物体の識別と、それぞれの物体を構成する画素のクラス識別を両方行います。背景についてはセマンティックセグメンテーションは識別の対象となりますが、インスタンスセグメンテーションでは背景は対象となりません。パノプテックセグメンテーションは2つを合わせたタスクです。
物体検出を行うネットワークは、2段階モデル(画像中の物体位置の特定後に物体クラスを識別)と1段階モデル(物体位置とクラス識別を同時特定)があります。2段階モデルはFPN(Feature Pyramid Network)、R-CNN(Regions with CNN features)および後継のFast R-CNN(画像全体を利用した特徴マップを利用して物体位置と候補領域をまとめて扱う)、Faster R-CNN(物体位置の候補を出力するselective searchをCNNに置き換える)があります。R-CNNはSelective Searchを用いて物体位置の候補領域を複数出力し、CNNで処理して最後にSVMでクラス分類します。1段階モデルはYOLO(you only look once)やSSD(single shot multibox detector)があります。YOLO(Selective SearchもSSDもない)は入力画像の各位置における物体領域らしさと矩形領域を同時に出力します。SSDは解像度の異なる複数の畳み込み層から出力を行い、さまざまな大きさの物体を検出できるネットワークです。
セマンティックセグメンテーションは、特徴マップを徐々に小さくして特徴を抽出するエンコーダと特徴マップを拡大して出力を行うデコーダを組み合わせた構造のネットワークです。SegNet(エンコーダ・デコーダ構造)、U-Net(エンコーダとデコーダを備えデコーダ側でエンコーダの特徴マップを加味した処理を行います)、FCN(Fully Convolutional Network)は畳み込み層とプーリング層で構成され、全結合層を持たないネットワーク、PSPNet(エコーダ・デコーダ構造の間にPyramid Pooling Moduleを追加したネットワーク)があります。Dilated Convolutionは計算量を増やすことなく広範囲の情報を集約する畳み込み処理の手法です。フィルタの感覚を設けます。これを採用しているネットワークはDeepLabがあります。これはセマンティックセグメンテーションに使用されます。インスタンスセグメンテーションにおいて、Mask R-CNNが使用されます。これはAtrous Convolutionと同じ処理を指します。
姿勢推定タスクを行うOpenPoseがあります。リアルタイムで行えます。
マルチスペクトル画像は、複数の電磁波の情報がそれぞれ別個に記録された画像です。農作物の育成状況の推定などに利用されます。
自然言語処理で用いるTransformerは強力で画像認識で行うネットワークとしてVision Transfomer(ViT)やSwin Transformerがあります。BERT(Bidirectional Encoder Representaions from Transformsers)はTransformerのエンコーダの構造を取り入れた事前学習モデルで自然言語処理に用います。GPT-2(Generate Pre-training 2)はTransformerのデコーダ構造を取り入れた事前学習モデルで自然言語処理に用います。
n-gramは隣り合うn個の単語や文字をひとまとまりとして扱う概念です。uni-gram、bi-gramはそれぞれn=1、2の場合です。One-Hot Encodingは各カテゴリに整数の連番を付与し、カテゴリの番号に対応する要素だけが1で、他の要素が0となるベクトルでカテゴリを表現する方法です。このベクトルをワンホットベクトルと言います。文章内の情報は使用しません。word2vecは単語のベクトル表現を学習する手法です。Bag-of-Words(BoW)は文章内の各単語の出現回数をもとに、文章をベクトル表現します。単語をn-gramに置き換えることも可能で、この場合はBag-of-n-gramsと言います。
TF-IDF(Term Frequency-Inverse Document Frequency)は文章をベクトル表現する手法です。BoW(Bag-of-Words)はある文章内の単語のみに着目してベクトル化を行いますが、TF-IDFはデータセット全体の単語の出現回数も考慮します。多く出現する単語に大きな重みを与えることで、単語の重要度を加味したベクトル表現を得ます。文章を意味のある最小単位に分割する手法は、形態素解析と言います。文章を複数のトピックに分類する手法は、トピックモデルに関連します。これはクラスタリング手法の一種で、1つのデータを複数のクラスタに割り当てる方法です。代表的な手法として潜在的ディリクレ配分法(LDA:Latent Dirichlet Allocation)があります。TF-IDFなどを利用してベクトル化した文章に対し、コサイン類似度などを使用して文章間の類似度を求めることができます。
トピックモデル(文書が複数の潜在的なトピックから確率的に生成されると仮定したモデル)について、word2vecは単語の分散表現を獲得できるツールです。単語の分散表現とは単語の意味に基づき単語をベクトルで表現することです。fastTextは単語の分散表現の獲得と文章の分類を行うツールです。こちらはword2vecと異なり、kindnessならkindとnessなどの単語の部分文字列も考慮します。ELMoは文章全体の文脈を考慮した単語の分散表現を獲得できるツールです。
word2vecは単語のベクトル表現(分散表現)を得る手法です。具体的なネットワーク構造に、skip-gram(ある単語が与えられた時、その周囲にどのような単語が出るかを学習)とCBOW(ある単語の前後の単語つまり文脈から目標の単語を予測することを学習)があります。BERTはTransformerのエンコーダ構造をもとにした自然言語処理向けのネットワークで、その特徴は転移学習が可能なことです。事前学習済みモデルを用いてそのまま新たなタスクの学習を行えます。自己教師あり学習の枠組みで事前学習を行います。つまり教師データが付与されていないデータに対して入力データに関連する何らかの教師情報を機械的に付与して行う学習です。事前学習はMLM(Masked Language Model)とNSP(Next Sentence Prediction)のタスクがあります。前者は入力した一部を隠し、その単語の周りの文脈から当てるタイプ、後者は入力された2つの文について、文同士が連続しているか判別するタスクです。MLP(MultiLayer Perception)は多層パーセプトロンで、NLP(Natural Language Processing)は自然言語処理です。
膨大な量の学習データを用いて大規模な自然言語処理モデルを事前学習とする研究があります。このモデルを大規模言語モデルLLM(Large Language Models)と言います。事前学習によって様々な自然言語処理タスクを解けるモデルをPLM(Pre-training Language Models)といい、特にパラメータ数の多いモデルをLLMと言います。例えばGPT-2まではPLMでGPT-3からはLLMです。PaLM(Pathways Language Model)は2022年にグーグルが発表し5400億ものパラメータがあります。GRUはRNNであり大規模言語モデルではありません。ELMoも大規模言語モデルではなく、単語の分散表現を得るネットワークです。GPT-3は2020年に人工知能研究機関のオープンAIが発表した大規模言語モデルです。
GLUE(General Language Understanding Evaluation)は複数の自然言語処理タスクにおける機械学習モデルの精度評価を行うデータセットです。自然言語処理の研究でベンチマークとして利用されます。リセットゲートと更新ゲートからなるゲート構造を備えたRNNとしてGRUがあります。GLUEは単語の分散表現を得るネットワークではありません。
音声はアナログデータです。A-D変換によりデジタル化してコンピュータで扱えるようにします。具体的な手法としてパルス符号変調があります。標本化、量子化、符号化から成ります。高速フーリエ変換(FFT)は音声データの周波数の強さ(振幅)を分析するアルゴリズムです。音声認識とは与えられた音声データまたは特徴量から適切な単語列を出力する方法です。音声データを表す谷として音韻(言語によらず人間が発生する区別可能な音の単位)と音素(言語ごとに区別される音の最小単位)を用います。音声認識の代表手法に隠れマルコフモデルがあります。音声の周波数ごとの強さを表現したものを周波数スペクトルと言います。周波数スペクトル上の音の強さの変化の様子をスペクトル包絡と言います。スペクトル包絡はメル周波数ケプストラム係数(MFCC:Mel-Frequency Cepstrum Coefficients)によって得られます。さらにスペクトル包絡のピークをフォルマントといい、フォルマントに対する周波数をフォルマント周波数と言います。メル尺度は人間が感じる音の高さの差を表現する尺度です。音声認識タスクは入力する音声データの長さと出力する音素の数が異なる場合が多いので、RNNでは扱うことが困難でしたが、CTC(Connectionist Temporal Classification)は空文字の利用や同じ音素の集約といった工夫によりその問題を解決し、RNNで音声認識タスクを扱いやすくした手法です。音声生成タスクはWaveNetというニューラルネットワークがあります。感情分析や話者識別などのタスクは分類タスクと考えニューラルネットワークを含めた様々な機械学習モデルで扱えますが、WaveNetに直接使用されることはありません。Seq2Seqは空文字の利用や音素の集約といった工夫はありません。
深層学習=強化学習+ディープラーニングで、DQNはQ学習+ディープラーニングです。DQNはCNNなどのニューラルネットワークを用いて状態処理ができ、状態が画像で与えられるデジタルゲームやロボット制御などのタスクに有効です。DQNを取り入れた深層学習手法は、ダブルDQN、ノイジーネットワーク、デュエリングネットワークなどがあります。またこれらを含む様々な手法を組み合わせたRainbowという手法もあります。SARSAは行動価値関数を最適化する強化学習手法ですが、DQNの考えは採用されていません。
深層強化学習を用いたゲームAIについて、AlphaGoはモンテカルロ木探索と深層強化学習を用いた将棋AIです。AlphaStarは対戦型ゲームであるスタークラフト2をプレイします。OpenAI Fiveは他人数型対戦ゲームであるDota2をプレイします。複数のエージェントによるよるマルチエージェント強化学習を用います。系列情報処理のためLSTMを使用しています。PPO(Proximal Policy Optimization)を利用して大規模な計算資源で55のエージェントを学習しますが、Atari2600をプレイするゲームAIではありません。Atari2600は実在するゲーム機です。57種類のゲームが強化学習の性能評価のベンチマークとして使用されています。DQNなどはAtari2600を用いて性能評価を行う場合があります。Ape-XはデュエリングネットワークやダブルDQNなどを組み合わせた手法でゲームAIとしてAtari2600のゲームをプレイできます。Agent57はDQNベースの手法でAtari2600の全てのゲームで人間のスコアを超える性能を達成しています。RainBowもAtari2600のゲームをプレイできます。
残差強化学習は、ロボット制御などにおいて、既存の制御方法と強化学習を組み合わせたものです。これらのタスクではエージェントはセンサーデータを入力として受け取ります。状態をよく表現する特徴量を入力から抽出する必要があります。この過提そのものが学習によって得られるとき、状態表現学習と言います。オフライン強化学習では、環境との相互作用を必要とせず、固定のデータセットをエージェントに与えて学習を行う手法です。マルチエージェント強化学習は、複数のエージェントを用意し、それらの相互作用を加味しながら学習を行う手法です。
ロボット制御などのタスクの際は連続値を制御する必要があります。連続値の行動をそのまま扱う場合、連続値制御問題と言います。ハンドル操作、関節の制御、ドローンの操縦制御などは連続値制御問題となります。ボタン入力などは離散的なので連続値制御問題として扱いません。
コンピュータ上のシミュレータで学習したモデルを実世界へ適用することをsim2realと言います。低コストが利点です。ただし過学習に注意です。そのためドメインランダマイゼーションを考えます。これは環境を定義する摩擦や光源などのパラメータをランダムに決めて複数のシミュレータを用意し、それらを使用して学習を行い、実世界とのギャップを軽減します。Seq2SeqはRNNを利用します。ランダムサーチは機械学習においてハイパーパラメータをランダムに探索する手法です。
ChatGPTはオープンAIが開発した対話型の文章生成AIです。大規模言語モデルの学習の他に、RLHF(Reinforcement Leaning from Human Feedback)という強化学習を用いた手法も使用されています。このフィードバックには報酬モデルが使用され、望ましい回答に対して高い報酬を付与します。DQNは人間の価値観によるフィードバックを受ける構造は備えていません。報酬形成は報酬関数の設計と学習された方策の挙動の確認を繰り返し、適切に学習が行われるように報酬関数を作り込むプロセスを指します。
生成タスクについて近年ではディープラーニングを活用した生成タスク用のネットワークが発表されています。WaveNetは主に音声生成に用いられます。Whisperは音声認識に使用され、生成タスクには用いられません。VAE(変文オートエンコーダ)は画像生成に用いられます。GPTは文章生成に用いられるネットワークです。
敵対的生成ネットワーク(GAN)はジェネレータ(生成器)とディスクリミネータ(識別器)のニューラルネットワークから形成されます。DCGAN(Deep Convolutional GAN)、CycleGAN(Pix2Pixと似ていますがペアとなる変換画像は不要)、Pix2Pix(ある画像とそれを変換した画像のペアを用いて学習を行います。これによりある風景における昼の画像を夜の画像に変換できます)があります。DCGANはGANにおけるネットワークとしてCNNを用います。拡散モデル(Diffusion Model)は元の画像に徐々にノイズを加えていき、その過程を逆向きに辿るように学習し、ノイズから画像を生成できるネットワークです。VAEはオートエンコーダを活用した生成ネットワークで画像生成に用います。Flowベース生成モデルはエンコーダ・デコーダの構造はありませんが、VAEと同様に潜在変数を用いて画像生成を行います。
NeRF(Neural Radience Fields)はニューラルネットワークを活用した画像生成技術で、与えられた画像に対して別の視点から見た画像を生成できます。画像から動画を生成できます。RLHFは人間がどのような回答を望むかネットワークにフィードバックして、望ましい回答を生成できます。LTSMはRNNの一つで画像生成には用いません。ELMoは単語の分散表現を得るネットワークで画像生成には用いません。
事前学習済みモデルを異なるタスクに転用することや学習を転移学習と言います。ファインチューニングは他のタスクにおける新たなデータを用いて事前学習済みモデルのパラメータの一部または全部を更新する手法です。特徴表現学習はディープラーニングにおいて特徴量の抽出過程そのものが学習によって獲得されることを表す用語です。転移学習の特別な場合は、Few-shot Leaningは少量の学習データで新たなタスクを解くネットワークを学習することです。さらに特殊なケースとして学習データを一つしか用いないOne-shot Leaningや学習データを全く利用しないZero-shot Leaningもあります。破壊的忘却について、学習済みモデルを転移学習によって新たなタスクに転用することにより。元のタスクに対する性能が転移学習前より低下することです。信用割り当て問題とは、ニューラルネットワークにおいて、各ニューロンが出力を改善するために、予測結果からどのようにフィードバックを受けるかということです。
大量データを用いて一度学習したモデルを利用し、ファインチューニングなどによって様々なタスクに転用する目的で学習される大規模な学習済みモデルを基盤モデルと言います。自然言語処理や画像処理など、様々な領域で学習済みの基盤モデルが公開されています。
マルチタスク学習は、1つのネットワークで複数のタスクを同時に行う学習です。物体検出で検出した領域に対して同じネットワークを使用しセグメンテーションを行うなどです。マルチモーダルタスクとは、テキストや画像など従来は別々のネットワークで扱った性質の異なるデータをまとめて扱うタスクです。VQA(Visual Question Answeing)は画像と画像に関する質問文を受け取り、内容をもとに回答を生成します。Text-to-image(入力された文章をもとに、内容を反映した画像を生成する)やImage Captioning(入力された画像に対し、その画像を説明する文章を生成する)などもあります。CLIP(Contrastive Language-iage Pretraining)は画像とその説明のペアを使用し、学習を行う画像分類用のネットワークです。画像を生成するには別のデコーダが必要で、そのままでは画像生成できません。DALL-EはText-to-imageタスクに使用されるネットワークです。Flamingoは画像や動画を入力しimage Captioningのタスクを解けます。Unfield-IOは姿勢推定や物体検出、質問応答、Text-to-image、Visual Question Answeringなどの様々なタスクを解けます。アンサンブル学習は、複数の機械学習モデルの予測結果を統合し、最終的な予測値を決定する手法です。
説明可能AIについて、ディープラーニングはブラックボックスです。AIの予測根拠を人間が理解可能な形で示すことを目指すXAIという研究が台頭しています。CNNの予測根拠を可視化する方法に、CAM(Class Activation Map)があります。これを改善してGrad-CAMもあります。LIMEはモデルの予測値に対する入力データの特徴量の重要度を推定する手法です。他にはSHAP(Shapley Additive exPlanations)はある特徴量が予測値に与える影響の度合いをShapley値という値によって決定する手法です。YOLOは物体検出で使用します。PI(Permutation importance)は検証データセットに対する予測において、個々の特徴量がどの程度重要であったかを求める手法です。
エッジAIは作業現場で使用する機器(エッジデバイス)などに直接AIを組み込む技術です。インターネットを介さずに動作できます。計算リソースが限られているので大規模なモデルを組めません。そのためモデル圧縮を使用します。MobileNetのようにモデルの構造自体を工夫して軽量化をおこなった例もあります。モデル圧縮は機械学習モデルの精度をできるだけ保ちながらモデルのサイズを小さくする技術です。知識蒸留(学習済みの大規模モデルと同じ出力を行うように小規模モデルを学習し、元の大規模モデルと同等の制度を得る)や量子化(パラメータのブット数を下げて計算量やメモリ使用量を削減する)、プルーニング(一度学習を行ったモデルのパラメータの一部を削除してパラメータ数を削減します)などがあります。マイニングはモデル圧縮の手法ではありません。
宝くじ仮説はあるサブネットワークを、元のネットワークと同じ設定で学習させるとき、どのようなネットワークにも元のネットワークと同等の精度を達成できるサブネットワークが含まれている仮説です。サブネットワークとは、ニューラルネットワークにおいて、元のネットワークから複数のパラメータを除外した小さなネットワークのことです。もし正しければ、どのようなニューラルネットワークもモデル圧縮によって軽量化できます。元のネットワークの1〜2割のサイズの当選チケットを一貫して発見したと主張している論文もあります。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
物体検出は、バウンティングボックス(矩形)を用いて物体の候補領域を切り出した後に、候補領域を画像分類器に入力してクラスを推定します。R-CNN、Fast R-CNN、Faster R-CNN、SSD、YOLOなどがあります。Selective SearchはR-CNNで物体が候補領域を見つけるのに用いる手法です。色や強度などが類似する隣接ピクセルをグルーピングします。セマンティック・セグメンテーションは物体の輪郭を画素単位で精密に切り出し、各画素にクラスを割り当てる一般物体認識の手法です。FCN、U-Netなどがあります。FCN(完全畳み込みネットワーク)はすべての層が畳み込み層から成り立つモデルです。画素ごとにラベル付けした教師データで学習させ、未知の画像に対し、画素ごとにカテゴリを予測します。 SegNetはエンコーダを用いて入力画像から特徴マップを抽出し、デコーダを用いて特徴マップと元の画像の画素位置の対応関係をマッピングします。メモリ効率がFCNより高いです。インスタンス・セグメンテーションは物体検出とセマンティック・セグメンテーションを統合した手法です。重なった物体や同一クラスに属する物体の境界・形状の判別が強みで、YOLACT、MASK R-CNNなどがあります。ニューラル画像注釈付け(NIC)はニューラルネットワークの技術を活用し、画像に写っている物体の説明を自動生成する技術です。エンコーダ部分のCNNで画像に写っている物体を検出・認識し、デコーダ部分のRNNで画像認識の結果を描写する自然言語テキストを生成します。
TF-IDFは文章中の単語の重要度を定量化する手法で、値が大きいほど単語の重要度が高いと推定されます。単語の文章内での出現頻度TFとその単語が存在する文章の割合の逆数の対数IDFの積として計算されます。コーパスは自然言語処理のために用いられる大規模なテキストデータです。形態素解析は言語解析の初期段階で行う処理です。文章を単語や文節で区切ることで「意味を持つ表現要素の最小単位」(形態素)に分割し、さらに各要素の品詞を推定します。
分かち書きは文章を最小単位で区切って記すことです。形態素解析のライブラリの例は、MeCab、JUMAN、Kuromoji、Sudachiなどです。N-gramは文章をN文字ずつに区切りながら分解する方法です。ストップワードは情報量や出現頻度が少ない単語で、一般的に解析にほぼ寄与しないもので、日本語では「は」「の」「です」英語では「a」「the」「of」などです。構文解析は主部や述部などの係り受け構造を推定するタスクです。代表的なツールはCaboCha、KNPなどです。意味解析は複数の文の間の関係性を解析するタスクです。構文解析の後で利用します。文脈解析は複数文の関係性を解析することで文章全体の意味を把握するタスクです。照応表現(代名詞など)が指す場所を推定する照応解析、因果と背景などを解明する談話構造解析が代表的手法です。Bag-of-Wordsはテキストにおける単語の出現頻度に基づいて、テキストを数値ベクトルに変換する方法です。ベクトル空間モデルは各単語をベクトル空間上の点として捉えることで、単語の意味や類似性をベクトル演算で表現します。単語同士の意味が近いほど座標点の距離が短いです。コサイン類似度はベクトル空間モデルにおいて、文書同士を比較する際に単語間の類似度を計算した指標です。トピックモデルはクラスタリングを行うことで文章中の話題(トピック)を導き出すモデルです。1つのデータを複数のクラスタへ割り当てることが可能です。潜在的ディリクレ配分法は近年のトピックモデルの主流です。ディリクレ分布を仮定して文章分類の確率値を生成します。One-Hotベクトル変換は単語を数値化するために、文章内の単語1つ1つに、(0,0,0,…,1,0,…,0)などその単語に対応するインデックスの要素だけ1にし、他の要素を0にします。ユニークな単語の数と同じ次元のベクトルになります。Sequence-to-Sequence(Seq2Seq)は入力された時系列(sequence)を新しい時系列に変換し出力するモデルです。エンコーダとデコーダの2つのRNNから構成されます。エンコーダが入力データを符号化(エンコード)することで固定長のベクトルに変換しそれをデコーダで復元(デコード)します。
Word2Vecは単語をベクトルとして表現し、単語の意味や単語間の関係をベクトル間の距離を用いて表現できるようにしたニューラルネットワークのモデルです。Doc2Vecは文章間の類似度のベクトル演算を可能にした手法です。スキップグラムはWord2Vecのアルゴリズムです。入力として中心語である単語Aを与え、単語Aの前後の一定範囲内に周辺語の単語Bが存在する確率を推定します。CBOWはWord2Vecのアルゴリズムです。周辺語を与えて中心にある単語を推測します。fastTextは2013年に提案された高速な文章分類と単語特徴の学習を特徴とする言語モデルです。訓練データに存在しないOut of Vocabulary(OOV)の推測が可能です。Bidirectional RNN(BiRNN)は過去用と未来用の2つのRNNを組み合わせて過去と未来の両方向の情報を学習や予測に活用できる双方向RNN言語モデルです。ELMoは2018年に開発された双方向RNN言語モデルを用いた言語モデルで、文脈を双方向に考慮し、文脈を反映した単語の意味を把握できることが特徴です。GNMTはGoogleが開発したニューラル機械翻訳モデルです。最初はRNNの対から構成されるSeq2Seqモデルが使われましたが、RNNは並列処理と長い系列の解析に不向きです。後に、Transformerを採用することで、データ処理の速度と長文翻訳の精度が向上しました。TransformerはRNNを用いず、すべてAttentionで構成されます。並列演算を可能にしたので高速になり、離れた位置にある単語同士の関係性を捉えやすくなりました。Transformerを取り入れたニューラル機械翻訳モデルは、Self-Attentionで構成されたエンコーダとデコーダをSource-Target Attentionで橋渡しします。Attention(注意機構)は系列データの特定の時刻の情報に重みを追加し必要な情報にだけ注意を向けて学習するニューラルネットワークです。Source-Target Attentionは入力と出力の間で単語間の関連性を算出する機能を果たすAttention機構です。Self-Attention(自己注意機構)は入力文の中、または出力文の中の単語間の関連性を定量的に評価するAttention機構です。

事前学習モデルは大規模なコーパスを用い教師なし学習を行い、汎用的な特徴を学習し終えている学習済みモデルです。ファインチューニングを通して個別のタスクに利用します。スケール則はモデルのサイズ(パラメータ数)が増加するにつれ、モデルの性能もほぼ同じ割合で向上する経験則です。BERTは2018年にGoogleが提案した事前学習モデルです。エンコーダにTransformerを活用し過去から未来と未来から過去の双方向の情報を使用できます。事前学習のためにMasked Language ModelとNext Sentence Predictionを実行します。パラメータ数は3億程度で2019年に軽量版であるALBERTやDistilBERTが公開されました。MT-DNNはMicrosoftが開発した事前学習モデルで、ロジックはBERTを参考にしています。GPTはOpenAIが開発したデコーダにTransformerを用いた事前学習モデルです。過去の単語列から次の単語を予測できるように学習を行い、自然な文章を生成可能です。初代GPTはパラメータ数が1.1億、GPT- 2は15億、GPT-3は1750億です。Few Shot Learningは文章の書き出しを与えるだけで続きの文章を自動的に生成できます。
A-D変換は、標本化(サンプリング)(連続的な音波を一定の時間間隔ごとに切り出す)と量子化(波の強さを離散的な値に近似する)と符号化(量子化された値をビット列で表現する)があります。サンプリング定理はA-D変換でデジタル化後のデータから元のアナログ信号の波形を正確に表現するには、元の信号に含まれる最も高い周波数の2倍を超えるサンプリング周波数で標本化すれば良いという定理です。音の基本属性である、強さ、高さ、音色(音質)のうち、言語を認識する上で最も大事なのは音色であり、音響モデルで使用される特徴量の1つです。音韻は言語に依存せず人の発声を区別できる音の要素です。音を区別するためにスペクトル包絡を計算します。よく使われる手法はメル周波数ケプストラム係数です。入力音声のスペクトル包絡に相当する係数列が音響モデルの特徴量となります。フォルマント周波数は、スペクトル包絡上の複数の周波数のピークで、音色の違いをもたらします。音韻が近いとフォルマント周波数も近いです。高速フーリエ変換は、複数の周波数成分の重なりである時間ごとの音声信号を、周波数スペクトルに高速に変換する手法です。隠れマルコフモデル(HMM)は音声処理のための統計学に基づく確率モデルです。辞書を使って音素列と単語をマッチングします。text-to-speech(TTS)は文章から自然な音声に変換することです。波形接続TTSとパラメトリックTTSの2種類が使われてきました。波形接続TTSは話者による短い音節の集合体から必要なものを結合して音声を合成します。声を変えること、抑揚や感情を加えることが難しいです。パラメトリックTTSは話す内容や特徴(口の動き、声の高さや抑揚など)を入力パラメータにより操作しながら音声を生成します。音を連結する必要がないので、波形接続TTSより処理が高速だが、生成された音声の自然さ(人間らしさ)が波形接続TTSに劣ります。WaveNetはDeepMind社により発表された音声処理モデルです。既存手法より自然な音声を高速に生成できます。音声系列の1つ1つの点をCNNを用いて生成します。Dilation Causal ConvolutionをCNNに取り入れることで長時間の依存関係に対応可能です。SWITCHBOARDは音声認識で使われる、音声とテキストを組み合わせたコーパスです。
GANは深層生成モデルです。ディープフェイクはGANを用いて実在しない対象物の新たな画像を合成する技術です。DCGANとはジェネレータとディスクリミネータの両方にCNNを用いたGANの強化版です。VAE(変分オートエンコーダ)はオートエンコーダを活用した深層生成モデルです。入力画像の特徴量を統計分布に変換し、そこからデータ点をランダムサンプリングし、デコーダによって復元することで新しい画像を生成します。Pix2Pixは教師あり学習を使い、変換前の画像(入力画像)と変換後の画像(目標画像)のピクセルの対応関係を直接的に学習するスタイル変換モデルです。CycleGANは教師なし学習を用いて変換前後のデータセット同士の分野や領域の関係を習得することで画像変換を実現します。CLIPはOpenAIから公開されたマルチモーダルの画像認識モデルです。DALL・E2やStable Diffusionなどの画像生成AIモデルの一部に使用されます。DALL・E2は画像認識モデルのCLIPと画像生成する拡散モデルおよび条件付ける誘導拡散を取り入れたGLIDEで構成された画像生成モデルです。幻覚とは文章生成AIが学習データにない内容を質問された時など、一番確率が高い答えを返した結果、事実は異なる内容となってしまうことです。RLHFとは人間が手を加えて作成したデータと人間によるフィードバックを使用してGPTモデルのファインチューニング(パラメータ微調整)を行い、ChatGPTの機能を仕上げる方法です。多様な質問や表現に対して、自然で正確な応答を生成可能となり、捏造や差別的な表現も減少しました。教師あり学習、報酬モデルの学習、強化学習のステップで構成されます。
深層強化学習は、ディープラーニングを強化学習に取り入れた手法です。ディープラーニングを用いて行動価値や方策を推定し、状態を表現しやすくなり学習効率が向上しました。Q学習は、ある状態の時に撮ったある行動のQ値(行動価値関数)を、Qテーブルという形で管理し、行動を実行するたびQ値を更新する手法です。DQNは深層強化学習の代表的アルゴリズムで、Q学習においてニューラルネットワークを用いた近似関数を用いて、ある状態の時にある行動をとる場合のQ値を推定し、最も良いQ値になる行動=とるべき最適行動を探索する仕組みです。
sim2realはシミュレーションを用いて方策を学習した後に、実世界の環境に適用する手法です。シミュレーションの環境に過学習することが課題です。ドメインランダマイゼーション(環境乱択化)はシミュレーション環境を実世界の環境に近づけるため、環境パラメータをランダムに変更させ、多様な環境で性能を発揮するモデルを訓練することを目指します。オフライン強化学習はシミュレーションのデーをの学習や性能評に用いず、実環境から集めた過去のデータのみを使って行う強化学習です。オンライン強化学習は実際に環境と作用しながら行う強化学習です。OpenAI Gymは強化学習の環境をシミュレーションで構築するツールです。Actor-Criticは方策に従って行動を選択するActor(行動器)を直接改善しながら、状態価値関数に応じて方策を評価・修正するCritic(評価器)を同時に学習する手法です。A3Cは複数のエージェントが同じ環境で非同期に学習することを特徴とする、Actor-Criticを用いたアルゴリズムでDeepMind社が提案しました。SARSAは今選択した行動によって、価値の高い状態に遷移できるかを評価するため、実際にエージェントを行動させて得られた状態を伝播させ、これを参考にQ値を更新し行動を再帰化する強化学習のアルゴリズムです。DQNの拡張版である、ダブルDQN、デュエリングネットワーク、ノイジーネットワークなどの特徴を組み合わせた全部載せモデルがRAINBOWです。ターゲットネットワークは現在学習中のネットワークと、過去に遡ったネットワークのTD誤差を教師データのように使います。価値の推定を安定させる効果があります。経験再生は環境を探索中に得られる経験データをリプレイバッファーに保存し、そこから適切なタイミングでランダムに抜き出して学習に利用し、学習を安定化させる効果を発揮します。AlphaGoはDeepMind社が開発したDQNベースの囲碁AIです。改良版のAlphaGo Zeroは人間の対戦データを必要とせず、完全自己対局で学習できます。囲碁に限らず将棋やチェスでも活躍します。方策ベースのアルゴリズムは数理モデルを用いて直接的に方策の良さを推定します。価値ベースのアルゴリズムは、行動価値関数を推定することで間接的に方策を最適化します。モデルベース型アルゴリズムは、環境をパラメータで明示的に表現し、パラメータを最適化することで、直接的に方策を学習します。モデルフリー型アルゴリズムは、環境パラメータを推定せず、Q学習のように方策を定めます。
Grad-CAMはCNNを対象とする大域的なモデル解釈ツールです。畳み込み層の勾配の情報を用いて予測根拠をヒートマップで可視化します。勾配が大きい画素は予測に大きく影響すると判断して重みをつけます。LIMEは局所的なモデル解釈ツールです。特定の入力データに対する予測の根拠を解釈します。
PyTorchはディープラーニング実装のためのオープンソースのフレームワークです。マルチモーダルAIは画像認識と音声認識の結果など、複数タイプの入力情報を同時に利用するAIです。
物体検出の代表的な手法は、R-CNN、Fast R-CNN、Faster R-CNN、SSD、YOLOがあります。物体が存在しそうな領域を洗い出す課題を物体候補領域検出(Region Proposal)と言います。R-CNNではSelective Searchというアルゴリズムを用いて色や強度などが類似している隣接ピクセルをグルーピングすることで、画像を複数のセグメントに分割します。

ニューラル画像注釈付け(NIC)は与えられた画像に写っている物体の説明を自然言語で生成する技術です。NICモデルは画像を入力するエンコーダの部分とキャプション文章を生成するデコーダの部分から成り立つエンコーダ・デコーダモデルの一種です。画像認識用ネットワークの全結合直下層の情報を、言語生成用ネットワークの中間層の初期値として用います。U-Net、PSPNet、FCNはセマンティック・セグメンテーションで用います。DQNは深層強化学習のアルゴリズムです。
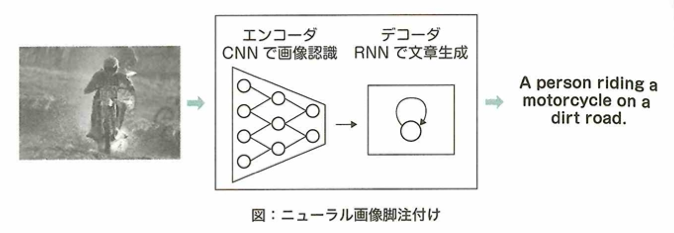
セマンティック・セグメンテーションはバウンティングボックスを用いず、物体領域を画素単位で精密に切り出し、画素ごとにクラスを予測します。複数枚重なった物体同士や同一クラスに属する別々の物体の場合は境界判別が困難です。インスタンス・セグメンテーションはセマンティック・セグメンテーションと物体検出を統合した手法です。まず物体検出を行い、物体のおおよその位置を把握し、各々の物体が存在する領域を画素単位で分割します。セマンティック・セグメンテーションが苦手とした状況でも物体の形状を正確に捉えることができます。

物体検出の元祖にあたる存在はR-CNNです。YOLOとFaster R-CNNは物体領域の切り出しと物体認識を同時に行います。Mask R-CNNはインスタンス・セグメンテーションのアルゴリズムで、Faster R-CNNの物体検出機能にセグメンテーション機能を付加したものです。セマンティック・セグメンテーションのモデルは、FCN(完全畳み込みネットワーク)です。GANのように敵対的学習ではありません。FCNはすべて畳み込み層で全結合層を有しません。
FCNとCNNの違いについて、教師データについてCNNでは画像ごとにラベルが付けられます。FCNでは画素ごとにラベル付けした教師データを与えて学習させ、未知画像が入力されたときも、画素ごとに所属するカテゴリを予測します。出力ノードの数について、CNNでは分類対象クラスの数だけ出力層のノードがあります。FCNでは画素ごとにカテゴリを付与するので、出力ノードが多数(縦画素数×横画素数×(カテゴリ数+1))です。+1は背景のことです。その他では、CNNは全結合層があるので画像サイズが統一されていることが要求されますが、FCNでは入力画像サイズは可変で構いません。
OpenPoseは入力された画像の中の人物の関節点の位置を検出することが可能な姿勢推定アルゴリズムです。一度の推定で、複数の人物を同時に2次元の画像平面上の座標として求めること可能です。GPUなどの高性能プロセッサを用いて、動画データであっても、複数の人物に対して、ほぼリアルタイムで姿勢、関節、顔や手の座標などを検出することが可能です。既存のインスタンス・セグメンテーションの手法では、被写人物の候補領域のバウンティングボックスを検出した後で、ボックス内の人の姿勢を推定するアプローチが主流でした。OpenPoseでは1枚の画像から複数人の姿勢を同時に推定するため、まず被写人物の関節点の位置を推定します。それぞれの関節に対して求めた特徴点をつなぎ合わせることで姿勢に関する情報が得られます。Cutoutはデータ拡張の手法で、画像の中のランダムな位置で長方形のマスクをすることで、擬似的に異なる画像にします。Xavierは、ニューラルネットワークの初期値を決めるアルゴリズムです。PaLMはGoogleによって開発された言語生成AIで。GPTと同様に高度な言語処理が可能で、質問応答やコード生成等のさまざまなタスクを実施できます。
MobileNetはCNNモデルをスマホなどの小型な端末に使えるように工夫が施されたモデルです。ネットワーク層が深まると性能が向上しますが、パラメータが増えるので計算量やCPUリソースが増えます。MobileNetではCNNの畳み込みをDepthwise(空間方向)とPointwise(チャネル方向)に分割し、パラメータ数を削減し、計算量を大幅に削減しています。この仕組みをDepthwise Separable Convolutionと言います。空間ピラミッドプーリングはセマンティック・セグメンテーションの手法のPSPNetの特徴です。エンコーダとデコーダの間にPyramid Pooling Moduleを挟むことで、特徴マップの大域的な情報と局所的な情報の両方を異なる解像度で拾います。空白を含んだフィルタで間隔をあけて畳み込み演算を行う(Dilation Convolution)はセマンティック・セグメンテーションモデルのDeepLabの特徴です。U-Netはセマンティック・セグメンテーションの手法です。インセプションモジュールは、CNNモデルのGoogLeNetの特徴です。サイズの異なる複数の畳み込み層を並列に適用し、最後に連結します。これに対し、EffiientNetはネットワークの深さ、幅、解像度の最適化を行い、パラメータの数を減らします。
SegNetはセマンティック・セグメンテーションに利用されるニューラルネットワークモデルです。

エンコーダでは普通のCNNと同様に、畳み込み層とプーリング層を繰り返すことで、特徴を抽出します。この時点で特徴マップは物体の大まかな位置とクラスラベルを認識できる状態です。解像度を上げるため、デコーダで出力した特徴マップの各画素の位置とラベルを元画像に対してマッピングすることで、物体の位置、輪郭を正確に捉え、物体の境界付近でも明確なセグメンテーションを行うことが可能です。SegNetの特徴として、デコーダを誘導するために、エンコーダの特徴の代わりに、最大プーリングからのインデックスを使用していることです。これによりSegNetは同じセマンティック・セグメンテーションの手法であるFCNと比べ、メモリ効率を上げています。インスタンス・セグメンテーションでは、先にバウンティングボックスを用いた物体検出を行い、画像内における物体のおおよその位置を把握した後に、各々の物体の輪郭を画素単位で切り出すセグメンテーションを行います。インスタンス・セグメンテーションの代表モデルのMask R-CNNは複数の物体が重なっている場合は、同一クラスに属する別々の物体の場合でも高精度に境界を判別できます。Dilation ConvolutionはSegNetと同じくセマンティック・セグメンテーションモデルであるDeepLabの特徴です。元の画像と特徴マップの間のピクセルのマッピングを行うのはSegNetのデコーダです。

FCNではエンコーダとデコーダのペアから構成されるのではなく、畳み込み層とプーリング層から構成されます。全結合層を持っていないので、入力画像のサイズを統一する必要はありません。一連の畳み込み層から特徴マップが抽出され、ネットワークの最後の畳み込み層で得られた特徴マップを入力画像と同じサイズまで大きく(アップサンプリング)することで、ピクセルごとのクラス確率を出力します。SegNetではエンコーダとデコーダが直列に接続されるので、特徴が伝播する際に一部のピクセルの詳細情報が消失します。そのためセグメンテーションの結果が粗くなることがあります。U-Netは SegNetと同じくエンコーダ(畳み込み層とプーリング層)とデコーダで構成されますが、ネットワークの形がU字型に折り曲がっています。U-Netではエンコーダとデコーダの間にスキップ接続を取り入れることで、効率よくエンコーダとデコーダの間で情報の伝達をさせています。スキップ接続とは、ある層の出力を次の層を飛び越えて他の層へ入力させることです。CNNモデルのResNetにも取り入れられています。U-Netはエンコーダの途中にある各層で出力させる特徴マップを、デコーダの対応する各層の特徴マップに直接飛ばすことで連結しています。エンコーダからの情報をデコーダに直接伝えることができます。スキップ接続は、医療画像分析のような精密なタスクで高いパフォーマンスを発揮します。深いネットワークの中でも詳細情報を伝達でき、物体のエッジや細かい特徴も精密に捉えられます。学習用画像の数が比較的少なくてもセグメンテーションの精度が良いです。学習および学習済みモデルによるデータ処理が高速です。デコーダ内ではエンコーダから出力された特徴マップに対してアップサンプリングを行います。U-Netはこれに逆畳み込みを使用し、学習が必要です。SegNetではUnpoolingを使用し、学習が不要であるため計算がより効率的で高速です。Unpoolingはエンコーダの最大プーリングの際に、算出された最大値の位置を保持しておき、デコーダでアップサンプリングを行う際に、その部分のみ復元し、それ以外の部分を0にします。学習するパラメータがないので、メモリや計算コストが節約されます。
LeNetは1998年にヤン・ルカンによって提案されたCNNの第一号の画像認識モデルです。畳み込み層とプーリング層を交互に重ねたネットワークです。U-Net、SegNet、PSPNetはエンコーダ・デコーダ機構を搭載したセマンティック・セグメンテーションモデルです。エンコーダとデコーダはそれぞれニューラルネットワークで、基本的にペアで動きます。エンコーダは画像から情報を抽出して特徴マップを構築し、デコーダはその特徴マップから元の画像を復元します。エンコーダでは畳み込み層とプーリング層を繰り返して、画像の次元を圧縮します。これはダウンサンプリングです。これにより入力画像から特徴マップ(ヒートマップのようなイメージ)を多数抽出します。しかし抽象的なので、デコーダで特徴マップから高解像度な画像を復元します。これをアップサンプリング、または逆畳み込みと言います。しかしこれは畳み込みの逆過程ではありません。この時、特徴マップと元画像の間の「ピクセル位置とラベル」の対応関係をマッピングしています。モデルによっては逆畳み込みと似た逆pooling(Unpooling)を用いることもあります。
PSPNet(Pyramid Scene Parsing Network)は画像検出に用いられるセマンティック・セグメンテーション手法です。エンコーダ・デコーダ構造をもつモデルで、エンコーダとデコーダの間に空間ピラミッドプーリングを追加しています。エンコーダで抽出された特徴マップに対して複数の解像度で最大プーリングを施します。これにより複数のスケールで特徴マップを生成し、画像の大域的な情報から局所的な情報まで、広範囲に渡って情報を入手できます。続いてデコーダで特徴マップに対してアップサンプリングを行い、シーン分割の結果を出力します。
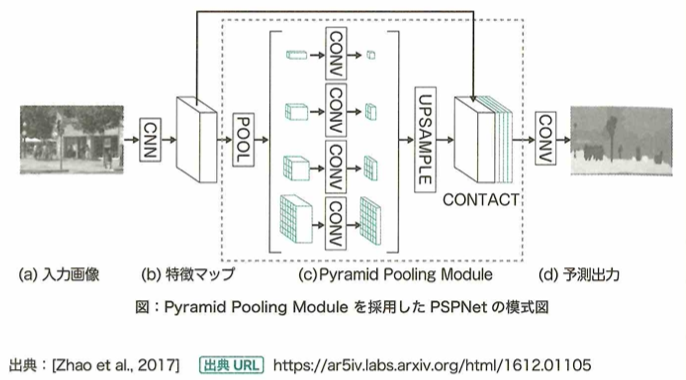
PSPNetには複雑なシーン画像においても高い解像度で複数物体の分離と検出を行う高い能力があります。PASCAL VOC 2012やCityscapesといったシーン分割の代表的なデータセットで一位を勝ち取っています。Grad-CAMはCNNなどの画像認識モデルによる予測の根拠を解釈する大域的なモデル解釈手法です。N-gramは自然言語処理のために、日本語のような単語がスペースで区切られていない言語をN単語ずつ区切りながら分解する方法です。Selective Searchは物体検出タスクにおいて、物体候補領域検出に使用されるアルゴリズムです。物体が存在しそうな領域を見つけるために、色や強度などが類似している隣接ピクセルをグルーピングすることで、複数のセグメントに分割します。これにより得られた領域のそれぞれにおいて、CNNで特徴を抽出しSVMでクラス分類を行います。シーン画像の画像分類を行う際はシーン認識とシーン分割を行います。高精度を出せるのはPSPNetとDeepLabです。

DeepLabはGoogleによって開発されたセマンティック・セグメンテーションモデルです。エンコーダにはResNetの特徴抽出層を使用しています、畳み込み層にはDilation Convolution(別名:Atrous Convolution)を導入しています。プーリングを行わず、比較的長距離(広範囲)の計算を効率的に実行できます。
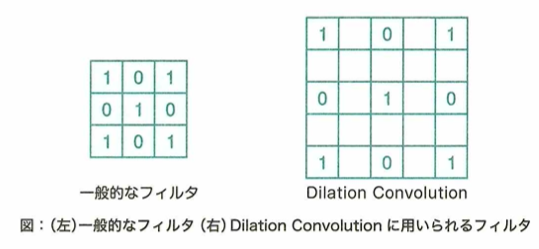
DeepLabでは、Dilation Convolutionの畳み込み層のみならず、空間ピラミッドプーリングも取り入れています。2Dピラミッド拡張プーリングです。DeepLab v3+では分割可能畳み込みも採用し、軽量化に寄与しています。近年の物体認識では、高精度なセマンティック・セグメンテーションとともに、計算の速度やリアルタイム性が重視されています。DeepLab v3+と並び、PSPNetがセマンティック・セグメンテーション用の標準的モデルとして普及しています。Compound Coefficientは EfficientNetで使用されるスケーリングの法則に関係します。幅、深さ、解像度など、それぞれを何倍増やすかは複合係数という係数を導入してCNNのスケールを最適化します。CECは長期依存を学習できるようにしたRNNの拡張モデルのLSTMにおける過去のデータを保存するユニットです。Auxiliary Classifierはネットワークの途中にあるクラス分類器であり、そこで評価した損失をネットワークにフィードバックする役割を持ちます。GoogLeNetやGANなどで導入されます。GoogLeNetではネットワークが途中で分岐しており、終端だけでなく各サブネットワークにクラス分類器を設定します。ここで求められる損失(Auxiliary Loss)をネットワークにフィードバックします。深いネットワークでも、より効率よく全ての層に勾配の情報を伝播させることができ、勾配消失問題の緩和につながります。複数のクラス分類器を組み合わせているのでアンサンブル学習と似た効果があり、汎化性能を高めることが期待できます。
TFはTerm frequencyつまり、単語の出現頻度、IDFはInverse Document Frequencyつまり、逆文書頻度です。つまり、TF-IDFは、「ある文章」の中の「特定の単語」の重要度を定量化するための尺度です。TF-IDFはTFがある文章の中の特定の単語の出現頻度で、文書中の特定の単語の出現回数を全単語数で割ったもので、IDFは全文章中で特定の単語を含む文章がどれくらい低い頻度で存在するか(文章間のその単語の珍しさ)で、全文書数をその単語が出現する文書の数で割った値の対数をとったものです。普段コーパス全体で滅多に出ない珍しい単語が、ある文章に出現した場合、その単語はある文章の特徴をうまく代表しているため重要度が高いという考え方に基づいています。このため、特定の点語について、その単語が出現する文章ごとにTF-IDFが計算され、文章ごとに異なる値を取ります。IDFはあらゆる文章によく出現する珍しくない単語ほど小さい値を取ります。「が」「と」「です」などです。TF-IDFの値が大きいほど該当する単語の重要度が高いです。
テキスト解析の初期段階では形態素解析が行われます。形態素解析=分かち書き+品詞推定です。分かち書きとは、文章を最小単位で区切って記す部分です。その後、品詞推定を行います。英語やフランス語などの欧米の言語は、文章の中で単語が既に空白で区切られています。そのため、空白の箇所で区切ってから分かち書きを行います。一方で中国語や日本語は、空白で単語を区切らないので、分かち書きの考えが異なります。品詞を考慮しながら形態素という最小単位に分かち書きを行います。


JUMANは京大が開発した形態素解析器です。他にはMeCab、Kuromoji、Sudachiがあります。CaboCha、KNPは日本語の構文解析、つまり係り受けなどの構文的依存関係を解析するツールです。SWITCHBOARDは音声認識の分野で、音声データとテキストデータを組み合わせた音声コーパスです。500人以上の話者と300万以上の単語を収録しています。自然言語処理において、日本語のような単語同士がスペースで区切られていない文章を単語などの最小単位に分解するには、形態素解析とN-gramの2つの手法があります。N-gramは統計的なアプローチが採用され、文章をN文字ずつ区切りながら単語分解する方法です。Nが1、2、3の時、それぞれユニグラム、バイグラム、トリグラムと言います。
構文解析の役割は形態素解析を行なった後に、形態素間の関係を解析し、例えば手部や述部などの係り受け構造を推定することです。
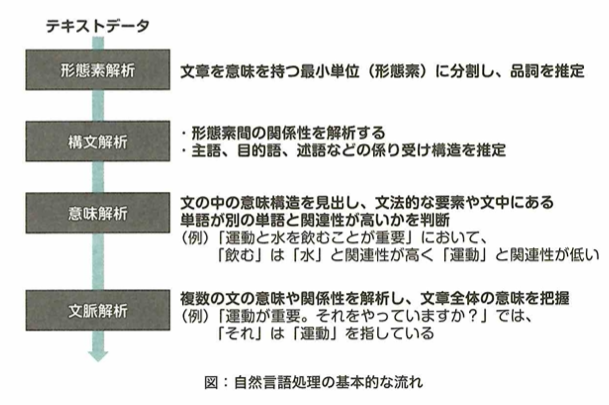
意味解析は複数の文の間の関係性を捉えます。その後に文脈解析があります。ストップワード(は、です、a、theなど)はデータクレンジングの一種です。
トピックモデルは、クラスタリングを行い、文章中の話題を導き出すモデルです。同じクラスタリングの手法であるK-Meansとの違いは、K-Meansは各データを1つのクラスタに属させるのに対し、トピックモデルは1つのデータを複数のクラスタに割り当てることが可能です。文章内の各単語はあるトピックを持つ確率分布に従って出現すると仮定した上で分類を行います。トピックモデルの1つであるLDA(潜在ディリクレ配分法)などがあります。
BoW(Bag-of-Wors)は一般的に形態素解析とデータクレンジングの後に、文章における単語の出現頻度を考慮しながら、テキストデータを数値ベクトルに変換するために使われる手法です。コサイン類似度はベクトル空間モデルにおいて、文書同士を比べるために用いられる類似度の指標です。BoWによるベクトル表現がなされた後に適用します。
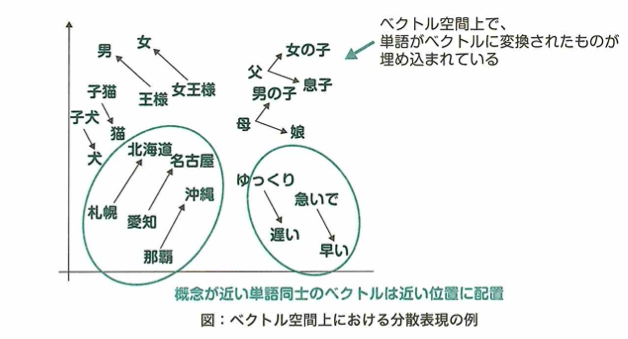
One-Hotベクトル変換は単語を数値化するためのシンプルな方法です。文章の単語の1つ1つにある1つの成分が1で他が0となるベクトルを割り当てます。ユニークな単語の数と同じ次元のベクトルを用意し、各単語に対し、IDに対応するインデックスのみに1を、それ以外のインデックスに全て0を割り当てます。このベクトル変換により、1つの単語と1つのベクトルが1対1の関係になり、形式的には機械で処理できます。しかし、単なるダミー数値で、同一単語かどうかの判定はできても、単語の意味を表現できないのが課題です。ユニークな単語の数と同じ次元をとるので、単語ベクトルの次元数は膨大で、1つのベクトルに0がたくさん並ぶスパース(疎)な数値表現になります。
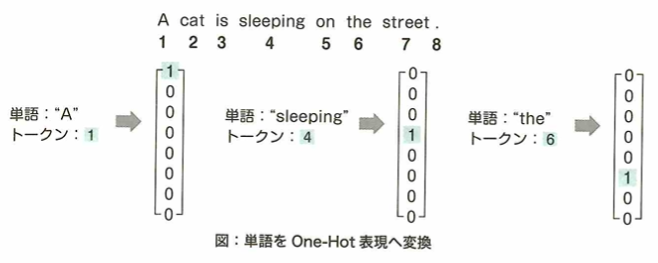
自然言語処理では、入力と出力の文章は単語の系列です。Seq2Seqは入力された時系列(sequence)を新しい時系列に変換し出力するモデルです。2つのRNNを直列に繋いだエンコーダ・デコーダモデルです。Word2Vecは単語をその意味を反映した数値ベクトルを変換するために用いられるニューラルネットワークです。
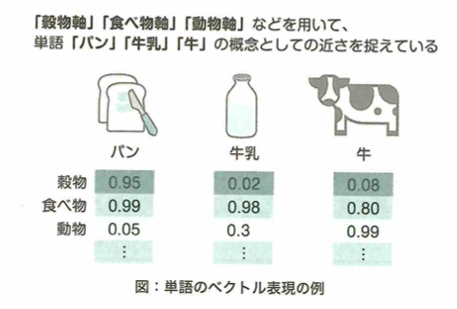
Doc2Vecは文章間の類似度のベクトルを計算する手法です。BiRNNは過去用と未来用の2つのRNNを組み合わせることで、未来から過去の方向にも学習できる双方向RNN言語モデルです。過去と未来の両方の情報を学習や予測に活用できるので、時系列の途中に歯抜けがある場合などに有利となります。
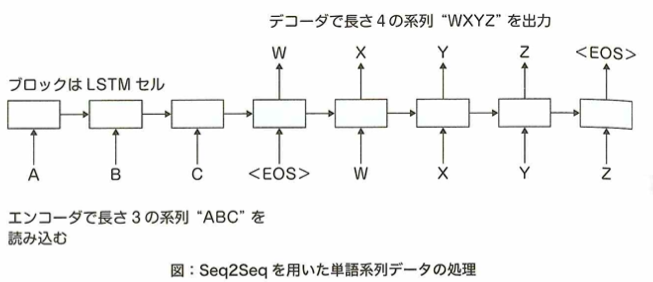
Seq2Seqモデルは入力時系列を新しい時系列に変換して出力します。RNNの特徴には、可変長の入出力に対応できることがありますが、並列処理ができず、内部セルを通過するデータを順番に処理します。CTCはRNNを用いた系列データ(自然言語や音声)処理において、空白の要素を挿入して処理することによって、入力と出力の系列の長さを形式的に一致させる技術です。RNNにおいて、任意の入力系列と長さの異なる出力系列を扱えるようになります。
ニューラル画像注釈付け(NIC)は画像に写っている物体を説明する自然言語を生成する技術です。エンコーダには画像を認識するネットワーク(CNN)でデコーダには文章を生成するネットワークがあり同時に学習させます。RNNとTransformerは両方とも文章(単語の系列)を生成できるので、NICモデルの文章を生成するデコーダ部分に活用できます。Transformerそれ自体はエンコーダ・デコーダモデルです。RNNはエンコーダデコーダモデルに用いられる構成部品です。RNNの対を成したSeq2SeqモデルはTransformerが普及する前は、言語モデルの主流でした。位置エンコーディングを用いて単語の序列を計算するのはRNNでなくTransformerです。これとRNNは共に、系列の要素の順序を考慮でき、過去の時刻の値を参考にしながら次の値を予測します。しかしその仕組みは両者で異なります。RNNはそのセルの中で単語の順番に関する情報を直接的に保持しています。そのため位置エンコーディングを用いません。TransformerはエンコーダとデコーダにSelf-Attentionを用いますが、Attentionは語順に関する情報を直接的に計算できません。そのためTransformerでは単語の序列に関する情報を入力に加味するため、位置エンコーディングを使用します。各単語が系列中の何番目の位置にあるかを一位に区別するための位置情報をベクトルとして表現し、これらの位置ベクトルを単語の埋め込みベクトルに追加します。位置ベクトルへの変換には符号化関数(三角関数など)を用います。また、単語の絶対的な位置情報だけでなく。単語間の相対的な位置関係を埋め込むこともあります。RNNは並列計算ができませんが、TransformerはすべてAttentionで構成されており、Attentionは並列計算が可能なので、学習と予測が高速になります。しかし、語順に関する情報を直接考慮できない弱点があります。そのため位置エンコーディングを用いてTransformerは単語の位置と意味を両方用いて文脈を解釈できるようになり、より高い精度の結果を生成します。
Transformerを画像認識用に応用したのが、Vision Transformerです。CNNを用いず高精度な画像認識ができます。Transofrormerは自然言語処理で使う際は単語ベクトルを入力しますが、Vision Transformerは通常のTransformerのエンコーダ部分を使用します。入力する画像をパッチに分割し、各パッチを単語ベクトルのように扱います。各パッチがベクトル状態にFlatten(一次元の配列に変換)されてからエンコーダへ入力されます。GAP(Global Average Pooling)はCNNモデルにおいて、特徴マップの全ピクセルにわたる平均を計算し、特徴マップを一つのスカラー値まで圧縮する処理です。そのためTransformerが画像データを入力として受け入れるための処理ではありません。GAPは全結合層の代わりに出力層に近い部分で使用し、パラメータ数を減らすことで過学習のリスクを減らします。GAPによる特徴量の平均化の処理により、空間情報を効率的に抽象化し、モデルが物体の位置の変化によりよりロバストになる効果もあります。TransformerのエンコーダはSelf-Attentionで構成されます。Attentionは位置情報を計算できません。Transformerでは系列の中の各要素(この場合はパッチ)の位置関係を解析するため、位置エンコーディングを別途計算する必要があります。CNNの特徴は、カーネルを用いて入力画像に対する畳み込み演算を行うことです。
Transformerで使用されるAttentionにより離れた位置にある単語同士の関係性が捉えやすくなったので、翻訳の精度向上が実現しました。ニューラル機械翻訳モデルは、2つのRNNで構成されたSeq2Seqモデル→エンコーダのRNNとデコーダのRNNをAttentionで橋渡ししたバージョンが採用され→Transformerとなりました。この橋渡しを担うAttention機構は、特にSource-Target Attentionと言われ、入力系列(Source)と出力系列(Target)の間で単語間の関連性を算出します。つまり、翻訳前の文と翻訳ごのぶんの間の照応関係を表す重みを計算します。これに対して、入力系列内または出力系列内のAttentionは、Self-Attentionと言います。TransformerではSelf-Attentionで構成されたエンコーダとデコーダをSource-Target Attentionで橋渡しします。エンコーダとデコーダには、それぞれ異なる目的のSelf-Attentionのレイヤーがあります。そしてデコーダには、Source-Target Attentionがあります。
スキップグラムはある単語が与えられた時に、その周囲に現れる単語を予測するモデルです。入力として中心語Aを与え、単語Aの前後の一定範囲(ウィンドウ)内に周辺語である単語Bが存在するかどうかを推定します。

これに対して、CBOWは周辺の単語を与えて中心にある単語を予測するモデルです。

これら2種類の予測を、精度良くできるように各単語の分散表現ベクトルの学習を行うのが、Word2Vecです。これはNew York TimesやJapan Airlinesのような複合句にも対応可能なことです。変換後の数値ベクトルの足し算、引き算を通して単語の意味の近さを定量的に表現できます。例えば、王様ー男性+女性=女王です。ニューラルネットワークの隠れ層が獲得する特徴表現が、単語の意味表現に対応するように学習します。
LSTMは並列計算に向きません。
2018年に提案されたBERTのパラメータ数は3億程度で、その後パラメータ数を減らした軽量版が出されました。2020年に発表されたGPT-3のパラメータ数は1750億になります。自然言語処理における事前学習モデルは大規模なテキストデータ(コーパス)を用いてあらかじめ汎用的な特徴を学習し終えている学習済みモデルです。事前学習モデルを活用して、コストなどを削減できます。事前学習モデルを新しいタスクに適用するために、手元にある比較的少量のデータを用いてファインチューニングを行います。GPT-3の学習データとして、電子化された書籍やウィキペディアなどから収集されたコーパスが使われました。
GPT-3は完全オープンソースとして提供されておりません。AI倫理やセキュリティの懸念からです。OpenAIからAPIの利用を申請し、承認を得た上でAPIを介してのみ使用できます。GPT系列の事前学習モデルは、過去の単語列から次の単語を予測するように学習を行います。文章の内容や背景を学習する上で高い性能を発揮し、文章生成、評判分析、質問応答など、幅広い言語タスクに対応します。GPTは初代〜3代までに、パラメータ数は1.1億、15億、1750億となりました。GPT-3は巨大なコーパスを用いて教師なし学習を行い、その学習済みモデルは、ある単語の次にくる単語を高い精度で予測できます。これにより、あたかも人間が書いたような自然な文章を自動で生成できます。GPT-3が単語の関係性を学習できても、人間社会の常識を認識できません。そのため生成された文章の文法が正しくても、よく見ると不自然な部分があるケースがあります。また物理現象に関する推論が苦手と言われています。氷を触ると冷たく感じますか?という質問には答えにくいです。

A-D変換は標本化→量子化→符号化で行います。次の図で長方形に区分けするのが、横が標本化で、縦が量子化です。
音は、強さ、高さ、音色の3つの基本属性を持ち、その中で音色が大事です。音響モデルで使用される有効な特徴量の1つとなります。音色の違いをもたらすのは、音声スペクトル上の穏やかな変動(共振特性)であるスペクトル包絡に観察される複数のピークです。これらのピークの位置の周波数をフォルマント周波数と言います。言語に依存せず、人の発声を区別できる音の要素が音韻です。音韻が近いとフォルマント周波数も近い値です。
SegNetはセマンティック・セグメンテーションのモデルです。エンコーダを用いて入力画像から特徴マップを抽出し、デコーダを用いて特徴マップと元の画像の画素位置の対応関係をマッピングします。同じセマンティック・セグメンテーションモデルのFCNよりメモリ効率が高いです。WaveNetはDeepMind社より発表された既存手法より人間に近い自然な音声を実時間以上に高速に生成できる音声生成モデルです。隠れマルコフモデルはディープラーニングが普及するまで、長く使用された音響モデルです。事前に用意された辞書を用いて音素列がどの単語に対応するかを判断し、パターンマッチングを行います。CTC(コネクショニスト時系列分析)はRNNやLSTMなどの出力で、入力と出力の系列長が違うときに、空白文字を用いて、うまく処理できるようにするアルゴリズムです。
ナイキスト周波数は、信号を標本化する際の、サンプリング周波数の1/2周波数です。つまり元の音声信号を十分に綺麗に再現できる周波数の上限です。ナイキスト周波数よりも高い周波数の信号を標本化すると、折り返し(エイリアシング)が生じ、再生時に元の信号として忠実には再現されなくなります。音韻とは発せられた音声を区別する音の要素です。ピザとピッツァは音韻においては同じです。音素とは意味の違いに関わる最小の音声的な単位です。音素は音響的な役割より意味の役割を果たし、音韻は音素より広くて抽象化された概念です。
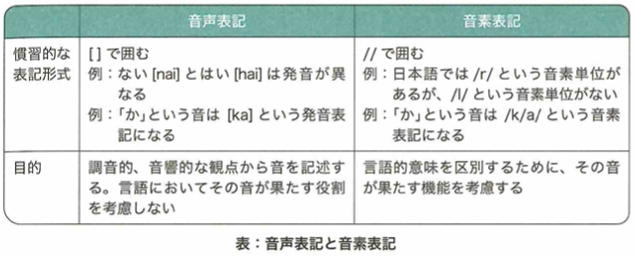
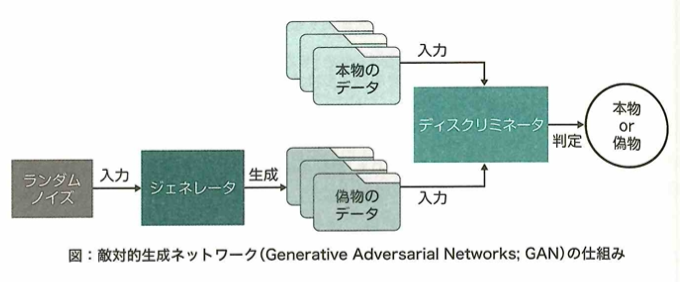
Pix2Pixは教師あり学習を行い、変換前の画像(入力画像)と変換後の画像(目標画像)のピクセルの対応関係を直接的に学習します。学習済みモデルは、新たな画像が入力された際に、学習した関係性に基づいてスタイル変更後の画像を生成します。この時も、画像のピクセルに直接作用して画像を変換します。変換前と変換後で直接対応する、輪郭や位置が揃った画像のペアを用意する必要があります。さらに、画像の中を各物体をセグメンテーションした画像も学習に必要です。例えば、公園の写真におけるベンチや植物などを個々に切り出した写真です。CycleGANは教師なし学習を用います。Pix2Pixより柔軟性の高いスタイル変換方法です。変換前後のデータセット同士の分野や領域の関係を教師なし学習で習得することで画像変換を実現します。両方向の画像変換のために2つの生成ネットワークを同時に訓練します。StyleGANは高解像度の画像生成を可能にするProgressive Growingというアプローチを導入しています。学習過程の前段階では低解像度の学習から開始し、徐々に高い解像度に対応した層をネットワークに加えながら学習を進めていくことで、最終的に高解像度の画像の生成を可能にします。CNNによる畳み込み処理の後に、画像のスタイルに関する情報を各層に取り込んで、独特なスタイル調整を行います。各層ではAdalNという手法で、スタイルに関するベクトルを正規化しています。加えて、StyleGANでは細部に関わるランダムノイズも各層に取り入れています。
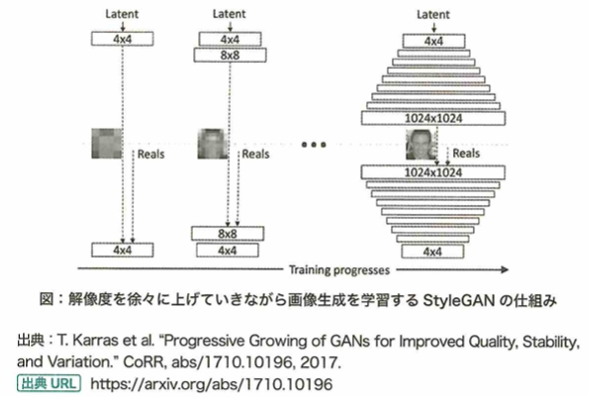
CLIPは、2021年にOpenAIから公開されたマルチモーダルの画像認識モデルです。DALL・E2やStable Diffusionなどの画像生成AIモデルの一部に利用されます。ウェブ上から収集された4億ほどの画像とキャプションのペアを用いて事前学習を行います。既存のキャプション(またはタイトル)がついている画像セットで、インターネット上から画像とその説明がペアになっているデータを集めてきたデータセットのルールです。学習済みのCLIPモデルを、Zero-shot(追加データなし)で画像分類に使用可能です。しかし、事前学習の方は依然として大量のデータを必要とします。CLIPはTransformerを利用したテキストエンコーダと画像エンコーダから構成されます。アノテーション(正解データ付与)が不要のため、従来の画像認識タスクに比べ準備コストは低いです。ImageNetでは、2万以上のカテゴリごとに正解ラベルを付与することがかかります。
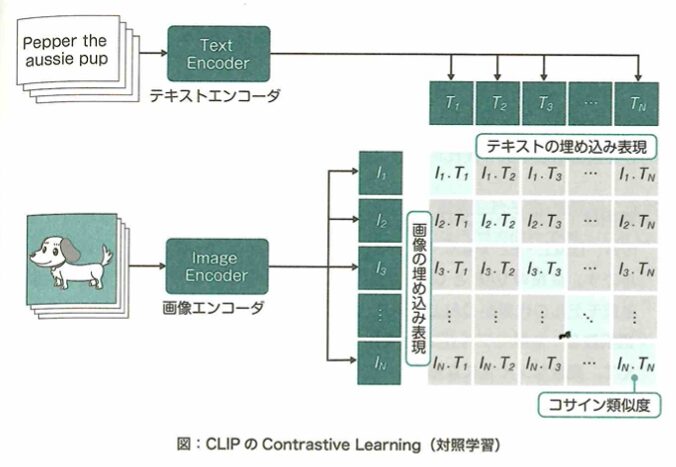
分類したい画像を画像エンコーダに入力し、画像とテキストのコサイン類似度を計算し、これが一番高い値を取るクラスを選択し、画像分類を行います。コサイン類似度が正しいペアに関して大きくなり、間違ったペアについて小さくなるように、テキストとそれに対応する画像を近づける学習をします。
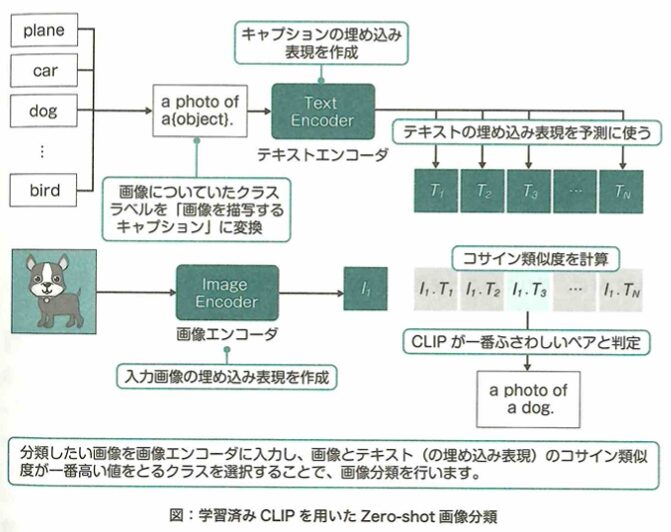
学習済みCLIPは、Zero-shotで分類器として使用できます。幅広い被写体に対してファインチューニング(追加学習)なしに画像とテキストの類似度を測る事で正しく画像を分類できます。
DALL・E2は画像認識モデルのCLIPと画像生成する拡散モデル及び条件付ける誘導拡散を取り入れたGLIDEで構成されます。オートエンコーダ(エンコーダとデコーダ)を用いて画像生成するのは、DALL・E2でなくVAEという画像生成モデルです。従来のVAEとGANとは別のアプローチで拡散モデルを用いた画像生成モデルの代表がDALL・E2です。拡散モデルでは、元データに徐々にノイズを加えて、完全なノイズになるまでのプロセスを逆転させ、ノイズを徐々に除去することによりデータを復元することを学習します。このプロセスを用いて新しいデータを生成します。この拡散モデルを特定のテキスト(クラスラベルなど)で条件付けながら本物らしい画像を生成する誘導拡散の手法も導入されています。DALL・E2に利用されるのは、このように拡散モデルを改良したGLIDEです。画像生成用プロンプト(テキスト)と画像の関係性を捉えるのにDALL・E2で用いるのはCLIPです。
プロンプトエンジニアリングは目的別に最適な命令文を設計し、生成AIからの応答の形式と品質を制御するための研修・技術です。生成AIモデルのパラメータを調整することとは異なります。現在の大規模言語モデルはよく学習されていて、汎用性が高いので、単純な命令だけでも良い出力が得られることも多いです。このような回答例を一切含めず、命令(質問)だけのプロンプトを、Zero-shot promptingと言います。複雑なタスクを指示したい場合に、Zero-shotでは意図する出力が得られないことがあります。その場合は少し高度なテクニックを組み合わせると有効な出力が得られる確率が上がります。代表的なのは、1つ以上の正解例を与えた上で命令するFew-shot pronptingです。事前学習した文章生成AIに有効です。このような方向性で答えてほしいという指針(正解例)を//の後の単語で与えています。

文章生成AIは質問の答えがわからない場合などは、一番確率が高い答えを返し、事実と異なる内容となってしまったことを、幻覚と言います。すなわち、不正確な内容を出力すると考えます。
webから収集された膨大な量のテキストデータを用いて、教師なし学習を行うのは、ChatGPTでなく、その基盤モデルであるGPTです。具体的にはGPT-3.5、GPT-4です。GPTは大量のテキストデータを用いて教師なし学習を行い、自然言語の一般的な知識を学習した大規模然言語モデルです。この過程を事前学習と言います。これらを無差別に学習しており、対話型AIに特化した学習は行っておりません。そのため事前学習を終えたGPTは適切な出力ができるとは限りません。そのため、事前学習の後に、人間が手を加えて作成したデータと人間によるフィードバックを使用してGPTのファインチューニング(パラメータの微調整)を行います。これにより多様な質問や表現に対し、自然で適切な応答を生成でき、差別的な表現の発生確率を低減させます。チューニング終盤でGPTの出力を最適化するために強化学習が使用されます。すなわち人間の価値観により訓練結果が左右されます。
GPTからChatGPTへと進化するためのファインチューニングについて、ChatGPTはGPTと同じく、単語を逐次的に予測し文章を生成します。なるべく適切な回答を出せるように人間の手を借りて細かい調整を行います。プロセス全体に人間が関わっており、強化学習も用いるので、RLHFと言います。その結果、自然で正確な応答を生成可能となり、捏造や差別的な表現を生成する可能性も減ります。RLHFは教師あり学習、報酬モデルの学習、強化学習の3ステップで行われます。強化学習は繰り返し行います。GPTが質問への回答を出力→報酬モデルが出力を評価→評価をさらにGPTにフィードバックの流れを繰り返すのです。RLHFの目的は最新データで学習する事ではありません。幻覚はRLHFで解決できません。これはChatGPTの仕組みに由来する現象です。RLHFの3ステップについて詳しく考えます。教師あり学習では、人間(ラベラー)が作成したプロンプトとそれに対する正しい回答セットを学習データとして、GPTに対して教師あり学習を行います。事前学習で学習できていないことをここで習得します。報酬モデルの学習では。報酬モデルの学習を人間のフィードバックを用いて行います。人間がGPTに対して質問を行い、複数個の回答を出力させます。人間が適切であると思われ得る順に並べ替えます。その順位をデータセットとして報酬モデルに学習させ、報酬モデルが様々な質問に対し、GPTが適切に回答できたかを判断できるようになります。報酬関数を使った強化学習では、GPTの出力を最適化するための方策を最適化します。GPTに質問を与えて回答を出力させ、その出力を報酬モデルが評価、この評価をさらにGPTにフィードバックします。この繰り返しにより、GPTはユーザの期待になるべく近い文章を生成できるようになります。
深層強化学習のアルゴリズムであるノイジーネットワークは広範囲の行動の探索を実現するため、ネットワークの重みにノイズ(外乱)を与えそれも含め学習します。ε-greedy法は本来のDQNでは常にその時点での報酬が一番高い行動を選択します(greedy法)ですが最初に価値が高くなる行動を取り続けると、別の行動を取る可能性が低くなっていきます。ε-greedy法は行動選択の範囲を広げるためにεの確率でランダムに行動するようにしています。しかし探索率εの調整が難しく、パフォーマンスに影響を及ぼしやすい上、新しい行動につなげる効果が十分に出ません。この問題点に注目してノイジーネットワークは別の手段を用いて確率的な行動選択を実現します。ε-greedy法のように行動選択に直接摂動を与えるのでなく、ネットワークそのものにノイズを加えてそれも含め学習します。これにより間接的な行動選択を確率的にしました。行動や状態をランダムサンプリングしてネットワークの重みを更新するのは、DQNの改良版のExperience replayで、学習を安定化する効果があります。
従来のDQNでは同じネットワークを用いて、行動の選択とQ値(価値)の評価を行います。しかし行動aと状態sによるq値であるQ(s,a)の推定値が過大評価される傾向があります。これに対処するためダブルDQNでは、次の行動を決めるネットワークとQ関数の更新を行うネットワークに分けて使用します。従来のQ学習では、1つの時間ステップを進めるごとに価値関数を更新します。そのため取り合うステップの結果を考えると、相関が高くなります。時間の相関が高いと学習が不安定になります。この問題を解決すべくExperience Replayは、時間的な順序でなく、状態行動と報酬の組み合わせ中からランダムに選んでネットワークに入力して重みを更新することで、学習の安定化を図りました。DQNでは、状態によってはどんな行動を取っても価値が変わっらないケースがあります。ゲームでどんな手を打っても必ず勝つなどです。デュエリングネットワークでは、DQNの学習を効率的に進めるために、ネットワークを途中で状態のみから計算できる部分と、行動のみから計算できる部分に分岐させます。
シミュレーション上で学習したモデルを実環境で使用した際に、性能が出ない時があります。モデルがシミュレーション環境に過学習しているのです。現実でデータを収集しようとするときに、例えばロボット操作などでは危険が伴う時があります。その際にシミューレージョン上で収集したデータを学習データや検証データとして使います。しかし現実世界とのギャップが問題となります。ドメインランダマイゼーション(環境乱択化)は、シミュレーションを現実世界の環境に近づけます。環境パラメータをランダムに変更させた(ばらつきを与えた)パターンを大量に用意し、多様な環境の全てにおいて性能を発揮できるモデルを学習します。モンテカルロ・シミュレーションは、システム的に数値乱数を発生させることでシミュレーションを行う手法の総称です。潜在的ディリクレ配分法は、文章中の話題(トピック)を導き出すためのトピックモデルの一種です。
sim2realはシミュレーション上で学習した深層学習モデルを実環境で利用するために使われる手法です。シミュレーションを用いてあらかじめ方策を学習し、その学習した方策を実世界に適用する手法です。これにはGPUを必要とします。課題は、シミュレーションを用いて訓練したロボットを実環境でうまく適応させることが困難なことです。これはパフォーマンスギャップと言われ、実世界の全ての側面を正確に把握することはできないために発生します。対策として、ドメインランダム化(ドメインランダマイゼーション)が有効です。歩行ロボットのシユレーション環境における地形形状を表すパラメータのランダム化を適用します。学習時に、実際のロボットなどのハードウェアは必要としません。
オフライン強化学習は、過去に集めたデータのみを使って強化学習を行う手法です。直接環境に作用するときの危険や費用を伴う医療、自動運転、ロボティックスなどへの実用化で期待を集めています。従来の強化学習では、実際に環境と作用しながら学習しており、これをオンライン強化学習と言います。オンライン強化学習では、最適な意思決定を獲得できるまでに、最適でない選択による環境との作用を多く必要とします。オフライン強化学習では、実環境から集めた過去のデータを使います。シミュレーションのデータは用いません。
オセロ、将棋、囲碁のようなゲームの探索アルゴリズムにMini-Max法が有効です。Actor-Critic法は行動を決めるActor(行動器)を直接改善しながら方策を評価するCritic(評価器)を同時に学習させる仕組みです。
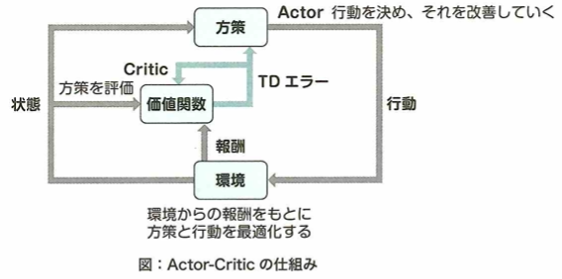
SARSA法はQ学習とにた強化学習のアルゴリズムで、今選択する行動によって、価値の高い状態に遷移できるを評価するために、実際にエージェントを行動させて得られた次の状態における結果を伝播させ、これを参考に少しずつQ値(状態行動価値)を更新し、行動を最適化します。
A3Cは2016年にDeepMind社によって提案された、Actor-Criticを用いてアルゴリズムで、複数のエージェントが同じ環境で非同期に学習するのが特徴です。A3はAsynchronous、Advantage、ActorでCはCriticです。複数のエージェントが同じ環境で非同期にrollout(ゲームプレイ)を実行します。経験の自己相関が引き起こす不安定な学習は強化学習の課題の1つですが、A3Cはエージェントを並列化することで経験の自己相関を低減し、学習の安定化を図れます。
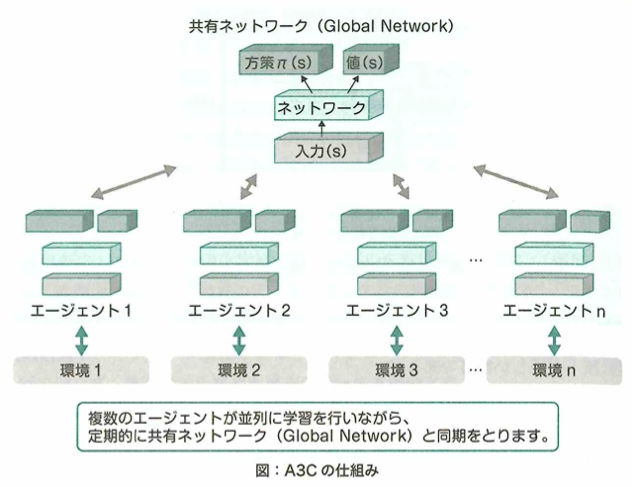
ターゲットネットワークは、DQNの学習テクニックです。現在学習中のネットワークと、過去に遡ったネットワークのTD誤差を教師データのように使う仕組みで、価値の推定を安定させる効果があります。パラメトリックTTSとは文章から音声に変換するtext-to-speech(TTS)手法の一種です。話す内容や特徴を入力パラメータによって操作しながら音声を生成します。
複数タイプの入力情報を同時に利用する技術をマルチモーダル技術と言います。ロボティックスへの応用も含め、複数モーダルの情報の取り扱いに関する研究が進行し、マルチモーダルAIが実現されてきています。五感を模倣することになり、人間らしい知能と行動に近づけます。5つのモダリティを持つと表現します。
Grad-CAMは画像認識モデルに対して予測根拠を可視化するための手法です。画像認識用のCNNの学習に用いられる勾配(最後の畳み込み層の予測クラスの出力値に対する勾配)の情報を可視化に使っています。勾配が大きいピクセルは予測クラスの出力に大きく影響する重要な場所であると判断し、そのピクセルに重みをつけます。

YOLACTはインスタンス・セグメンテーションのモデルで、YOLOは物体検出のモデルです。LIMEは個別のデータサンプルに対し、その結果を別の単純なモデルで近似していくことで特徴量の寄与度を可視化するアプローチです。画像のような非構造化データにも売上データのような構造化データにも適用可能です。つまり局所的な説明ツールです。表形式のデータの場合は、どの変数が予測に効いたのかを説明し、画像データの場合は、画像のどの画素が予測に効いたのかを説明します。大域的な説明ツールであるGrad-CAMは画像データを用いた予測タスクの解釈に特化しています。
モデル解釈に用いられる手法は、局所的な説明と、大域的な説明に分けられます。局所的な説明では、特定の入力データに着目し、どの特徴量が予測に重要だったかを推定します。モデルを説明対象データの周辺でシンプルでわかりやすい線形モデルで近似します。LIMEやSHAPなどがあります。モデルの解釈性は、AI・機械学習のブラックボックス性の解消を目指した研究です。ニューラルネットワークなどの複雑なモデルは高い識別能力を持つものの、モデルによる判断の根拠が解釈しにくいことが実現化の課題です。局所的な説明は、一部の変数についてのみ説明するのではなく、1つの入力データについてのみ全ての変数(特徴量)の寄与を説明します。
ディープラーニングの社会実装に向けて
ディープラーニングを始めとしたAI技術が、世の中でより良く使われるための議論や倫理、法律などに焦点を当てています。AIの技術の進歩や社会適応が進むにつれ、さまざまな問題が発生したり、議論が生まれたりします。その結果、法律が改正されたり、国やさまざまな団体が活用の原則や方針を打ち出したりというアクションがあり、ビジネスなどへ影響が及びます。 特にAIはデータを学習するため、個人情報や機密情報、著作物などの扱いが問題になるケースが多く、日本の個人情報保護法・著作権法やEUのGDPRなどで、データに関する取り決めがされており、企業単位でも透明性レポートなどで、情報に関しての透明性を上げる取り組みがなされています。 さらに、AIは何かの判断やその補助に使われることが多く、予測の信頼性や説明性などが問われるケースがあり、DARPAによるXAIプログラムやEUの「信頼できるAIのための倫理ガイドライン」、日本の「人間中心のAI社会原則」など、さまざまな議論およびその結果生まれた方針や原則が存在します。日米欧でもこういったデータに関する法律や決めごと、AIの信頼性や説明性などに関して問われるケースが多くあります。 このような法律や議論などは、技術の発展を妨げるもののように感じますが、実際に問題になっていることに対する防止や、問題が起こらないための規制・原則であるため、守ることで得られるメリットも少なくありません。 当然、ビジネス上で守る必要がある、もしくは、守るべきものであるため、AIをビジネスに適応していく場合は、法律や議論を知っておく必要がありますし、AIに関する法律や議論はまだ成熟・安定しておらず、日々更新される可能性があります。そのため、この問題集を解くことに加えて、変化するこれらの情報をキャッチアップすることが重要です。
AIと社会
ビッグデータの活用に関連した技術の基礎知識
2000年代から2010年代にかけて、Wi-Fi等の無線通信技術がインターネット通信の高速化および低価格化によって普及し、LPWAのように省電力・低価格かつ遠距離通信可能な無線技術も発達したことで、屋外に設置されたセンサやカメラのようなさまざまな電子機器への通信も容易に可能となりました。このような過程でさまざまなデバイスがシステムと繋がるIoT(Internet of Things)が普及しました。また、インターネットの普及、コンピュータの処理速度の向上や無線通信技術の進展、さらに、スマートフォン等の多様なデバイスの普及によって、ビッグデータの集積が進んでおり、医療、観光、農業といった多様な分野でのビッグデータの利活用が期待されています。ビッグデータの活用やIoT、DXなどに関連する次の説明については次の通りです。
IoTはクラウド、ネットワーク、デバイス(センサ)を基本として構成され、クラウドについては、デバイスのネットワーク接続やデータ収集・処理に関わるIoTプラットフォームと、ユーザーに対して特定の機能を提供するアプリケーションがあります。ビッグデータとは、データの量、データの種類、データの発生頻度・更新間隔(Velocity)の3Vを基本要素として構成されます。RPAはホワイトカラー業務を自動化する技術の総称です。
DX(デジタルトランスフォーメーション)は、「デジタル技術を通して、人々の生活をより良い方向に変化させる」という概念で、2004年にスウェーデン・ウメオ大学のエリック・ストルターマン教授によって提唱されました。今日では、多くの企業でDX(IoTやAI、RPAを活用した技術)の導入が行われています。クラウド技術の発展によって、特別な技術や大規模な施設を持たずとも、IoTをはじめとしたITの各種開発を行うことができるようになりました。このことによって、新規参入のハードルが大きく下がりました。ビッグデータの大部分を占めているのは、非構造化データです。なお、非構造化とは、特定の構造を持たないデータを指し、具体的な例としては、メール、文書、画像、動画、音声などの他、Webサイトのログやバックアップ/アーカイブ等が挙げられます。RPAの各クラスの説明は次表に示す通りです。RPAを導入することで、労働時間の短縮やヒューマンエラー回避に繋がり、労働生産性の向上といったメリットがあります。RPAは仮想知的労働者(Digital Labor)とも呼ばれ、2025年までに事務的業務の1/3の仕事がRPAに置き換わるインパクトがあるともいわれています。
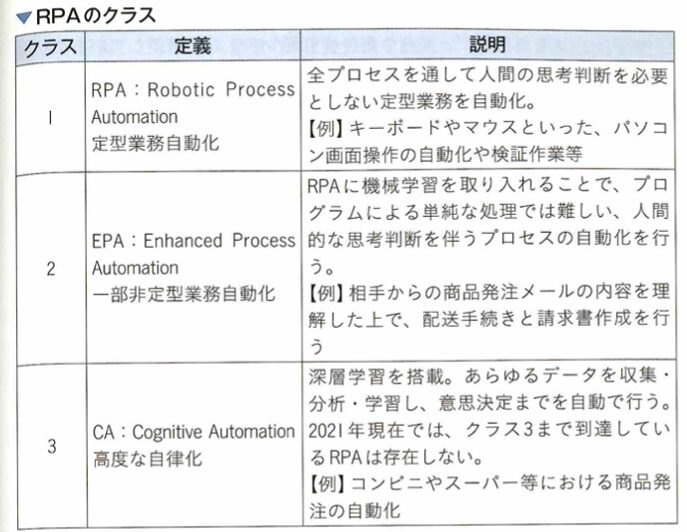
ブロックチェーンの特徴と活用事例
近年、従来の中央管理型のデータベースに変わる新しい技術として、分散型のブロックチェーンが注目されています。ブロックチェーン技術とは、ネットワーク上にある端末同士を直接接続し、暗号技術を用いて取引記録を分散的に処理・記録するデータベースの一種です。実際、ブロックチェーンの活用事例が金融分野を中心に複数出てきており、将来的には、民間企業や公共機関の幅広い分野において、その技術が応用されることが予想されています。
ブロックチェーンをデータベースに活用するメリットは、分散型管理を行うことで、ネットワーク障害によるシステムダウンに強いことです。ブロックチェーンでは、個々のブロックには取引記録に加えて、1つ前に生成されたブロックの内容を示すハッシュ値と呼ばれる情報などを格納します。過去に生成したブロック内の情報を改ざんしようとした場合、変更したブロックから算出されるハッシュ値も変更する必要があります。このような変更は事実行困難のため、ブロックチェーンは改ざん体制に優れたデータ構造を有しています。金融分野におけるブロックチェーンの活用例として、metaによるディエム(旧Libra)があります。従来のデジタル通貨と比べ、価格の安定性が高い仮想通貨(ステーブルコイン)を構築することが期待されていたものの、個人のプライバシーや国家安全保障、犯罪へ用いられることなどの懸念があり、2022年1月でもまだ実現には至っていません。
ブロックチェーンでは、分散管理・処理を行うことでネットワークの一部に不具合が生じてもシステムを維持することができる性質があります。このような性質を可用性といいます。従来のデータベースでは取引において必要であった仲介役が不要になることにより、取引の低コスト化が期待されます。ブロックチェーンは、データの改ざんの有無をリアルタイムで監視可能であるという性質も持っています。この性質を完全性と呼びます。金融分野以外の事例として、ソニーがブロックチェーンを活用し、楽曲の著作権管理システムを構築しています。BaaS(Blockchain as α service)という言葉があり、例えばAmazonweb Serviceなどでは、ブロックチェーンネットワークの作成と管理を簡単に行えます。
プロダクトの設計
AIを導入したプロダクトが陥る問題
AI技術を用いたプロダクトを設計するときには、経営者と開発者が、解決したい課題や対象とする領域を踏まえて、認識をすり合わせながら打ち合わせや会議を十分に行うことが重要になります。 近年よくある失敗が、「ディープラーニング」を導入することが目的化して、良いプロダクトを作れなかったということです。 これを防ぐためにどのように考えるべきかを考えます。あくまで「ディープラーニング」は手段の1つで、プロダクトの要求条件に合いそうであれば、あらかじめユースケースを明確にした上で用いると考えます。
あくまでも「ディープラーニング」は手段の1つとして考えなければ、本末転倒なプロダクトができてしまいます。実際、精度の高いディープラーニングを用いたプロダクトを構築することはできたとしても、「実際の現場でどのように使いたいか?」というように、ユーケースに焦点を当てた構想が不十分であった結果、PoC(Proof of Concept 概念実証。簡単なプロトタイプのデモンストレーション等を通して、アイデアの実現可能性を検証すること。)だけでプロジェクトが打ち切りになってしまうことも多くなっています。
機械学習の開発や運用に用いるプロセスモデル
機械学習(ML)プロダクトの開発・運用において、各プロセスの専門性が高まり分業体制が取られることが増えています。そのような中で、いくつかの問題が顕在化しています。①1つは、MLの開発(Development)サイドと、運用(Operation)サイドの知見やスキルセットが異なることが原因でPoCの障壁を乗り越えられずプロダクトが実用に至らないケースです。また、②分業体制をとっている組織では、各組織が自らの責任を果たすことを最優先しようとするあまり、プロジェクト全体を見た際には必ずしも最適化されていないことがあります。
①においてDevOpsとは、Development(開発)とOperation(運用)を組み合わせた用語です。ソフトウェアの開発を迅速に行うために、開発担当者と運用担当者の連携、協力を重視する開発手法のことを指します。これにより、機械学習モデルやAIモデルを一度作っておしまいではなく、継続的に本番運用していく仕組みや考え方を指します。
MLOpsは、システムの開発(Development)チームと、運用チームが協働してビジネス価値の向上を目指すDevOps(デブオプス)から派生した概念であり、「DevOpsのML版」と位置付けられています。MLOpsとは、MLの開発チームと運用チームが連携、協力して、モデルの開発から運用における一連のMLライフサイクルを管理する基盤、体制のことであり、その目指すところは「機械学習システムの効率的でスムーズな実運用」です。こうした一連の作業の一部または全てを自動化できることにより、MLを実際に活用し始めるまでのタイムラグを小幅にとどめられます。
CRISP-DMはCRoss-Industry Standard Process for Data Miningの略で、同名のコンソーシアムで提案されたデータマイニングのプロセスモデルです。これを日本語に訳すと「業界の枠を超えたデータマイニングの標準プロセス」という意味になり、業界、ツール、業務分野のそれぞれに中立なデータマイニング用の方法論として注目されています。 CRISP-DMは、新たにデータマイニングを採用しようとするユーザーにノウハウを提供することを目的で、「データマイニングを正しく実践してもらい、データマイニングを正当に評価してもらうこと」を目的に開発されました。 なお、データマイニングの定義、または簡単ツールベンダーによってまちまちですが、たとえば、SAS Institute Japanのページ(https://www.sas.com/ja_jp/insights/analytics/data-mining.html)では、「未知の結果を予測するために、大量のデータセットに含まれている異常値、パターン、相関を発見するプロセスのこと」としています。 対象とするビジネスおよび使用データを理解した上で、データ準備、モデリング、評価、展開を行います。ただし、必要に応じて前のステップに戻ったり、最後の「展開」をした後に最初の「ビジネスの理解」に戻ったりするのがCRISP-DMの考え方です。
プロジェクト全体での全体最適が模索されているような状況を根底から改革しようとするアプローチがBPR(Business Process Re-engineering)です。具体的には、全社が共通に目指すことのできる目標(中長期的な事業戦略や顧客のニーズが使用されることが多い)設定、トップダウンによるプロジェクト組成、既存の枠組みにとらわれないゼロベースの思考、ITの積極的活用、担当者への権限委譲などにより、目標に向かった全体最適を追求していくのが特徴です。
クラウドとWebAPI
クラウドとは、クラウドコンピューティング(Cloud Computing)を略した呼び方で、データやアプリケーション等のコンピュータ資源をネットワーク経由で利用する仕組みのことです。ネットワークに繋がったPCやスマートフォン、携帯電話などにサービスを提供しているコンピュータ環境がクラウドです。企業がクラウドサービスを利用する効果としては、①システム構築の迅速・拡張の容易さ、②初期費用・運用費用の削減、③可用性の向上、④利便性の向上が挙げられます。APIとは、アプリケーションやソフトウェアの構築、統合に使われるツール、定義、プロトコルのことです。APIを使用することで、他の製品やサービスの実装方法を知らなくても、利用中の製品やサービスをそれらと通信させることができます。Webサービスがアプリ開発者向けに公開している機能をWebAPIといいます。Webサービスの機能を利用する場合、ユーザーは、公開されたAPIのURLに対してHTTPでリクエストを送り、そのレスポンスを受け取る形でサービスを利用することになります。たとえば、Google MapsのWebAPIを利用することで、任意のWebページ上に最新のマップを表示することなどが可能となります。 なお、HTTP/HTTPSプロトコルによる通信を基本としたWebAPIの実装例としてはREST/RESTful APIが有名です。一般に、REST/RESTful APIは高速で軽量になり、スケーラビリティが向上するので、IoT(モノのインターネット)やモバイルアプリ開発に最適とされています。
APIはApplication Program Interfaceの略です。一方でSDKは、Software Development Kit(ソフトウェア開発キット)の略です。対象のプラットフォーム、システム、またはプログラミング言語向けのアプリケーションを作成するために必要な構成要素(開発ツール)が含まれています。基本的なSDKにはコンパイラやデバッガ、API、そして多くの場合、サンプルコードも含まれています。サンプルコードは、基本的なプログラムの構築方法を学ぶのに役立つだけでなく、プログラムとライブラリを開発者に提供します。開発者はそれを使って複雑なアプリケーションを容易に最適化あるいは開発したり、必要に応じてデバッグや新機能の追加を行ったりすることができます。
Android SDKと.NET Framework SDKはそれぞれ、Google社とMicrosoft社が提供しているSDKです。また、Web APIの代表例として、REST/RESTful APIとSOAP APIなどが挙げられます。SOAPとはSimple Object Access Protocolの略で、HTTP/HTTPS以外にもSMTPやTCPのような任意の通信プロトコルを使用することができます。SOAP APIは、元々はプログラミング言語やプラットフォームが異なるアプリケーション間でも通信できるようにするために設計されました。一方のREST/RESTful APIは、HTTP(ハイパーテキスト転送)プロトコルを用いた通信を採用しており、Representational State Transfer(REST)という設計原則(ガイドライン)に基づいて設計されたWeb APIです。REST/RESTful APIについては、一般にはSOAP APIよりも軽量であるという特徴があり、IoT等の最新技術と相性が良いと言われています。実際、Google Maps APIをはじめとした多くのパブリックAPIは、RESTガイドラインに準拠しています。
データの収集
サンプリングバイアス
AIプロダクト開発におけるモデルの作成時には、収集したデータが必要になります。データを収集する際において、「データに不適切な偏りがないか」という点には、入念に気を付けなければなりません。 以下に、データ収集の際にさまざまな要因による不適切な偏りがあったために問題となった例を載せます。問題となった理由が「データの不適切な偏り」でないものは、Apple社がAIアシスタントSiriを開発しましたが、録音した顧客の音声を外部の契約者に聞かせて問題となったことです。
データ取得時あるいはクレンジング工程において、手元のデータに偏りが生じた結果、サンプリング元のデータセットを解析した際には見られないような特徴があるように見えてしまうことを、サンプリングバイアスと言います。サンプリングバイアスと似た用語に、データバイアスというものがあります。これは、サンプリングする大元のデータセット自体に、バイアス(たとえば、人種差別等)がある場合を指します。他方、大元のデータセットには特別なバイアスがなくとも、サンプリングの工程で偶然「この人種は再犯率が高い」かのようなデータセットを意図せずに作成してしまい、それをAIに学習させた結果、偏った推論結果を出力してしまうようなケースは、サンプリングバイアスに該当します。
人種差別的な偏りとは、データセットに人種による偏りが存在し、それをそのままプロダクトに反映させてしまったものです。 性差別的な偏りでの注意点は、過去の人事評価が性別により大きく影響していたとしても、それをプロダクトに反映させてはいけません。 情報バイアスとは、データ自体が採取できるかどうかに別の要因が絡んでくることから、適切なデータとはいえません。例えば再販確率を計算するAIを開発しましたが、実際に検挙されデータに反映されている犯罪が全体の半分程度という事例です。 プライバシーの問題の場合は、データの不適切な偏りとは関係ありません。
データが不適切なために起こる問題は他にもあります。Microsoft社は2016年に、19歳の女性の話し方を模倣するように設計されたチャットボット「Tay」をさまざまなソーシャルネットワークサービス(SNS)に向けてリリースしました。しかし、リリースから数時間後に「Tay」は公開停止されてしまいます。理由は、不適切な発言が多かったためです。SNS上にて不適切な発言を多く投げかけられた「Tay」は、それらの発言を学習してしまい、自らもといった発言をしてしまうようになってしまいました。 このようにデータを収集する際には、倫理的に問題のある偏りが生じないように、できるだけまんべんなくデータを採取する、もしくは元のデータを工夫して不適切な偏りをなくす必要があります。また、問題になることが予測できない場合でも、あくまでAIの判断は人間の補助として扱い、最終的な判断は一個人にさせる形にするのも1つの手です。これにより責任の所在が明らかになるためです。
オープンデータセット
2000年代初頭から続く世界的なオープンデータ政策への取り組みの中で、民間事業者と公共事業者の両方で、さまざまなオープンデータセットが整備されてきました。日本では、2012年の「電子行政オープンデータ戦略」(IT戦略本部決定)を機に政府の取り組みが本格化しました。なお、政府がオープンデータ政策に関わる目的として、「電子行政オープンデータ戦略」では、①政府の透明性・信頼性の向上、②国民参加・官民協働推進、③経済活性化・行政効率化等の3つを挙げています。
日本政府は、二次利用が可能な公共データの案内・横断的検索を目的としたオープンデータのカタログサイトとしてDATA.GO.JPを公開しています。また、政府のみならず、生活に密着した情報を持つ地方公共団体、あるいは民間団体によるオープンデータ活用等の動きも活発です。オープンデータ化の対象としては、統計情報や地理空間、気象や交通等、数値・文書・画像等があらゆるものです。一方で、機密情報や個人情報等は公開の情報は対象ではありません。民間企業や大学等が提供するオープンデータセットの例として、たとえば画像分野ではMNISTやCIFAR-100、Google Open Images V6、ImageNet等があります。他にも自然言語ではDBPedia、音声分野ではGoogle社の公開するAudioSet等があります。
公共データについて、オープンデータを前提として情報システムや業務プロセス全体の企画・整備および運用を行う「オープンデータ・バイ・デザイン」の考えに基づいて、国や地方公共団体、事業者が公共データの公開および活用に取り組んでいます。各府省庁が保有するデータは原則公開されており、CSVやXML形式でデータ入手可能となっています。公開することが適当ではないデータについては、原則として公開できない理由を開示すると共に、限定的な関係者間での共有を行う「限定公開」という方法も存在します。オープンデータセットに関する説明を、次の表に整理します。ここで挙げたものがすべてではなく、他にも多くのオープンデータセットが整備されています。
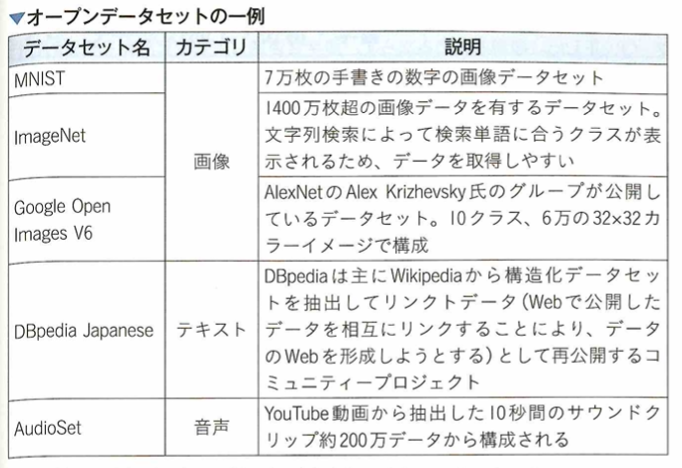
アイデアソンやハッカソンに対して、「現実社会の課題解決に繋がっていない」等の批判があります。生まれたアイデアや試作品を実用できる行政サービスやビジネスに磨き上げることが現状の課題であり、ハッカソンで生み出されたアプリケーションやサービスの有効性を検討したり、使い勝手の改善をしたり、普及のための方策を考えること等が重要です。
オープンイノベーションの考え方に基づく外部機関との連携や連携時の契約問題
IT技術の急速な発展・普及と、製品の高度化・複雑化や競争の激化によって、1990年代以降、自社内の経営資源や研究開発に依存する「自前主義」が限界に達しました。そのような中で、2003年、当時のハーバード大学教授・ヘンリー・チェスブロウによって「オープンイノベーション」が提唱されました。 オープンイノベーションとは、「組織内部のイノベーションを促進するために、意図的かつ積極的に内部と外部の技術やアイデアなどの資源の流出入を活用し、その結果組織内で創出したイノベーションを組織外に展開する市場機会を増やすこと」と定義されています。
オープンイノベーションのメリットは、事業推進スピードの向上やコストやリスクの低下が挙げられます。一方で、デメリットとしては社内技術や知識が外部に流出する可能性があることが挙げられます。知識集約型の産業構造の転換や、さまざまな変化に対応する多様性や柔軟性が求められ、中産学官連携の拡大によるオープンイノベーションを加速する必要があります。ビジネスにおける契約の方法として、「基本契約」と「個別契約」があります。後者が発注書等を交わして個々の取引について合意するのに対して、前者は個々の取引に共通する基本事項を定めておくことで、取引の契約書の作成等、契約にかかるコストを低減させることができます。
オープンイノベーションに伴う自社技術・知見の流出の可能性について、もちろん知的財産の適切な管理は重要ではありますが、それ以外にも、革新的な部分はブラックボックス化して秘匿しつつ、その他の部分については他社に知的財産を使用させることで利益を得る「オープン&クローズ戦略」や、逆に他者の知的財産を購入し、自社のビジネスモデルを発展させる柔軟な方法もあります。
産学連携のみならず、産学官連携による研究開発も積極的に行われています。ちなみに、2025年までに企業から大学、国立研究開発法人への投資額を3倍にすることを定量的な目標とし、目標達成に向け具体的な取り組みをまとめた「産学官連携による共同研究強化のためのガイドライン」が文部科学省より発行されています。
日本初イノベーションを実現する手段の1つとして、オープンイノベーションへの期待が高まっていますが、未だ十分な成果が得られていません。原因の1つに、大企業等の事業会社による中小ベンチャー企業に対する知的搾取の問題が指摘されています。このような問題を放置すれば、イノベーションシーズの出し手たるベンチャーや大学の研究開発の意欲を低下させ、また資金が還流しないことで研究開発の継続が困難となり、日本から新たなイノベーションが消失することになりかねません。事業会社によるイノベーション搾取の構造を作り出す主要因は、技術取引契約(秘密保持契約、共同研究、ライセンス契約)です。さらにその背景として、ベンチャー等の知財法務の知識不足、また事業会社のベンチャー等への無理解であることは従来から指摘されています。また、余談ですが、近年では契約の複雑化・高度化が進んでおり、契約で定めておくべき事項に関して契約の「型」を示す「AI・データの利用に関する契約ガイドライン」が経済産業省から発行されています。本ガイドラインは契約の自由を制約するものではありませんが、たとえば「対価・支払い条件において『甲は、提供データの利用許諾に対する対価として、乙に対し、別紙の1単位あたり月額○円を支払うものとする。』といったように、契約書作成を補助する内容になっています。
基本契約と個別契約を組み合わせることで、特に中長期継続する取引における契約コストを低く抑えることができます。たとえば、メールにて契約を締結するといったように工夫することで、より簡潔に個別契約を結ぶことができます。なお、個別契約には商品明細・価格・納入条件・代金支払い条件(基本契約でも含意される)を含意します。
データの加工・分析・学習
AIプロダクトにおけるプライバシーの配慮
実務においてAIプロダクトを運用していく際に、用いるデータが個人のプライバシーを脅かすようなデータであることがあります。特に、AIプロダクトは、データが必要なことが多いため、データがあればあるほどいいと考えてしまい、プライバシーに関する点がおろそかになってしまう可能性もあります。 たとえば、小売店にカメラを複数設置することにより、顧客の導線のパターンを見つけ、適切な商品配置をするプロダクトがあるとします。しかし、来店者の受け取り方によってはそれが「不快感」や「監視されている」と感じてしまうことにつながることもある。そのため、プライバシーに配慮した工夫が必要です。 プライバシーに配慮したプロダクト設計に関することで、誤っているものを考えます。肖像権・プライバシー権・個人情報保護法などの法令上に触れているのみ確認すれば問題にはならなくはないです。
実務においては、「法令上のみ」確認していても、顧客の反対から失敗する可能性もあります。事実、2013年に独立行政法人情報通信研究機構(NICT)は、大阪ステーションシティに90台のカメラを設置し、実証実験を行う予定でしたが、プライバシーの観点から懸念があり、一度延期になっています。このとき、「法令上は、全く問題ありませんでしたが、「説明責任」という点で不明確であったため、中止になりました。そのため、「法令上」だけでなく、他のガイドラインを参考にし、プロダクトの設計を考える必要があります。
顧客の顔の画像をカメラで撮ったままの状態ではなく、必ず加工し特徴量として変換した形で扱い、加工したら画像は破棄するように設計することは、総務省・経済産業省から発行されている、「カメラ画像利活用ガイドブック」において、データとして取得したカメラ画像の扱い方の方針として記載されています。そもそもそういったプロダクトを受けるかどうかを顧客に選択させるという工夫もあります。たとえば、空港で身体検査を画像認識において自動化しようとする場合、プライベートなデータが残ってしまうかと懸念する場合には、通常の人間によるチェックを選択できるようにすることで、プライバシーでの懸念が出ないように工夫することもできます。
他には、AIプロダクト品質保証コンソーシアムが公表している、「AIプロダクト品質保証ガイドライン」を参考にしてプロダクト作成を進める。ことや、EU一般データ保護規則(通称GDPR)はヨーロッパでのプライバシー保護規則ですが、日本の企業がヨーロッパにサービスを提供している場合、この規則の対象になるため、このGDPRもチェックしなければならない。などがあります。
アノテーション
生データに対して、生データとは別のデータ(以下、「付加データ」)を付加する場合(このような付加データの付加行為を「アノテーション」ということもあります)。そのような付加データには、生データと同様に、生成される学習済みモデルの内容・品質に大きな影響を及ぼす一方、生データから独立した形式ではその用をなさないという性質があります。(中略)教師あり学習の手法を用いる場合についていえば、前処理が行われた生データにラベル情報(正解データ)を合わせたものが学習用データセットに相当します。(経済産業省「AI・データの利用に関する契約ガイドライン」より引用)
アノテーションとは、機械学習の学習用データセットを作成するために、生データに対して新たなデータを付与することを指します。 具体的には、犬の画像に対して「犬」のように、生データに対してメタデータをタグ付けする行為です。画像データの他にも、テキストデータ(文章から読み取れる感情など)や音声データ(音声データを書き起こしなど)といったように、あらゆるデータに対し、解きたいタスクに適した形でのアノテーションが行われます。近年、自動アノテーション技術が開発されています。アノテーションには多大な労力、時間がかかり、AI開発のボトルネックになることも多かったです。 そのため、アノテーションの自動化によって、関連AI技術が加速度的に発展することが期待されます。アノテーションを行う場合、(ユーザーから)第三者に委託されることがあります。一般に、ユーザーが特にベンダーの開発に期待して契約関係に入った場合、ベンダーに委任されたアノテーション業務をさらに第三者へ再委任するためには、ユーザーの承諾が契約上必要とされます。
セキュリティや緊急のホットラインのアプリケーションなどに対してアノテーションを行う場合には、攻撃的な口調であったり、ガラスの割れるような音声に対してアノテーションを行うことも考えられます。テキストデータに関しては、文章から人間の感情をアノテーションするセンチメントアノテーションや、商品のタイトルや検索クエリ内のさまざまなコンポーネントにタグを付与することで(セマンティックアノテーション)、商品の改善や顧客が探している商品を見つけるというタスクを実現します。
Zhang et al. (2021) では、ミカン果樹園やトマト温室の写真から高精度に果実を検出するAIを構築しました。Zhangらが開発したような物体検出AIは、スマート農業技術の中核であり、彼らの取り組みをはじめとしたアノテーションの自動化によって、関連分野のAI開発が加速度的に発展することが期待されています。
フィルターバブル
商品のレコメンドシステムや検索エンジンにおいて、自分が見たいものや欲しい情報のみに包まれてしまうということが、近年問題視されています。レコメンドシステムや検索エンジンはユーザーが求めているものを出力することを目標にしてプロダクトを作っているため、自らの興味がないものが視界から消え去ってしまうのは当然ですが、それが普段の身の回りを覆いつくすようになってしまうほどになると、副次的な問題に発展してしまいます。 たとえば、政治的な問題や傾向については、さまざまな目線を持つことは重要であるが、レコメンドエンジンより自分の欲しい情報に囲まれてしまうと、主張に偏りすぎてしまうという問題が発生します。 このような現象を、インターネット活動家であるイーライ・パリサーが2011年に出版した著書名から、フィルターバブルと言います。
Pythonに関連する開発環境
Pythonは、1990年代初頭から公開されているプログラミング言語であり、高い可読性と実用性のバランスの良さから人気を有しており、2010年代からの機械学習ブームでも、優れた科学技術計算ツールとして広く用いられています。Pythonに関わる開発環境について考えます。
Jupyter Notebookとその柔軟なインターフェースは、コードだけでなく、可視化、マルチメディア、コラボレーションなど、ノートブックをさまざまな用途に拡張します。コードを実行するだけでなく、コードとその出力をMarkdownとともにノートブックと呼ばれる編集可能なドキュメントに保存できるなどの特徴があります。JupyterLabは、ノートブック、コード、データのためのウェブベースの対話型開発環境で、従来のJupyter Notebookの構成要素(ノートブックやターミナル、テキストエディタ、ファイルブラウザなど)を、柔軟かつ強力なユーザーインターフェースを通して利用することができます。Dockerとは開発者やシステム管理者が、コンテナでアプリケーションを構築(build)、実行(run)、共有(share)するためのプラットフォームです。コンテナでは、ホストと他のコンテナから隔離(isolate)し続けるために、複数のカプセル化する機能を追加したプロセスが走っています。コンテナ隔離(isolation)の重要な特長は、各コンテナが自分自身のプライベートファイルシステムとやりとりできる点です。すなわち、このファイルシステムはコンテナイメージ(Dockerの場合Dockerイメージ)によって提供されます。
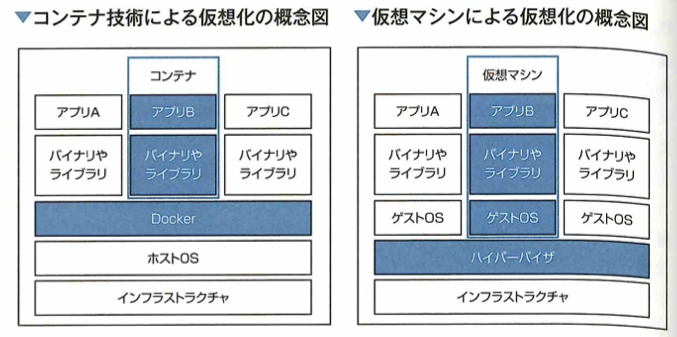
JupyterLabやJupyter Notebookは、Project Jupyter(インタラクティブで再現性のあるコンピューティングのためのオープンソースプロジェクト)によって開発されています。これらのツールを使用することで、コード、可視化、マルチメディア、およびコラボレーションを1つのノートブックで行うことができます。ソフトウェア、オープンスタンダード、サービスを開発するための非営利団体によって開発されています。
「ハイパーバイザーというソフトウェアによって、固有のCPU、メモリ、ネットワークインターフェース、ストレージなどの物理リソースを仮想環境から分離します。これによって、たとえば、「MacOSノートパソコン上でLinuxディストリビューションを実行する」というように、複数の異なるオペレーティングシステム(OS)を1台のコンピュータ上で同時に実行できます。」は仮想マシンに対するものです。コンテナによる仮想化技術は、OS上に仮想的に複数のコンテナ(分離、独立した領域)を設け、その中で、アプリケーションを実行、動作させる仕組みです。次の図は、コンテナによる仮想化とサーバ仮想化の概念図です。サーバ仮想化(仮想マシン)では、サーバOSがサーバ資源を利用する際に無駄が多くなるのに対して、コンテナでは、サーバ資源は1つのOSが利用するのでCPUやメモリなどの負荷が小さく、リソースの無駄が少ないといったメリットがあります。 なお、コンテナ化の人気が高まるのは、コンテナが次のような特徴を持っているためです。 ①柔軟:複雑なアプリケーションでもコンテナ化できる。 ②軽量:システムリソースに関しては、仮想マシンよりも効率的に扱うことができる。 ③可搬性:ローカルに構築し、クラウドにデプロイすることで、どこでも実行できる。 ④簡潔合:コンテナは、自分で完結し、カプセル化している。そのため、他の何かの中断をしなくても、置き換えやアップグレードが可能。 ⑤拡張性:データセンタ内の至るところで、複製したコンテナの追加と自動分散が可能。 ⑥安全性:利用者による設定がなくても、コンテナは積極的な制限と分離(isolate)をプロセスに適用する。
コンテナ技術は、コンテナを実行する「コンテナ管理ソフトウェア」、コンテナの元データとなる「コンテナイメージ」、コンテナイメージから作成され、実行されるアプリケーションである「コンテナ」の3つです。(コンテナ)イメージは、コンテナに格納されるアプリケーションやアプリケーションの実行に必要な設定ファイル、実行環境、ミドルウェア、ライブラリなどをひとまとめにした、ファイル、設定情報のかたまりのことです。
ライブラリやフレームワーク
ライブラリやフレームワークの両者に共通する目的は、他の誰かが書いたコードや関数を、さまざまなプロジェクトで再利用できるようにし、問題をより簡単に解決することです。機械学習分野でよく用いられるライブラリ、フレームワークに関して考えます。
NumPyは、配列に対する高速演算のためのルーチンを提供するPythonのライブラリです。Pythonの標準的な配列とは異なり、NumPy配列という配列を採用しています。NumPyを用いることで大量のデータに対する高度な数学的操作等を容易に行うことができます。Pandasは、SQLテーブルやExcelスプレッドシートのような、2次元の表形式データ(DataFrame)や、時系列データ等の1次元データ(Series)を取り扱うライブラリです。欠損値の扱いが容易であることや、PythonやNumPyによって崩れたデータを簡単にDataFrameオブジェクトに変換できることなどが特徴です。PyTorchは、Facebook(meta)社のAIグループによって開発され、2017年にGithubのオープンソースとして公開されたTorchベースの深層学習フレームワークです。PyTorchはシンプルで使いやすいことで有名で、柔軟性、メモリの効率的な使用、動的な計算グラフなどについても高い評価を得ています。
ディープラーニングのフレームワークは、大きく分けて2つに分けられます。1つは、静的計算グラフを用いたアプローチ(直訳すると、計算グラフを定義し、そして、データを流す)であるDefine and Run。もう1つは、動的計算グラフによるアプローチ(データを流すことで、計算グラフが定義)Define by Runです。Define by Runのアプローチは、2015年にChainerによってはじめて提唱され、それ以降、多くのフレームワークに採用されています。通常のNumPyを使うときと同じ作法で数値計算を行うことができる点や、計算グラフを「コンパイル」して、独自のデータ構造へと変換する必要がないという点がメリットです。当初のTensorFlowでは、Define and Runを採用していましたが、のちにDefine by Runスタイルも取り入れ、TensorFlow ver. 2.0以降ではデフォルトになっています。
FAT
AIが学習するデータが偏っていたり、ノイズがある場合、AIがいつも信頼できる結果を出力するととは限りません。AIを安全かつ安心に社会実装するためには、AI製品やサービスの信頼性を担保することが欠かせません。 昨今、世界中でAI倫理に関する議論が進展しています。AIがブラックボックスであるが故に、採用活動等のような意志決定の現場へのAI活用が難しい等の問題が起こっており、AIの公平性や透明性・信頼性の向上が急務です。こういった問題への対処として、日本では7つの原則からなる「人間中心のAI社会原則」が定められています。その中には、AI利用による公平性や、透明性のある意志決定、説明責任の確保といった内容が「FATの原則」という項目として設定されています。
FATとは、Fairness(公平性)、Accountability(説明責任)、Transparency(透明性)の頭文字を取ったものです。XAIは、Explainable AI(説明可能なAI)、ELSIは、Ethical, Legal and Social Issuesの頭文字、RRIは、Robot Revolution & Industrial IoT Initiativeの頭文字です。
ELSIとは、社会、人間への影響や、倫理的、法的、社会的課題のことを指します。機械の自律性(判断、推論の信頼性の保証)などが例として挙げられます。たとえば、人間の関与なしに自律的に攻撃目標を設定することができ、致死性を有するLAWS(Lethal Autonomous Weapons Systems:自律型致死兵器システム)は、AIの軍事利用の観点で一番の懸念の一つと見られています。これについては、特定通常兵器使用禁止制限条約(CCW)の枠組みに基づき、CCW締結国の中で2014年から会合が持たれ、2019年11月には11項目から成る「LAWSに関する指針」が示されました。引き続き、LAWSの定義(特長)、人間の関与のあり方、国際人道法との関係、既存の兵器との関係等、規制のあり方が主論点とされており、規制に対する推進派、穏健派、反対派に各国の立場が分かれています。 ELSIの他の例としては、フェイクニュースやフェイク動画による被害等が挙げられます。また、ELSIの文脈からは少し外れますが、AIの悪用という文脈で、AIがわざと間違った結果を出力するように意図的に入力データを作成する、敵対的サンプルを用いた攻撃なども注目されています。意図的に自動運転車に道認識を認識させる研究などもあり、生命に影響を与えるような攻撃に対する頑健性は、AIを実用化する上でとても重要です。RRIとは、2015年に日本経済再生本部で決定した「ロボット新戦略」に基づいて決定された民間主導のプラトフォームです。「ロボット新戦略」では、日本が世界のロボットイノベーション拠点になることなどを目標とした活動を行なっています。
プロダクトの実装・運用・評価
AIプロダクトを運用する際のリスク管理
AIによる予測も精度も完全ではないので、リスクを避けられるようにモデルをチューニングする必要ができます。たとえば2015年にGoogle社の写真アプリGoogleフォトがアフリカ系の女性にゴリラとタグ付けしてしまった事件がありました。そのほかにも不適切なことがありました。こういった事態を避けるのに適切な方法の1つは混同行列などを用いて「何を何と間違えることがあるのか」、またその確率を確認することです。そうすればアフリカ系の人種はゴリラと間違えやすいなどを事前に発見でき、そのリスクを最大限に活かしたモデルにチューニングできます。もちろんその他の方法(例えばデータセットからゴリラを削除するなど。Google社はこの対応を取ったとされています)も複数ありますが、何も対策を講じない等のはリスクが高いです。事前に対策をしていたということが大事です。ただし、タグやカテゴリの数が数千数万になると、リスクを回避するためのコストもある程度かかってしまうため、回避する手段は工夫しなければなりません。または、そういった工夫を自薦にしたことを、報告書として世に出せる状態にしておくことで、不測の事態にも備えられるようにするのは1つの手です。これは透明性レポートと呼ばれます。
混同行列であれば、何をどのように間違えたのかがすぐにわかります。ただし、ラベルが100あればマス目はその二乗の1万あることになるので、すべてのパターンを確認するのは骨が折れます。そのため、実際のプロジェクトでは、かかるコストも考えて対策を講じる必要があります。
AI社会における企業の在り方
人間とAIが共存する社会では、多様性や持続性を守ることが重要です。これは「人間中心のAI社会原則」(内閣府、以下「AI原則」と呼ぶ)の基本理念にもなっています。 一方で、我が国におけるAI原則には法的拘束力がないことから、特に経済活動の大部分を担う企業において、経営上のコストにもなり得るAI原則実施への取り組みが必要です。
企業においてAI原則の実効性が確保されるように、「コーポレートガバナンス」の一環として位置付ける必要があります。IoTやRPA、AIといった最新技術等が活用されていく中でリスクは複雑化しています。そのような状況下で投資機関や消費者等各ステークホルダーにとって「良い企業」であるために経営者は、社員が守るべきルールである「内部統制」を必要に応じて更新していく必要があります。AIを開発・活用する企業として、顧客との信頼性の構築のためには、透明性を担保することが重要です。取り組みの例として、AIを利用しているという事実やデータの取得/使用方法、AIの動作結果の適切性を担保する仕組みの実施状況の公開等が挙げられます。AI技術の発展と、倫理的問題を含めた社会課題の解決を共同で行っていくためのAI研究団体に「Partnership on AI」という組織があります。組織の指針となる原則には、個人のプライバシー保護への取り組みや、AI研究全体の社会的責任の維持、AI研究とテクノロジーの健全性や安全性の確保などが挙げられています。
日本のみならず世界各国でAI原則の策定が進む中で、今後AI開発や利活用に関係する事業者によるAI原則の実施が重要な課題となるとされています。新たなテクノロジーが次々と出てくる中で、企業内において内部統制の更新が追いつかなくなった場合、ガバナンスの脆弱性や陳腐化したルールや手続きが残ってしまい、業務効率が悪くなったりする可能性があります。ブラックボックスとも呼ばれるAIの透明性は、社会的にも大きな論点になっているので覚えておきましょう。実際、「AI開発ガイドライン(総務省)のAI開発原則の中に、「透明性の原則(開発者はAIシステムの出力の検証可能性および判断結果の説明可能性に留意する)」が含まれています。Partnership on AIは、2016年にGAFAM、IBM社、DeepMind社が主要メンバーとなって設立した団体で、2022年1月末に15ヶ国95団体が所属しています。パートナーとしては産業、アカデミア、メディア、非営利団体がおり、非常に多様性に富んでいます。日本の営利企業ではSONYが加入しています。
炎上というリスクに対するリスクマネジメントの取り方
近年、誤投稿等が原因となって個人や組織が批判され、収束を図れない状態になる「炎上」が起こりやすくなっています。背景としては、たとえば、SNSの普及によって、誤投稿等が容易に拡散されるようになったこと等が挙げられます。 「炎上」が起きることは、企業にとって大きなレピュテーションリスクとなることから、ネット上の書き込みをモニタリングしておくなど、リスクマネジメントをすることが必要となります。炎上への対策は経営課題として重要となっています。
炎上対策として、炎上した場合を想定した訓練が有効です。具体例としては、「シリアスゲーム」というものがあります。これは、ゲーム感覚で炎上を体験し、炎上してしまった際のすさまじさをあらかじめ体験しておき、有事の際の対応を学ぶものです。AIシステムを開発する側の視点としては、「DEI」を意識することが炎上対策に繋がります。DEIとは、Diversity(多様性)、Equality(平等性)、Inclusion(包摂性)の頭文字をとったものです。 AIシステムを利用する個人や法人においては、AIの挙動を管理するツールの利用や危機管理体制の構築、見直しを行うことが炎上対策の一環となります。
シリアスゲームとは、もともと企業の炎上対策だけではなく、教育や医療にわたる広い分野の社会問題の解決を主目的とするコンピューターゲームのジャンルです。単なるシミュレーションとの違いは、ゲーム(一人または複数のプレイヤーによる)をベースとして作られている点です。シリアスゲームには、チャレンジする要素があり、インタラクティブで対話がある、ゲームをクリアする過程で社会課題を考えさせられる等の要素があります。炎上が発生したあとに行う危機管理対応は、クライシスコミュニケーションといいます。なお、リスクコミュニケーションとは、リスクに対して事前の説明や、理解を得るための行うコミュニケーションを指します。具体的には、情報公開を定期的に行ったり、自社の事業が影響を及ぼすと思われる範囲の人々の意見に対して、聞く姿勢を見せること等が挙げられます。DEIの考え方は、Amazon等世界的な企業でも採用されています。DEIの原則を守らないAIは、恩恵を受けられる人と受けられない人を生みます。こういった格差の積み重ねは、結果的にAI技術の更なる発展を妨げることにも繋がる可能性があります。また、他にも透明性レポートを公開することも重要です。近年では、AIの予期せぬ挙動(たとえば、AIによるSNS上での不適切な投稿)が炎上に繋がる事例も起こっています。AIの監査ツールを導入すること等はそういったリスクの低減に貢献します。
AIと法律・制度
知的財産権の法的問題
AIと法制度に関る課題の1つとして、学習データや学習済みモデルの知的財産権保護と流通容易性が矛盾するという点があります。たとえば、不正な漏洩を防ぐには学習済みモデルに知的財産権を認める必要があるが、知的財産権が認められると権利処理の手間の煩雑さのため既存モデルの流通が困難となります。そこで、平成30年に不正競争防止法が改正され、知的財産権が認められていないデータの保護に関しても、一定の対策が可能となりました。
データ(データベースでなくデータそのもの)の保護については、不正競争防止法では、一定の要件を満たせば保護の対象となりますが、特許権や著作権の保護の対象ではありません。
GDPR
EU一般データ保護規則GDPRは、EUを含む欧州経済領域内にいる個人の個人データを保護するためのEUにおける統一的ルールであり、域内で取得した「氏名」や「クレジットカード番号」などの個人データを域外に移転することを原則禁止しています。EU域内でビジネスを行い、EU域内にいる個人の個人データを取得する日本企業に対しても、幅広く適用されます。
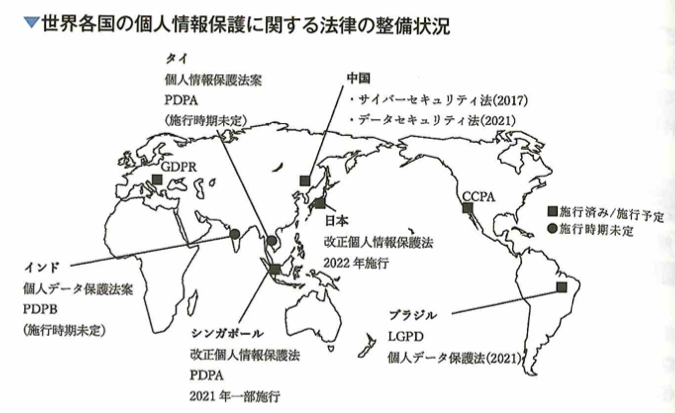
企業のグローバル化に伴い、データ取得の適法性についても、グローバルな視点で検討する必要性が高まっています。中でも、EU一般データ保護規則(GDPR)は、規制範囲が広く、罰則も重いため、AI開発におけるデータ取得時には特に留意する必要があります。EU一般データ保護規則(GDPR)は、EUを含む欧州経済領域内にいる個人の個人データを保護するためのEUにおける統一的ルールであり、域内で取得した「氏名」や「クレジットカード番号」などの個人データを域外に移転することを原則禁止しています。EU域内でビジネスを行い、EU域内にいる個人の個人データを取得する(日本企業)に対しても、幅広く適用されます。
GDPR(General Data Protection Regulation:一般データ保護規則)の適用は、EU域内にいる個人の個人データを取得するなら、上場企業かIT企業かに関係なく、日本企業も対象になります。ESGとは、Environment(環境)、Social(社会)、Governance(企業統治)の3つの言葉の頭文字を取ったもの、IEEEとは、米国に本部を持つ電気・電子技術に関する学会のことです。 また、EUのGDPR以外にも、世界各国で個人情報保護に関する法律が整備されてきています。
個人情報保護法
金融分野における個人情報取扱事業者がデータを取得する場合の機微情報には、人種、信条、病歴、犯罪の経歴などの個人情報保護法に定める「要配慮個人情報」にとどまらず、労働組合への加盟や保健医療などのデータも含まれます。機微情報は、取得・利用または第三者提供のすべてが原則禁止とされ、個人情報保護法の「要配慮個人情報」よりも厳しい取扱いが要求されています。
AI開発の場合も含め、個人に関するデータの取得・利用等の際には、プライバシーに対する注意が必要です。
AI学習用セットを生成する際の著作権
AI学習用データセットを生成する際にもとのなるデータに第三者の著作物が含まれている場合について考えます。元となるデータの利用に、原則として著作権社の承諾は必要ありません。
他人の著作権者は、第三者に著作権があるデータ利用について、著作権者の許諾を得なくても解釈が可能としています。そして、営利目的の解析にも適用される点も、諸外国の規定よりも適用範囲が広いとされていましたが、平成30年の法改正により、その適用範囲はさらに広くなりました。このような、AI開発用データセット作成に配慮した法規制については、出題可能性も高いと考えられます。
第三者の著作物を利用する場合には、原則として、著作権者の承諾が必要とされます。しかし、著作権法第30条の4第2号は、情報解析のために行われるデータ利用についての権利制限を定めています。つまり、AI開発用データセットを作成する場合、もとのなるデータ等の著作権者の承諾は原則として必要とされません。著作権法第30条の4第2号は、非営利目的の場合に限っていないため、インターネット上に公開されているデータを利用して学習用データセットを作成して、販売する行為は違法とはなりません。著作権法のデータについて、サーバの設置場所で利用していると考えられる、とされ日本国内で作業していても、国外にあるサーバを利用して開発行為を行う場合には、日本の法律は適用されないと考えることになります。著作権法上問題がなくても、不正競争防止法、個人情報保護法、ライセンス契約、通信の秘密などによっても、データの利用に制約がかかっている場合があります。たとえば、営業秘密や限定提供データについては、不正競争防止法によって、データの不正使用を禁止されています。営業秘密として保護されるための条件として「秘密管理性」とありますが、これは「保有者が秘密とするということについての意思を持つ」だけではなく、「秘密を維持するために合理的な努力を払い、不正行為以外では不特定者に知られないように秘密として管理が行われていること」を意味します。たとえば、紙媒体であれば、当該文書に「マル秘」など秘密であることを表示することにより、秘密管理意思に対する従業員の認識可能性を確保するような措置を講じることなどが必要です。
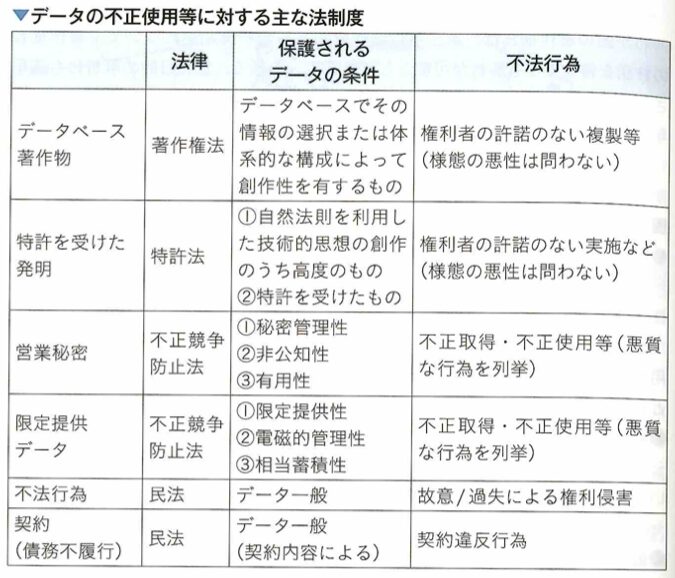
匿名加工情報
AIの学習やデータ分析を行うなどデータを活用する機会が増え、個人情報の保護の重要性も増しています。次のうち匿名加工情報(個人情報を加工することで特定の個人を識別することができないようにし、当該個人情報を復元不可能にした情報)に関する事業者の義務について、匿名加工情報の作成や第三者提供を行なった際などには、公表する必要があります。
氏名や個人識別符号の削除など、匿名加工情報を制作する事業者は、個人情報を適切に加工する必要があります。匿名加工情報を制作する事業者は、加工方法などの情報の漏洩防止などの安全管理措置を行う必要があります。匿名加工情報を扱う際に、作成元の個人情報を識別するような行為は禁止されています。
個人情報保護法第2条第6項(匿名加工情報の定義)
この法律において「匿名加工情報」とは、次の各号に掲げる個人情報の区分に応じて当該各号に定める措置を講じて特定の個人を識別することができないように個人情報を加工して得られる個人に関する情報であって、当該個人情報を復元することができないようにしたものをいう。
第1項第1号に該当する個人情報 当該個人情報に含まれる記述等の一部を削除すること(当該一部の記述等を復元することのできる規則性を有しない方法により他の記述等に置き換えることを含む。)
第1項第2号に該当する個人情報 当該個人情報に含まれる個人識別符号の全部を削除すること(当該個人識別符号を復元することのできる規則性を有しない方法により他の記述等に置き換えることを含む。)
独占禁止法
「消費者と事業者との間の情報の質および量ならびに交渉力の格差」が存在しており、消費者は事業者との取引において取引条件が一方的に不利になりやすいです。デジタル・プラットフォーム事業者は、自己の取引上の地位が取引の相手方である消費者に優越している場合、その地位を利用して、正常な商習慣に照らして不当に不利益を与えることは、当該取引の相手方である消費者の自由かつ自主的な判断による取引を妨害する一方で、デジタル・プラットフォーム事業者は、その競争者との関係において競争上有利となります。消費者がデジタル・プラットフォーム事業者から不利益な取扱いを受けても、消費者が当該デジタル・プラットフォーム事業者の提供するサービスを利用するためには、これを受け入れざるを得なくなります。このような場合であるかどうかの判断に当たっては、消費者にとっての当該デジタル・プラットフォーム事業者と「取引することの必要性」を考慮します。
通常、当該サービスを提供するデジタル・プラットフォーム事業者は、消費者に対して取引上の地位が優越していると認められるものは、当該サービスと代替可能なサービスを提供するデジタル・プラットフォーム事業者が存在しない場合。代替可能なサービスを提供するデジタル・プラットフォーム事業者が存在していたとしても当該サービスの利用をやめることが事実上困難な場合です。反対に認められないものは、当該サービスにおいて、当該サービスを提供するデジタル・プラットフォーム事業者の利用者数が一定水準よりも多い場合です。
上の2つの例は公正取引委員会の「デジタル・プラットフォーム事業者と個人情報等を提供する消費者との取引における優越的地位の濫用に関する独占禁止法上の考え方」の3の(2)に記載されており、通常、当該サービスを提供するデジタル・プラットフォーム事業者は、消費者に対して取引上の地位が優越していると認められるものです。他にも「当該サービスにおいて、当該サービスを提供するデジタル・プラットフォーム事業者が、その意思で、ある程度自由に、価格、品質、数量、その他の各種取引条件を左右することができる地位にある場合」も該当します。一方で、利用者数だけは消費者に対して優越しているかの判断ができないので、最後の例は誤りになります。
改正道路交通法と改正航空法について考えます。今後ドライバー不足等が懸念される日本において、自動運転技術による移動サービスや、ドローンによるラストマイル輸送(大型トラックなどでは難しい住宅街等への配送)などが注目されています。本コラムでは、2022年施行の最新のモビリティ政策動向として、改正道路交通法と改正航空法について紹介します。 2022年には、モビリティ関連の2つの法律が改正・施行される見込みです。一つは、2022年4月に閣議決定された、道路交通法の改正です。今回の改正では、自動運転車を使った移動サービスの社会実装を主な対象として、特定の条件下では人間の運転への介入が必要とされない自動運転レベル4が解禁される見通しとなっています(図1)。レベル3以下の自動運転システムはドライバーの運転操作への介入を前提としていますが、レベル4以上の自動運転システムにおいては、システムが運転操作をすべて担当するため、人間の介入を必要としません。ただし、レベル4車両は特定道路などの特定条件下においてのみ走行します。 また、ドローンの飛行規制に関連して、「航空法等の一部を改正する法律(以後、改正航空法)」が成立し、2021年6月に公布されました。改正航空法は2022年12月に施行を控えており、第三者上空の視界飛行(有人地帯での補助なし飛行=レベル4飛行)の実現に向けて制度や規制の整備が進められています(図1)。レベル4での飛行は、①国から機体認証を受けた機体を、②操縦ライセンスを有するものが操縦し、③国土交通大臣の許可・承認を得た場合に、新たに可能となります。 なお、国土交通省は、概ね10年後の日本社会を念頭に、道路政策を通じて実現を目指す社会像、その実現に向けた中長期的な政策の方向性を提案する「2040年、道路の景色が変わる~人々の幸せにつながる道路へ~」を公表しています。その中では、道路やモビリティのビジョンが詳細に示されており、完全自動運転車や有人地帯でのドローンの飛行が、10年後の社会を支える重要な基盤であることがわかります(図2)。こうした流れの中で、今回紹介するような法改正が行われていることを頭に入れておけば、今後行われる新たなモビリティ関連の法改正についても理解を深めるきっかけになるでしょう。

最後に用語の解説です。Kaggleとはデータサイエンスのコンペティションプラットフォームで世界中のデータサイエンティストが自身のモデルの精度などで競われています。さまざまなデータに対する解法や考察なども存在し、閲覧できます。Couseraは機械学習などの分野をオンラインで学ぶことができる教育プラットフォームです。MOOCsはCouseraのような大規模なオンライン講座群のことで、Massive Open Online Coursesの略です。arXivとは機械学習などの論文をアップロード・ダウンロードすることができるプラットフォームで、最新の研究などの情報を閲覧できます。XAIとは介錯性の高い説明可能なAIのことです。米国のDARPA(Defence Advanced Reserch Projects Agency:国防高騰研究計画局)が主導する研究プロジェクトが発端となり、XAI(Explanable AI)と呼ばれます。匿名加工情報とは、個人情報を加工することで特定の個人を識別することができないようにし、当該個人情報を復元不可にした情報です。
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
データサイエンティストはデータ分析やAIの専門家で、データエンジニアはシステムにおいてデータの管理を担います。CRISP-DMはAIに限らずデータ分析を活用するプロジェクトを推進するための標準的なフレームワークです。ビジネス理解→データ理解→データ準備→モデル構築→評価→展開の順です。AI活用に特有な工程を加味したものをCRISP-MLと言います。MLOPsはMacine Leaning(機械学習)+Operations(運用)です。エッジはAIを利用する現場に設置された機器類を指す言葉です。GUI(Graphical User Interface)はコンピュータ操作を視覚的に行うための操作体系です。デザイナーはステークホルダーのニーズを把握することが役割ではありません。
機械学習モデルのデータ開発やデータ分析で最もよく使用されるプログラミング言語はPythonです。Jupyter NotebookはPINBOKのコード編集や実行をブラウザから手軽に行えるツールです。環境が異なると、予期しない挙動などが考えられます。Dockerはコンテナ型仮想化という技術を用いてOS reberukara環境の一貫性を保つツールです。PyenvはPythonやそのライブラリのバージョンを保つツールですが、コンテナ型仮想化の技術はありません。メタデータとは、データ自体に関する情報を著したデータのとおりです。バリデーションは検証データを使用してモデルの性能を評価することです。
教師あり学習におけるデータリーケージとは利用できないデータが訓練データに混入することです。特に混入したデータが予測に有利な情報を含んでいた場合は、モデルの性能が不当に高く評価されてしまいます。つまり過学習や未学習への影響はありません。オープンデータセットの例としてImageNetがあります。画像に写っている物体のクラスが正解ラベルとして与えられており、画像分類のタスクに用いることができます。WordNetやDBPediaは自然言語処理タスクの学習に利用するオープンデータセットで、LibriSpeechは音声処理タスクの学習に利用できます。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
NDAはプロジェクトを開始する前に締結する、第三者への情報の漏洩または不正利用を防止するための契約です。AI・データ利用に関する契約ガイドラインは経済産業省によるガイドラインで、探索的段階型のソフトウェア開発方式が推奨されます。開発のプロセスを、アセスメント→PoC→開発→追加学習に分けています。アジャイル開発は、計画→設計→実装→テストといった開発工程を小さい機能単位に分割し、機能単位ごとにサイクル(インテレーション)を繰り返す開発様式です。各機能の集合体としてシステム全体を構築します。
DX(デジタルトランスフォーメーション)は、事業のあり方、ビジネスモデルやサービス形態の根本的かつ大局的なデジタルによる変容を目指す概念です。オープンイノベーションは、製品、サービス、技術の開発や組織改革などにおいて、社外の組織から知識や技術を取得し社内に取り込むことで、自前主義からの脱却を図ります。ビッグデータとは、生成速度と更新速度が非常に速い大規模データです。Volume、Variety、Velocityです。ビッグデータのうち非構造化データは構造化データより発生頻度が高いです。IoTは身の回りのものをインターネットに接続することで、データが生成され、そのデータを分析などに利用できることです。RPAはコンピュータやソフトウェアロボットを通して事務的な作業を自動化、効率化することです。生産性向上、工数削減、誤作動防止などが期待できます。
BIはノンプログラミングで多角的にデータを集約、整理し、可視化することでビジネスに有益な情報を抽出するのに使うソフトウェアツールです。エッジAIはシステムの端末に位置するデバイスに直接搭載し、そのデバイスの上で実行されるAIです。CRISP-DMは様々な業界で適用可能なデータマイニングの方法論です。ビジネスの理解、データの理解、データの準備、モデルの選択と作成、評価・見直し・次のステップの計画、本番環境への展開の6つのフェーズから構成されます。APIはソフトウェアやプログラムの一部を公開し、他のコンピュータやソフトウェアと機能を共有するためのインターフェイスです。
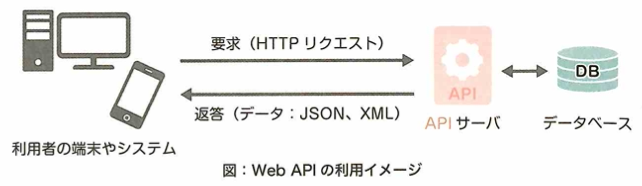
ブロックチェーンは、中央管理者を必要としない自律分散システムで分散的に管理された複数のコンピュータをネットワークに接続し、暗号化されたデータのコピーを全端末で共有する仕組みです。システムの可用性と完全性が保たれやすいです。Dockerは開発者やシステム管理者がコンテナ(仮想的なユーザ空間)という単位でアプリケーションを構築、実行、共有するためのプラットフォームです。コンテナ型仮想化と呼ばれる技術が使用されます。
設計、計画の段階から法的、倫理的な課題を検討する法務担当者が必要です。ビジネスの観点も考慮してプロジェクト全体の意思決定を行い、進行の管理を行うプロジェクトマネージャーが必要です。利用者の観点からシステムまたは、アプリケーションのUI(User Interface)とUX(User Experience)の設計について検討するデザイナーが必要です。データサイエンティストは、データ収集、データ加工、モデル学習、システム実装、性能評価テストなどを行います。
受注側は、契約で定められた義務を果たした時点ではじめて、報酬を発注側に請求できます。この義務は形態によって異なります。準委任契約では業務を行うことが義務です。請負契約では成果物を納品することが義務です。
AIの場合は、成果物の性能を保証するのが難しいので、準委託契約が推奨されます。受注側が委託先にデータを提供し、委託先が学習用プログラムを設計します。委託先が学習用データセットを作成し、委託先が学習用プログラムに学習用データセットを入力し、学習済みモデルを生成します。委託先が学習済みモデルにテスト用データを入力して性能を検証し、その結果を受注側と共に検討します。探索的段階型の開発方式はAI開発の特性を考慮し、従来型のソフトウェア開発とは違った開発方式として、経産省の「AI・データの利用に関する契約ガイドライン」で推奨されています。探索的段階型のフローは、アセスメント→PoC→開発→追加学習です。PoCの段階では、開発者が生データから学習用データセットを作成し、発注側が求める精度を満たす学習済みモデルを生成できるかを検証します。リスクを最小化するためにPoCを取り入れて探索的段階型方式を採用して契約を結びます。
秘密保持契約はプロジェクトを開始する前に結びます。NDAには秘密情報を開示または漏洩した場合の損害賠償の条項が規定されています。違反すると、損害賠償請求や差止請求(秘密情報の受領側がこれ以上秘密情報を利用できないようにする請求)などNDAに記載されている措置がとられる可能性があります。複製を禁止する条項が設定されていない限り、受領がわは秘密情報を自由に複製できます。PoCの段階ではすでに秘密情報のやり取りを行なっていることが多いです。AIプロジェクトを社外と共同で進める際も、プロジェクトの具体的な内容やデータを共有する前にNDAを締結すべきです。
PoSはPont of Salesの略で、販売時点を意味します。PoSデータは販売実績データとなり、エクセルファイルやSQL型データベースに構造化データとして保存されます。センサーデータはセンサーが感知した現象や状態が何らなかの信号や信号を連ねたログに変換されたデータを指します。加工して表形式の構造化データに変換することは可能ですが、最初から構造化データであることは稀です。

ビッグデータは生成される素億度と更新される速度が非常に速い大規模データです。構造化データでもデータ量が膨大であればビッグデータです。IoTは身の回りのものをインターネットに接続し、データが生成され、そのデータを分析などに利用できることです。MLOpsはAIプロジェクトにおいてモデルを開発する側と運用する側が円滑に連携し、モデル開発から運用までの一連を管理する体制です。
RPAはコンピュータやソフトウェアロボットを通じて事務作業を効率化することです。仮想知的労働者と言われます。受発注処理、在庫管理など自動化できる業務に使用できます。しかしメールの内容を解析する自然言語処理やその状況に応じて次の行動を選択するのは範囲を超えています。
DXを支える技術は、IoT、AI、RPA、ビッグデータの活用に必要な技術全般などです。クラウド技術の寄与により、専門性の高い技術や大規模リソースを持たなくても高度な開発が可能で、事業の新規参入の障壁が低くなりました。IT化は既存業務の業務プロセスの効率化が目標で、DXはより根本的かつ対局的なスケールで事業のあり方、ビジネスモデルやサービス形態の変容を目指します。
Pythonはオープンソースです。BIツールはプログラミングなしに、ほぼマウス操作だけで多角的にデータを収集、整理し、可視化することで、ビジネスに有益な情報を抽出する便利なツールです。TableauはBIツールのソフトウェアの一種です。TensorFlowやSciPyはプログラミング言語でなく、Pythonのライブラリやフレームワークです。MatplotlibはPythonの可視化用のライブラリで、プログラミングを通して使用する必要があります。Power BIも代表的なBIツールです。
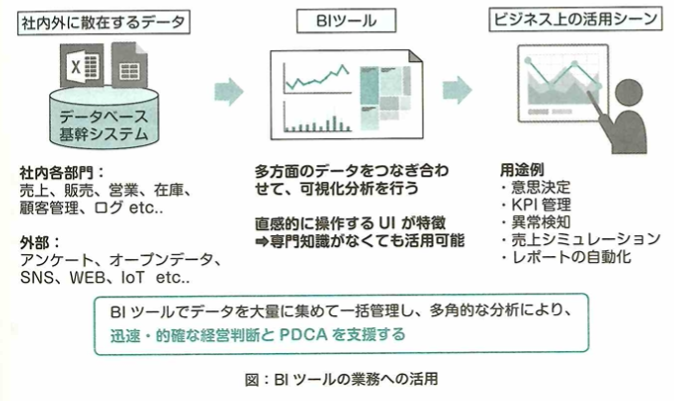
Pythonにおいてライブラリを活用すると、シンプルなコードを書くだけで驚くほど高度な機能を実装できます。Matplotlibはデータ可視化のためのライブラリで、様々なグラフを作れます。TensorFlowやそのラッパーであるKeras、PyTorch、Chainerなどは深層学習を実装するためのライブラリです。ラッパーは、ソフトウェアやプログラムが提供するクラスや関数などを、本来とは異なる環境や方法で利用可能にしたものです。ライブラリは、元からPythonに付属している標準ライブラリと別途インストールする外部ライブラリがあります。標準ライブラリは日付データやファイル操作などを、外部ライブラリは専門性の高い機能を提供するライブラリです。NumPy、Pandas、Matplotlibは外部ライブラリです。外部ライブラリはウェブからダウンロードしますが、例外がありPythonのディストリビューション(配布用ソフトウェア)の1つであるAnacondaを介してPythonを導入する場合、よく使用される外部ライブラリもパッケージ化した状態で同時導入できます。NumPyは多次元配列データを高速に演算することを得意とします。画像データは画素の値が大量に並んだ多次元の配列データとみなせます。画像認識モデルの訓練は膨大な量の画像データが必要ですが、NumPyを用いると比較的早くこれらの画像データを処理できます。Pandasはデータ分析で使用される表形式データを柔軟に処理する機能が揃っています。例えば欠損値の処理に適しています。データ表同士でも様々な統計処理を行う関数を提供しています。
MLOps(開発と運用が同じ担当者である必要はありません)により学習済みモデルを本番環境に展開した運用期間中にもデータを追加して再学習を行なってアップデートや改善を行いやすくなります。DevOpsを機械学習モデルの開発に応用した考えです。AutoMLは機械学習モデルの開発プロセスを自動化する仕組みまたはツールです。
CRISP -DMはデータマイニングの標準プロセスです。ビジネス理解→データ理解→データ準備→手法の選択・モデル作成→結果の評価・プロセスの見直し・次のステップの計画→本番環境への展開です。必要に応じて前のステップに戻る、ステップ間を行き来することがあります。サイクルを複数回実施することもあります。
APIはソフトウェアやアプリケーションの間で機能の一部を共有する技術です。HTTPなどWeb技術を利用したAPIをWeb APIと言います。利用者は、APIのサーバにリクエストを送り、それに対して応答が返ってくることで、プログラムの機能が利用できます。Web APIは無償のものと有償のものがあります。有償であっても、総合的には全ての機能を自前で開発するようりは安価であることが多いです。

アプリケーションの機能は、提供されるAPIの機能や仕様に依存します。APIの機能や仕様が変わるとそれを利用したアプリケーションも修正が必要です。APIのサービス停止やシステム障害の影響も受けます。APIを用いた場合に比べ、自ら実装する方が、柔軟な対応は可能であり、カスタマイズ性は高いです。
PaaSはアプリケーションが稼働するプラットフォームを提供するクラウドサービスです。IaaSの例として、Amazon Web Services(AWS)、Google Cloud、Microsoft Azure、IBM Cloud、Oracle Cloudなどがあります。オンプレミス(自社環境)は、必要な設備の購入やシステム構築と運用管理を全て自社で行う必要がありますが、柔軟性が高いです。最近はクラウドと併用したハイブリッド環境もあります。
ブロックチェーンは分散的に管理されたコンピュータをネットワークに接続し、暗号化された同一データのコピーを全端末で共有します。データを保護しながら取引を行うための有効手段です。ハッシュや電子署名などの暗号技術を用いるのでデータの改竄を監視し検出できるようになっています。デジタル空間でデータが不正に改竄されないように担保することを完全性と言います。ネットワークの一部に不都合が発生しても、システム全体がダウンすることなく運用を継続できることを可用性と言います。
Dockerはアプリケーションとその実行に必要な環境をコンテナという単位でパッケージ化する技術です。この技術をコンテナ型仮想化と言います。OS上でコンテナ(アプリケーションを実行するためのリソースが提供される仮想空間)を構成します。コンテナごとに構築、実行、共有できます。コンテナはOSレベル以上のソフトウェア層のみを仮想化して任意のマシンにデプロイして使用します。仮想マシンはハードウェア層まで含めたマシン全体を仮想化しているので物理マシンのデジタルコピーと解釈されます。独自のOSを備えた複数の仮想マシンが同じホストマシン上で実行されます。
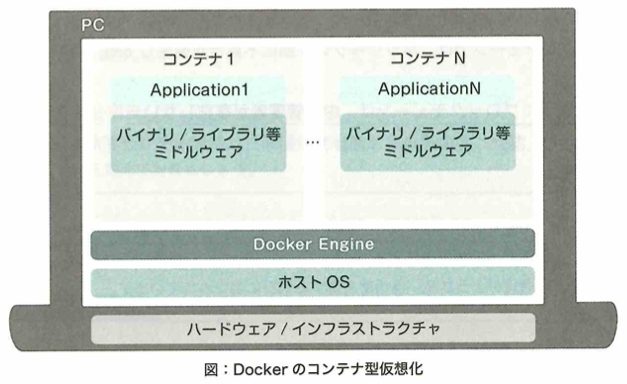
コンテナ型仮想化の場合はOSレベルでの仮想化を行うので1台の物理的なマシン上で複数の仮想的なユーザ空間(コンテナ)を設けることができます。開発プロジェクトごとに異なる仮想環境のコンテナを使い分け、1台のサーバの上で複数のアプリケーションを稼働にすることができます。Dockerのコンテナを利用することで、開発のための環境構築のコストが削減されます。アプリケーションを動かすのに必要な全ての要素が1つのコンテナにまとめられていて、このコンテナをホストマシンにデプロイするだけのためです。アプリケーションを動かす全ての要素はDockerイメージ(コンテナイメージ)としてパッケージ化されます。具体的にはDockerファイルというテキストファイルに記述するだけです。これを任意のマシン(Ubuntuなど)の中で起動して実行します。Docker Hubというレジストリを介して、多くの開発者が自分が作ったアプリケーションのDodkerイメージを他のDockerユーザと共有できます。公開されたDockerイメージを利用すれば、アプリケーションの開発・実行のための仮想環境を、短時間・低コストで構築できます。変更したい部分だけに処理を加えれば良いからです。
分析の目的と明確なKPIについて依頼元と分析担当者で意識の相違がないことが大事です。データの全体が分析の目的やクライアントが知りたいことに関連するとは限らないので、総当たりで分析するのは非効率です。まずは目的に関与するデータから特定すべきです。一般的な教養範囲はなく、案件の要件として発注者と相談し決めるものです。従って先方は何%の予測のずれまでが許容範囲かを確認すべきです。時系列データに対する予測モデルは時間が経つと、実データのトレンドが徐々に変化し、納品当時に精度が検証されたモデルでも精度が少しずつずれ始めるのは珍しくはありません。そのため開発当時の精度検証の経緯に必要以上に固執することは好ましくありません。
データを扱う上で倫理的な行動を取るべきです。AI倫理に関する取り組みの1つは、公平性・説明責任・透明性です。AI倫理の重要項目の1つは、AIシステムが利用者の行動に与える影響を明らかにすることです。表示内容や推奨記事を通して、ユーザの意思表示や判断が影響される可能性があるので、そのことをユーザに伝える必要があります。AIの公平性の観点からデータバイアスやアルゴリズムバイアスを排除する工夫を行う必要があります。
以下では赤本『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』に載っていない章についての解説になります。
AIに必要な数理・統計知識
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
自己情報量は確率的に発生するある事象が持つ情報の大きさを定式化した値です。起きる確率が低い事象ほど大きな値を取ります。1つの確率変数の実現値から計算します。相互情報量は2つの確率変数から計算され、どちらか一方を知ることでもう一方の情報がどれほど得られるかを表します。最小二乗法は線形回帰において用いられるパラメータ最適化の手法で、ロジスティック回帰におけるパラメータは最尤法と勾配降下法を組み合わせて最適化します。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
相互情報量は、情報理論の概念で、2つの確率変数の関連性の強さ(相互依存性)を表します。2つの確率変数の相互依存性が小さいほど相互情報量は小さくなります。
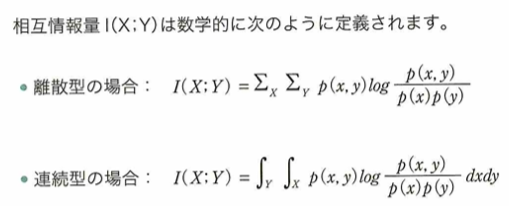
XとYが独立の時に、相互情報量は0となります。
標本誤差とは、母集団の真の値(母数)と標本調査を通して推定した統計量(母数の推定値)の値の差異のことです。ほとんどの場合、真の値がわからないので、その時は標本誤差のおおよその範囲を判断するために、標準誤差を用います。

二項分布は2通りの結果しかない互いに独立したベルヌーイ試行をn回実施した時に、ある事象が何回起こるかを示した確率分布です。サイコロの出る目は6通りなので二項分布にはなりません。
Xがポアソン分布に従う時、1時間に4回起きるイベントがあり、10分以内に1回起こる確率を求めます。この時にλは60分に4回と考えて10分間の場合に変換して考えますと、λは4×1/6=0.66‥です。k=1をポアソン分布の式に代入して、約0.34になります。
アダマール積とは、縦横が同じ形の行列に置いて、成分ごとに積を取った結果を成分とする行列です。アダマール積は機械学習のための配列型データの前処理などに使われます。
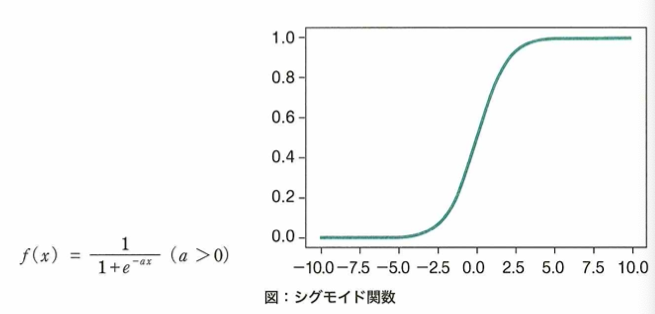
畳み込み演算では、ストライドの値に注意しましょう!
AIに関する法律と契約
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
データを利用する際は個人情報保護法を遵守します。個人情報を扱う際はその目的を本人に通知し公表する必要があります。個人識別符号とはそれ自体から特定の個人を識別できる情報です。指紋データや旅客権などは該当し、個人情報保護法における個人情報として保護されます。要配慮個人情報は不当な差別や偏見が生じないようにする特別な配慮を要する個人情報を言います。個人データとは個人情報データベース等を構成する個人情報です。個人情報データベース等は、特定の個人情報を容易に検索できるよう整備されたものです。個人データのうち個人情報取扱業者が開示や第三者への提供の停止などを行う権限を有するものを、保有個人データと言います。委託を受けて取り扱う個人データは、委託先と開示などの特別な取り決めをしていない場合、保有個人データに該当しません。加工された情報は、その性質によって仮名加工情報と匿名加工情報に分かれます。仮名加工情報とは、個人情報に含まれる記述の一部に削除などの加工を施すことで、他の情報と照合しない限り特定の個人を識別できないようにした情報です。匿名加工情報とは、個人情報に含まれる記述の一部に削除などの加工を施すことで、特定の個人を識別できないようにした情報です。仮名性より匿名性の方が秘匿性が高いです。
GLUEは自然言語処理において複数タスクを対象とするモデルの精度評価を行うベンチマークです。生成AIの自律的な聖生物は人間の「思想又は感情」を表現したものではないので、その生成物は生成者の著作物には該当しません。入力データなどに創意工夫が見られる場合、思想又は感情を創作的に表現したとみなされる場合もあります。営利目的では著作権者に無断で使用できます。作者の画風や世界観などは著作権保護の対象となりません。著作物の創作的表現が聖生物に残っているかが大事です。断片的にでも残っている場合は、著作権侵害になり得ます。つまり生成AIによる生生物に著作権が認められるかは、「創作意図」と「創作的寄与」の有無によって判断されます。
知的財産とは知的活動によって生み出されるアイデアや著作物、営業秘密などをさい、知的財産権による保護の対象となります。発明について、学習用データセットは、情報の単なる定時に該当するとされ、発明とは認められません。不正競争防止法における営業秘密は、非公知性、有用性、秘密管理性の3つの要件を満たす情報です。発明が特許を受けるには、新規制、進歩性を有している必要があります。職務発明では、職務発明制度という特則があります。特許法では、プログラムが発明の対象物として認められています。発明は特許を取得することで特許権による保護を受けられます。特許法における発明は、知的財産基本法における知的財産として定義されます。
限定提供データとは、データを不正競争防止法のもとで保護する概念です。営業秘密に該当しないものを一定の条件を満たすものを限定提供データとすることで実現できます。
公正競争阻害性とは、公正な競争秩序に悪影響を及ぼす可能性を指します。例えばAI予測を偏らせるように意図的にAIを学習させるといったプラットフォーム提供者の行為により、ユーザーに不当な格差が生まれる場合があります。
AI・データの利用に関する契約ガイドラインについて、AIの開発プロセスをアセスメント(NDA(秘密保持契約)を結ぶ)、PoC、開発、追加学習の4段階に分類し、それぞれにおいて個別に契約を結ぶことを提唱しています。
AIに関連したソフトウェア開発における成果物の知的財産権について学習用データセットや学習済みモデルといった成果物の知的財産権の帰属が問題となります。ベンダーとユーザーの間で成果物の知的財産権の帰属に関する契約を締結することで、トラブルを未然に防げます。複雑な利用条件を設定する際は、別途ライセンス契約(使用許諾契約)を締結することもあります。
請負契約は、具体的な仕事の完成を目的とした契約です。成果物の納品が義務です。準委任契約は検証や開発といった役務の提供を目的とする契約です。AI開発でも準委任契約を用います。準委任契約は、成果完成型と履行割合型に分けられます。前者は、委任事務の処理によってもたらされる成果に対して報酬を支払い、後者はこのような合意がない場合の支払い方式です。寄託契約は、他人のものを保管する役割を目的とする契約です。
SaaSはインターネット経由でアプリケーション機能を提供するサービスです。利用規約によって、サービスの利用条件を定めます。PaaSはアプリケーションの運用や維持管理を行うプラットフォームです。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習の次は、別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習を行い更なる得点力の向上を目指します。
NDAはプロジェクトを開始する前に締結する、第三者への情報の漏洩または不正利用を防止するための契約です。AI・データ利用に関する契約ガイドラインは経済産業省によるガイドラインで、探索的段階型のソフトウェア開発方式が推奨されます。開発のプロセスを、アセスメント→PoC→開発→追加学習に分けています。アジャイル開発は、計画→設計→実装→テストといった開発工程を小さい機能単位に分割し、機能単位ごとにサイクル(インテレーション)を繰り返す開発様式です。各機能の集合体としてシステム全体を構築します。
DX(デジタルトランスフォーメーション)は、事業のあり方、ビジネスモデルやサービス形態の根本的かつ大局的なデジタルによる変容を目指す概念です。オープンイノベーションは、製品、サービス、技術の開発や組織改革などにおいて、社外の組織から知識や技術を取得し社内に取り込むことで、自前主義からの脱却を図ります。ビッグデータとは、生成速度と更新速度が非常に速い大規模データです。Volume、Variety、Velocityです。ビッグデータのうち非構造化データは構造化データより発生頻度が高いです。IoTは身の回りのものをインターネットに接続することで、データが生成され、そのデータを分析などに利用できることです。RPAはコンピュータやソフトウェアロボットを通して事務的な作業を自動化、効率化することです。生産性向上、工数削減、誤作動防止などが期待できます。
BIはノンプログラミングで多角的にデータを集約、整理し、可視化することでビジネスに有益な情報を抽出するのに使うソフトウェアツールです。エッジAIはシステムの端末に位置するデバイスに直接搭載し、そのデバイスの上で実行されるAIです。CRISP-DMは様々な業界で適用可能なデータマイニングの方法論です。ビジネスの理解、データの理解、データの準備、モデルの選択と作成、評価・見直し・次のステップの計画、本番環境への展開の6つのフェーズから構成されます。APIはソフトウェアやプログラムの一部を公開し、他のコンピュータやソフトウェアと機能を共有するためのインターフェイスです。
ブロックチェーンは、中央管理者を必要としない自律分散システムで分散的に管理された複数のコンピュータをネットワークに接続し、暗号化されたデータのコピーを全端末で共有する仕組みです。システムの可用性と完全性が保たれやすいです。Dockerは開発者やシステム管理者がコンテナ(仮想的なユーザ空間)という単位でアプリケーションを構築、実行、共有するためのプラットフォームです。コンテナ型仮想化と呼ばれる技術が使用されます。
設計、計画の段階から法的、倫理的な課題を検討する法務担当者が必要です。ビジネスの観点も考慮してプロジェクト全体の意思決定を行い、進行の管理を行うプロジェクトマネージャーが必要です。利用者の観点からシステムまたは、アプリケーションのUI(User Interface)とUX(User Experience)の設計について検討するデザイナーが必要です。データサイエンティストは、データ収集、データ加工、モデル学習、システム実装、性能評価テストなどを行います。
受注側は、契約で定められた義務を果たした時点ではじめて、報酬を発注側に請求できます。この義務は形態によって異なります。準委任契約では業務を行うことが義務です。請負契約では成果物を納品することが義務です。
AIの場合は、成果物の性能を保証するのが難しいので、準委託契約が推奨されます。受注側が委託先にデータを提供し、委託先が学習用プログラムを設計します。委託先が学習用データセットを作成し、委託先が学習用プログラムに学習用データセットを入寮駆使、学習済みモデルを生成します。委託先が学習済みモデルにテスト用データを入力して性能を検証し。その結果を受注側と共に検討します。探索的段階型の開発方式はAI開発の特性を考慮し、従来型のソフトウェア開発とは違った開発方式として、経産省の「AI・データの利用に関する契約ガイドライン」で推奨されています。探索的段階型のフローは、アセスメント→PoC→開発→追加学習です。PoCの段階では、開発者が生データから学習用データセットを作成し、発注側が求める制度を満たす学習済みモデルを生成できるかを検証します。リスクを最小化するためにPoCを取り入れて探索的段階型方式を採用して契約を結びます。
秘密保持契約はプロジェクトを開始する前に結びます。NDAには秘密情報を開示または漏洩した場合の損害賠償の条項が規定されています。違反すると、損害賠償請求や差止請求(秘密情報の受領側がこれ以上秘密情報を利用できないようにする請求)などNDAに記載されている措置がとられる可能性があります。複製を禁止する条項が設定されていない限り、受領側は秘密情報を自由に複製できます。PoCの段階ではすでに秘密情報のやり取りを行なっていることが多いです。AIプロジェクトを社外と共同で進める際も、プロジェクトの具体的な内容やデータを共有する前にNDAを締結すべきです。
PoSはPont of Salesの略で、販売時点を意味します。PoSデータは販売実績データとなり、エクセルファイルやSQL型データベースに構造化データとして保存されます。センサーデータはセンサーが完治した現象や状態が何らなかの信号や信号を連ねたログに変換されたデータを指します。加工して表形式の構造化データに変換することは可能ですが、最初から構造化データであることは稀です。
ビッグデータは生成される素億度と更新される速度が非常にはやい大規模データです。構造化データでもデータ量が膨大であればビッグデータです。IoTは身の回りのものをインターネットに接続し、データが生成され、そのデータを分析などに利用できることです。MLOpsはAIプロジェクトにおいてモデルを開発する側と運用する側が円滑に連携し、モデル開発から運用までの一連を管理する体制です。
RPAはコンピュータやソフトウェアロボットを通じて事務作業を効率化することです。仮想知的労働者と言われます。受発注処理、在庫管理など自動化できる業務に使用できます。しかしメールの内容を解析する自然言語処理やその状況に応じて次の行動を選択するのは範囲を超えています。
DXを支える技術は、IoT、AI、RPA、ビッグデータの活用に必要な技術全般などです。クラウド技術の寄与により、専門性の高い技術や大規模リソースを持たなくても高度な開発が可能で、事業の新規参入の障壁が低くなりました。IT化は既存業務の業務プロセスの効率化が目標で、DXはより根本的かつ対局的なスケールで事業のあり方、ビジネスモデルやサービス形態の変容を目指します。
Pythonはオープンソースです。BIツールはプログラミングなしに、ほぼマウス操作だけで多角的にデータを収集、整理し、可視化することで、ビジネスに有益な情報を抽出する便利なツールです。TableauはBIツールのソフトウェアの一種です。TensorFlowやSciPyはプログラミング言語でなく、Pythonのライブラリやフレームワークです。MatplotlibはPythonの可視化用のライブラリで、プログラミングを通して使用する必要があります。Power BIも代表的なBIツールです。
Pythonにおいてライブラリを活用すると、シンプルなコードを書くだけで驚くほど高度な機能を実装できます。Matplotlibはデータ可視化のためのライブラリで、様々なグラフを作れます。TensorFlowやそのラッパーであるKeras、PyTorch、Chainerなどは深層学習を実装するためのライブラリです。ラッパーは、ソフトウェアやプログラムが提供するクラスや関数などを、本来とは異なる環境や方法で利用可能にしたものです。ライブラリは、元からPythonに付属している標準ライブラリと別途インストールする外部ライブラリがあります。標準ライブラリは日付データやファイル操作などを、外部ライブラリは専門性の高い機能を提供するライブラリです。NumPy、Pandas、Matplotlibは外部ライブラリです。外部ライブラリはウェブからダウンロードしますが、例外がありPythonのディストリビューション(配布用ソフトウェア)の1つであるAnacondaを介してPythonを導入する場合、よく使用される外部ライブラリもパッケージ化した状態で同時導入できます。NumPyは多次元配列データを高速に演算することを得意とします。画像データは画素の値が大量に並んだ多次元の配列データとみなせます。画像認識モデルの訓練は膨大な量の画像データが必要ですが、NumPyを用いると比較的早くこれらの画像データを処理できます。Pandasはデータ分析で使用される表形式データを柔軟に処理する機能が揃っています。例えば欠損値の処理に適しています。データ表同士でも様々な統計処理を行う関数を提供しています。
MLOps(開発と運用が同じ担当者である必要はありません)により学習済みモデルを本番環境に展開した運用期間中にもデータを追加して再学習を行なってアップデートや改善を行いやすくなります。DevOpsを機械学習モデルの開発に応用した考えです。AutoMLは機械学習モデルの開発プロセスを自動化する仕組みまたはツールです。
CRISP-DMはデータマイニングの標準プロセスです。ビジネス理解→データ理解→データ準備→手法の選択・モデル作成→結果の評価_プロセスの見直し・次のステップの計画→本番環境への展開です。必要に応じて前のステップに戻る、ステップ間を行き来することがあります。サイクルを複数回実施することもあります。
APIはソフトウェアやアプリケーションの間で機能の一部を共有する技術です。HTTPなどWeb技術を利用したAPIをWeb APIと言います。利用者は、APIのサーバにリクエストを送り、それに対して応答が返ってくることで、プログラムの機能が利用できます。Web APIは無償のものと有償のものがあります。有償であっても、総合的には全ての機能を自前で開発するようりは安価であることが多いです。
アプリケーションの機能は、提供されるAPIの機能や仕様に依存します。APIの機能や仕様が変わるとそれを利用したアプリケーションも修正が必要です。APIのサービス停止やシステム障害の影響も受けます。APIを用いた場合に比べ、自ら実装する方が、柔軟な対応は可能であり、カスタマイズ性は高いです。
PaaSはアプリケーションが稼働するプラットフォームを提供するクラウドサービスです。IaaSの例として、Amazon Web Services(AWS)、Google Cloud、Microsoft Azure、IBM Cloud、Oracle Cloudなどがあります。オンプレミス(自社環境)は、必要な設備の購入やシステム構築と運用管理を全て自社で行う必要がありますが、柔軟性が高いです。最近はクラウドと併用したハイブリッド環境もあります。
ブロックチェーンは分散的に管理されたコンピュータをネットワークに接続し、暗号化された同一データのコピーを全端末で共有します。データを保護しながら取引を行うための有効手段です。ハッシュや電子署名などの暗号技術を用いるのでデータの改竄を監視し検出できるようになっています。デジタル空間でデータが不正に改竄されないように担保することを完全性と言います。ネットワークの一部に不都合が発生しても、システム全体がダウンすることなく運用を継続できることを可用性と言います。
Dockerはアプリケーションとその実行に必要な環境をコンテナという単位でパッケージ化する技術です。この技術をコンテナ型仮想化と言います。OS上でコンテナ(アプリケーションを実行するためのリソースが提供される仮想空間)を構成します。コンテナごとに構築、実行、共有できます。コンテナはOSレベル以上のソフトウェア層のみを仮想化して任意のマシンにデプロイして使用します。仮想マシンはハードウェア層まで含めたマシン全体を仮想化しているので物理マシンのデジタルコピーと解釈されます。独自のOSを備えた複数の仮想マシンが同じホストマシン上で実行されます。
コンテナ型仮想化の場合はOSレベルでの仮想化を行うので1台の物理的なマシン上で複数の仮想的なユーザ空間(コンテナ)を設けることができます。開発プロジェクトごとに異なる仮想環境のコンテナを使い分け、1台のサーバの上で複数のアプリケーションを稼働にすることができます。Dockerのコンテナを利用することで、開発のための環境構築のコストが削減されます。アプリケーションを動かすのに必要な全ての要素が1つのコンテナにまとめられていて、このコンテナをホストマシンにデプロイするだけのためです。アプリケーションを動かす全ての要素はDockerイメージ(コンテナイメージ)としてパッケージ化されます。具体的にはDockerファイルというテキストファイルに記述するだけです。これを任意のマシン(Ubuntuなど)の中で起動して実行します。Docker Hubというレジストリを介して、多くの開発者が自分が作ったアプリケーションのDodkerイメージを他のDockerユーザと共有できます。公開されたDockerイメージを利用すれば、アプリケーションの開発・実行のための仮想環境を、短時間・低コストで構築できます。変更したい部分だけに処理を加えれば良いからです。
分析の目的と明確なKPIについて依頼元と分析担当者で意識の相違がないことが大事です。データの全体が分析の目的やクライアントが知りたいことに関連するとは限らないので、総当たりで分析するのは非効率です。まずは目的に関与するデータから特定すべきです。一般的な教養範囲はなく、案件の要件として発注者と相談し決めるものです。従って先方は何%の予測のずれまでが許容範囲かを確認すべきです。時系列データに対する予測モデルは時間が経つと、実データのトレンドが徐々に変化し、納品当時に精度が検証されたモデルでも精度が少しずつずれ始めるのは珍しくはありません。そのため開発当時の精度検証の経緯に必要以上に固執することは好ましくありません。
データを扱う上で倫理的な行動を取るべきです。AI倫理に関する取り組みの1つは、公平性・説明責任・透明性です。AI倫理の重要項目の1つは、AIシステムが利用者の行動に与える影響を明らかにすることです。表示内容や推奨記事を通して、ユーザの意思表示や判断が影響される可能性があるので、そのことをユーザに伝える必要があります。AIの公平性の観点からデータバイアスやアルゴリズムバイアスを排除する工夫を行う必要があります。
知的財産権のメリットは、資金調達などもあります。知的財産権のうち特許権(産業財産権の一種)は申請などの手続きが必要です。知的財産権は知的創作物(創作意欲の促進を目的とした権利で特許権、著作権)と営業上の標識(使用者の信用維持を目的とした権利で商標権です)キャラクターの絵は著作権法による保護の対象となることがあり、キャラクター名は商標登録によって保護されることがあります。平成30年に不正競争防止法が成立しましたが、営業秘密を保護するため知的財産として認められる必要はありません。会社のサービス名やロゴは商標権の対象です。
職務命令に違反しても従業員の身分や使用者の発明への寄与により職務発明が成立することがあります。学習済みモデルが営業秘密として保護されるために暗号化などによる秘密管理が必要となります。特許出願は要件ではありません。スクレイピングが違反に当たる可能性があります。ウェブサイトに高頻度にアクセスしてサーバに負荷を掛けたり営業を妨害したり、スクレイピングを通して個人情報を取得し、プライバシー・ポリシーや個人情報保護方針に従わなかった場合などです。
ディープフェイクなどコンテンツの生成を目的とするAIは限定的なリスクのAIシステムと区分けされます。日本のSNSにおいてディープフェイクを用いることはfacebookとInstagram(共にメタ社)で禁止されています。日本ではこれを用いて逮捕者が出ています。ディープフェイクを検出できるAIモデルを訓練する研究が行われています。見破るツールはマイクロソフト社のMicrosoft Video Authenticatorが一例です。ただディープフェイクは有益な使い方もありますので完全に禁止することは現実的ではありません。
補填した値を個別に報告することは、データ分析案件では通常しません。ただし、補填後(加工後)の学習用データセットを納品することがあります。データ汚染で行える変更は目視では確認できないくらい微小な物です。画像データの摂動とは、特定の画素に目視では認識できないような微小な変更操作をすることです。データ汚染は人間社会のセキュリティを守るためにも使われます。顔写真の漏洩や悪用によるさまざまな被害を防ぐため、顔画像をウェブに投稿する前にデータ汚染(画像への摂動)でプライバシー保護の加工を行うツールが開発されています。敵対的サンプルは学習済みモデルが誤った出力をするように、特定の入力データを恣意的に加工した物です。具体的には、機械学習モデルを混乱させるような人間の目では識別できない程度の微小なノイズを入力データに付与します。このような攻撃を敵対的攻撃と言います。データ汚染は学習データにノイズを付与し、それを用いてモデルを学習させることで、敵対的攻撃は学習済みモデルにノイズを付与したデータを入力し、誤判断させることが目的です。
AIのブラックボックス問題に対し解消する取り組みとしてXAIの研究開発が進められています。どの特徴量が予測に影響力をもったか、データの場合分けの閾値などを示すことが求められます。システムの裏側で動いているソースコードの可読性はXAIと直接的に関係するとは言えません。特徴量を人間が選択する、特徴量選択の根拠を明確にすることはXAIの必須要件ではありません。構造化データは比較的説明しやすく、画像データの特徴量は人間でなくCNNの中で自動的に抽出します。Grad-CAMのようなモデル解釈ツールを用いることでXAIの仕組みが実現されます。多言語の説明書は現時点ではXAIの要件には含まれません。人間と同じところに注目して推論を行うのでなく、人間が気付きにくい特徴量をわかりやすく可視化することに重要な意味があります。利用者の健康、安全や個人情報に関与するAIではブラックボックス問題は深刻で、XAIの活躍が期待されます。AIの仕組みを説明できるようになると、モデルの設計の観点から予測精度の向上にもつながる可能性があります。人事評価や採用判断、クレジットカードのスコアリングなどの結果は、対象者の生活と健康や安全に顕著な影響を及ぼすことがあります。学習データに偏りがある場合やアルゴリズムバイアスが潜在する場合、AIの判断の公平性が疑問視されます。AIが判断を行っていることを公表しないこと、あるいはAIのアルゴリズムが不透明であることは倫理上、問題があるとみなされます。公平性・説明責任・透明性は国際的にAIの社会実装において留意する基準として認識されています。
GDPRはEUにおける個人データやプライバシー保護に関する規則で、EU域内および域外におけるデータの利活用の促進を目指します。データポータビリティはあるサービスが特定のユーザに関して収集・蓄積した利用履歴などのデータ(個人データ)を他のサービスでも再利用できること、つまり持ち運び可能であることを指します。データポータビリティ権は各サービスのユーザが自身の個人データにアクセスできると共に、その持ち出しや転移を可能にすることです。具体的には次を行使可能です。自身の個人データをその管理者から一定のフォーマット(構造化された、機械により読み取れる形式)で受け取り、他の管理者に転移する権利、自身の個人データを異なる管理者間で直接転移させる権利です。GDPRでは無断でのEU域外への個人データの転移(持ち出し)が禁止されています。持ち出しには越境転移規則というルールをクリアし、煩雑な手続きをする必要があります。一方で欧州委員会から十分性認定を受けている国は、規制が緩和され、当該国の企業は手続き負担が大きく減ります。欧州委員会がデータポータビリティ権を導入した目的は、個人データを扱う事業者間の競争の活性化及び新規サービスの創出を促すことが含まれています。AI技術開発における倫理アセスメントはAIの開発と運用における倫理的リスクを評価し、それらに対する管理と対策を講じることを指しています。目的として、AIが人間にとって有益に使用されること、AIの品質と安全性を高め、AIに対する信頼性を高めることが挙げられます。所得格差をなくすことがAIの倫理アセスメントの目的ではありません。データ及びAIモデルからバイアスを検出し修正することが重要です。システムを介して入力・出力されるデータの保護、安全なAIの設計を担保することに取り組む必要があります。
ソフトローはガイドライン、自主規制、推奨事項、努力義務などです。AI倫理原則はソフトローです。日本や米国はソフトロー、欧州や中国はハードローを採用する傾向にあります。欧州のAI規制法はOpenAI社をはじめとした企業に、大規模言語モデルの学習に使用されたデータの開示を義務付けています。中国の生成人工知能サービス管理暫定弁法は、生成AI関連のソリューションを提供する際に、生成AIアルゴリズムなどを利用に関する明示と国への届出を義務付けています。違反した場合は罰金です。GDPRはハードローです。企業の従業員として何らかの義務を持って従う規範だけではハードローに該当するとは言えません。ソフトローに該当します。ハードローは法的な拘束力、強制力を持つことで判断します。倫理ガイドライン自体に法的拘束力がなくても、注意喚起されている内容に反した行動により、国によって義務付けられているハードローの違反に該当することがあります。日本でAIガバナンスの注目が高まり経済産業省が2021年7月9日に我が国のAIガバナンスの在り方ver1.1を発表しています。イノベーションを阻害する要因になるような統制を積極的に推進すべきとは言えません。人間の修正は禁じられていません。倫理的な問題は企画や設計などのあらゆる段階で重視すべきです。ソフトローには刑罰の有無を問わず、社会の一員として守るのが当然という意識が求められます。GDPRに記述されている忘れられる権利について、問題のあるデータ(誤認識につながるものやプライバシー的に問題のあるもの)の影響を、モデルの再訓練をすることなく、学習済みモデルから排除する技術「マシンアンラーニング」が注目されています。ターゲティング広告を制限する規則があります。利用者の個人データを政治広告に使うには、利用者自身が自分のデータが使われることを明示的に、個別に同意している場合にのみ限られます。プロファイリングで人種や民族、出身地、政治的志向などのよう配慮個人情報を使用することは全面的に禁止されています。プロファイリングとは、いくつかの種類の個人データを組み合わせてターゲティング広告の配信先を絞る行為です。
AI規制法は、世界初のAIを包括的に帰省する法案です。EU域内で適用されます。リスクベース・アプローチを採用しています。許容できないリスク→ハイリスク→限定リスク→最小リスクとリスクが小さくなります。許容できないリスクに分類されるAIは人間の安全や権利に明確に脅威となるもので使用は禁止されます。医療AIはハイリスクです。公衆の安全、健康、人権などに顕著な影響を及ぼす可能性のあるAIが属します。使用は禁止されないものの厳格な規制が適用されます。AIを用いて人の信用力を格付けするソーシャルスコアリングを行い、特定の人や属するグループに不利益をもたらす技術が許容できないリスクに該当します。犯罪捜査のために法執行機関(国家)がAI顔認証などの生体識別システムを使用する場合が許容できないリスクです。テロ脅威の防止など厳密に定義された条件を満たした場合は、例外的にAI顔認証の利用が認められます。サブリミナルな技術を用いて特定の弱みに漬け込むことで対象者の行動を歪め、身体的、心理的な影響を与える可能性のあるAIシステムなどは基本的な権利を侵害するため許容できないリスクになります。ただしリスクベース・アプローチにも課題があります。国によってリスクの度合いが異なるためです。ハイリスクAIは人間の生命・身体の安全確保が大前提となる機械類や乗り物が対象です。自動運転技術がこの区分にあり、EUにおいてはハイリスクAIに該当する可能性があります。ディープフェイクは限定リスクです。個人に対して直接的な危険はもたらされない技術です。チャットボット、感情認識システム、オンライン広告配信などがあります。AIを活用したスパムフィルタやビデオゲームは最小リスクです。この区分のAIは自由に利用することが認められています。限定リスクの場合はサービス提供時にユーザに対してAIを使用していることを知らせる必要があります。レコメンドシステムも限定リスクです。一般的な遠隔生体認証システムはハイリスクです。許容できないリスクに分類されるのは、犯罪捜査のために法執行機関(国家)がAI顔認証などの生体識別システムを使用する場合です。
AI戦略会議は内閣府などによって立ち上げられ、行動指針案を整備してきました。この会議においてAI事業者ガイドライン案が提出され、2024年1月に公表されました。あらゆる組織が対象で、AIの開発、提供、利用の各場面において必要な取り組みついて基本的な考えを示すもので、強制力を伴う法令ではありません。それまでも2019年3月に策定された人間中心のAI社会原則を中心に議論は行われてきました。これらはソフトローです。AI事業者ガイドライン案をハードローにすべきという声もありますが、時間がかかりそうな意見が一般的です。本ガイドラインの目的はAIのリスク管理に加えて、イノベーションの創出促進もあります。
デジタルプラットフォームは、インタネットを通じて事業者に提供される、電子商取引や情報配信などのための利用基盤や利用環境として定義されます。デジタル技術やデータ等を用いてシステムやサービスを提供する事業者を指します。監視アルゴリズムは事業者間の協調的行為で、不当な取引制限として独占禁止法で禁止されています。検索順位アルゴリズムを設定し、特定の事業者の表示順位を変えることは違反となる可能性があります。実際に、民事裁判になった例があります。個人情報などを少数の事業者が独占することをデータ寡占といいます。これは私的独占の一部である排除に該当します。パラレルアルゴリズムは合意に従って価格をつけるように設定されたアルゴリズムを当該事業者で共有して利用することです。不当な取引制限に該当し、独占禁止法で禁止されます。商品価格は本来、各事業者が自主的に設定します。相互に連絡を取り合って取り決める行為はカルテルに該当します。企業努力によって自然に市場を独占した場合は独占禁止法に該当しません。デジタルカルテルには関しアルゴリズム、パラレルアルゴリズム、シグナリング・アルゴリズム、自己学習型アルゴリズムがあり、前半2つは独占禁止法で禁止されています。事業者が自社の商品の価格設定のためにAIアルゴリズムを使用することは独占禁止法上問題ではありません。他の競争事業者との合意や共有がないため、カルテルやパラレルアルゴリズムとは異なる性質です。値上げのシグナリング(事前告知など何らかの方法で値上げすることを仄めかす)を行い、他の事業者の反応を伺うため、AIアルゴリズムを単独で使用しても、他の事業者との間に合甥がない限り、不当な取引制限に該当せず、独占禁止法違反にはなりません。
フィルターバブル現象はレコメンドのアルゴリズムによる嗜好の分析に基づくパーソナライズが強すぎて、ユーザにとって有益な情報ばかりが優先され、その他の情報から隔離された状態に陥ってしまうことで、エコーチェンバーはSNSを利用する際に自分と興味関心が似ているユーザをフォローすることにより、SNS上で意見を投稿すると、自分と似たような意見ばっかり返ってくる現象です。エコーチェンバーの問題は2021年のアメリカ合衆国の議会乱入事件が有名です。これらを防ぐには、こういった現象を疑い、積極的に幅広い情報や自分と異なる意見に目を向け、履歴の残らないシークレットブラウザで検索を行うことが大事です。フィルターバブルはAIの問題で、エコーチェンバーは人間の問題です。
人間の知識労働の多くがAIで代替されることが予想されるので、知識労働者のスキル喪失や大量失業が社会問題として議論されます。事務系の仕事はLLMに、イラストレーターの仕事はCNNに、受付サービスや案内サービスなどの言語的コミュニケーションに基づく定型的な仕事は、対話型AIが代替します。AIは記憶力、論理的思考、知識の活用については、人間を超えています。弁護士や会計士も含め、これらを主要とする職業は大部分がAIに代えられていきます。対策としては、AIに代替されにくい能力を磨くことが大事です。直感的な判断能力、共感力、感受性、組織マネジメント力などです。
LAWSはキラーロボットとも呼ばれます。日本政府は開発はしないと宣言しますが、人の意思が介在する自立型兵器の研究開発は規制すべきでない立場です。JAICはアメリカ国防省の人工知能の研究開発を行うジョイントAIセンターで、そこでAIの軍事利用に関する研究が行われています。2018年以降、国連のグテーレス国連事務総長はLAWSは国際法で禁止すべきと訴えました。テロ組織などが入手すると脅威となります。この時に、3Dプリンター、バイオテクノロジー、顔認証など最先端のIT技術の軍事利用の規制についても議論されました。LAWSまでは至りませんが、米国や中国やロシアなどでAIの軍事利用の開発が進められています。実際の利用には合意しない姿勢です。民間企業でAIの軍事利用の反対運動が活発化しています。Googleはドローン兵器に利用するためのProject Mavenを進めていましたが、反対の声が上がり、契約は2019年に打ち切りになりました。Ai at Google :our principlesを発表し、AIを兵器のために開発しないというAIの平和利用宣言をしました。
AI倫理の文脈におけるインクルージョンとは、人の属性によって差別を受けることなく、誰もがAIによる利益が平等に広く享受されるべきである考え方です。AI分野におけるデジタルデバイドをなくすこととも解釈できます。幅広い視点を取り入れて様々な人々のニーズに対応した技術を目指します。
ChatGPTに秘密情報を入力した際に情報の保護は保証されるとは限りません。OpneAI社などの管理者がアクセス可能なためです。API経由での利用の場合は入力した情報をモデルの学習に利用しないとしています。UIから利用した場合。プロンプトを通じて提供されたデータがChatGPTモデルを改善(チューニング)するために使用されることがあるとされています。ただしオプトアウトの制度があり、それによってモデル学習への利用を回避できます。社会に有害な用途を禁止しています犯罪行為の助長があげられます。誤った情報の提供につながるコンテンツを生成し、配布することも禁止事項です。専門家でない人が高リスクでセンシティブな分野において、他人を誘導するためのアドバイスをAIに生成させて配布することは禁止です。これらはOpenAIやGoogleなどの利用規約にあります。APIでない場合に情報漏洩を抑えるために、ソースコードの中の営業秘密を含む部分をダミーの情報で置き換えてからエラーの要因をAIに見つけてもらう、ソースコードを実行した際に出たエラーメッセージのみAIに入力し、そのエラーの意味と解決策を提案してもらう、ソースコードで達成したい機能を文章で与え、AIにサンプルコードを書いてもらうなどです。著作物となりうる画像をAI学習に用いることは日本の著作権法の例外規定により、一定条件を満たせば行為自体は法に触れません。ただし、使い方によっては元の作品の著作者の権利を侵害する可能性があります。
AI倫理・AIガバナンス
以下、黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の該当章の大事なポイントの復習です。
人間中心のAI社会原則に、AI ~Readyな社会は基本理念に含まれません。AIガバナンスの設計について、リスクベースアプローチがあります。規制の程度をリスクの大きさに対応させるべきという考えです。ハードローは国家などで明確に規定された法律による規制です。ソフトローは私的な取り決めなどによる自主的な規制です。
カメラ画像を利活用する際に注意すべきことは、カメラ画像利活用ガイドブックとして公表されています。個人情報に当たらない場合は後ろ姿だけなどその画像データから個人を特定できない状態です。取得した画像データを加工した場合でも特定の個人を特定できる場合は個人識別符号と見なされ、個人情報に該当します。個人情報の利用目的を公表しているなど、一定の条件を満たす場合は、個人情報を使用してAI学習を行うことは可能です。学習済みモデルを使用して、カメラからの入力データに対して予測を行う際も、プライバシーの問題が発生することがあります。
センシティブ情報を説明できるような何らかの変数が特徴量に紛れ込むことで、公平性に問題が生じることがあります。このような変数を代理変数と言います。潜在変数は画像生成などに利用されるVAEに用いられる概念です。セキュリティ・バイ・デザインは企画設定段階から念頭に置く設計思想です。同様に、プライバシー・バイ・デザインも規格設計の段階からプライバシー侵害予防を指向する概念です。
機械学習モデルの予測を意図的に誤らせる目的で作られた入力データをAdversarial Example(敵対的サンプル)といい、利用攻撃をAdversarial Attackと言います。データ窃取は学習済みモデルにデータ入力を行い、その出力を観察してモデルの学習データを推測する攻撃です。モデル窃取は学習済みモデルにデータ入力を行い出力を観察してモデルのパラメータを推測する攻撃です。データ汚染は学習データに不適切なデータを混入させモデルに誤った学習をさせる攻撃です。モデル汚染は攻撃者が細工した事前学習済みモデルを配布して利用させることにより、モデルの出力を操作したり、悪意あるプログラムを実行させたりする攻撃です。
AI利活用における透明性を確保するために、説明可能性(ブラックボックスであるためXAIの技術を利用)を確保することは大事です。XAIの技術としてSHAPやCAMなどの手法があります。AI倫理に対する指針をまとめた文書をAIポリシーと言います。これを公表することで透明性の確保につながります。学習データの取得方法や加工方法などのデータ来歴を公表することも透明性確保のために大事です。
フィルタバブルとはアルゴリズムがユーザーの行動履歴を分析または学習し、ユーザーの価値観に沿う情報のみを優先的に表示することで、ユーザーが自身の価値観の中に孤立してしまう情報環境のことです。他にはエコーチャンバーがあります。これはソーシャルメディアなどを利用する際に、ユーザーが意見を発信すると同じような思考を持つ人からの意見が集まる状況を、閉鎖空間で音が反響する物理現象に例えたものです。
巨大ネットワークはGPUやTPUといった計算リソースを大量に使用するので、消費電力も大きくなり、気候変動など環境へ影響が懸念されています。TPUはGPUより低コストで学習できることがわかっています。QPUは量子コンピュータで使用される演算処理装置です。APIはシステム間で情報の受け渡しを行うインターフェイスです。
AIの利活用によって、AIによって仕事を代替することで労働不足の解消が期待されます。AIによって自動化された場合でも、人間の免許制度は必要かなどといったことが議論になります。多くの場合にAIの出力をモニタリングしたり、最終的な意思決定に人間が関与するなどの運用が必要になります。
パブリシティ権について、故人のパブリシティ権やプライバシー侵害がないことや、故人に対する一般的な宗教的崇敬感情にも配慮が必要です。
AIの軍事利用について自立型無人機の研究開発はLAWS(自立型致死兵器システム)の開発へ発展するのではと危惧されています。特定通常兵器使用金制限条約CCW(Convention on Certain Conventional Weapons)の枠組みで、そのあり方を国際的に議論しています。倫理的。法的・社会的な課題(ELSI)の試みも大事です。
倫理的なAIを開発するには追跡可能性や監査可能性(トレーサビリティ)、ダイバーシティ、インクルージョンなどへの配慮も大事です。AIに倫理上の問題がないかを行うアセスメントをAI倫理アセスメントと言います。AIの予測について同じ入力に対して同じ出力が得られることを再現性と言います。
以上で全て終了です!G検定は出題範囲が広くて大変ですが、しっかりと知識のインプットとアウトプットの両立を頑張りましょう!管理人は2025年3月8日の試験で無事に合格することができました!
G検定はインプットのみでは漠然とした理解になりやすいので、合格のためにはアウトプット用の教材が必須です。特に法律系の内容は出題数もそこそこある上で受験者にとって失点の原因になる範囲です。僕はこの分野を『ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト』を用いて理解確認を行います。全体のアウトプットは有名な黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』と類書『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いて得点力の底上げを行います。

{kind=link}